diff --git a/modules/deepface-master/Dockerfile b/modules/deepface-master/Dockerfile
new file mode 100644
index 000000000..911df26df
--- /dev/null
+++ b/modules/deepface-master/Dockerfile
@@ -0,0 +1,54 @@
+# base image
+FROM python:3.8
+LABEL org.opencontainers.image.source https://github.com/serengil/deepface
+
+# -----------------------------------
+# create required folder
+RUN mkdir /app
+RUN mkdir /app/deepface
+
+# -----------------------------------
+# switch to application directory
+WORKDIR /app
+
+# -----------------------------------
+# update image os
+RUN apt-get update
+RUN apt-get install ffmpeg libsm6 libxext6 -y
+
+# -----------------------------------
+# Copy required files from repo into image
+COPY ./deepface /app/deepface
+COPY ./api/app.py /app/
+COPY ./api/api.py /app/
+COPY ./api/routes.py /app/
+COPY ./api/service.py /app/
+COPY ./requirements.txt /app/
+COPY ./setup.py /app/
+COPY ./README.md /app/
+
+# -----------------------------------
+# if you plan to use a GPU, you should install the 'tensorflow-gpu' package
+# RUN pip install --trusted-host pypi.org --trusted-host pypi.python.org --trusted-host=files.pythonhosted.org tensorflow-gpu
+
+# -----------------------------------
+# install deepface from pypi release (might be out-of-date)
+# RUN pip install --trusted-host pypi.org --trusted-host pypi.python.org --trusted-host=files.pythonhosted.org deepface
+# -----------------------------------
+# install deepface from source code (always up-to-date)
+RUN pip install --trusted-host pypi.org --trusted-host pypi.python.org --trusted-host=files.pythonhosted.org -e .
+
+# -----------------------------------
+# some packages are optional in deepface. activate if your task depends on one.
+# RUN pip install --trusted-host pypi.org --trusted-host pypi.python.org --trusted-host=files.pythonhosted.org cmake==3.24.1.1
+# RUN pip install --trusted-host pypi.org --trusted-host pypi.python.org --trusted-host=files.pythonhosted.org dlib==19.20.0
+# RUN pip install --trusted-host pypi.org --trusted-host pypi.python.org --trusted-host=files.pythonhosted.org lightgbm==2.3.1
+
+# -----------------------------------
+# environment variables
+ENV PYTHONUNBUFFERED=1
+
+# -----------------------------------
+# run the app (re-configure port if necessary)
+EXPOSE 5000
+CMD ["gunicorn", "--workers=1", "--timeout=3600", "--bind=0.0.0.0:5000", "app:create_app()"]
diff --git a/modules/deepface-master/LICENSE b/modules/deepface-master/LICENSE
new file mode 100644
index 000000000..2b0f9fbb7
--- /dev/null
+++ b/modules/deepface-master/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2019 Sefik Ilkin Serengil
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/modules/deepface-master/Makefile b/modules/deepface-master/Makefile
new file mode 100644
index 000000000..af58c7f7d
--- /dev/null
+++ b/modules/deepface-master/Makefile
@@ -0,0 +1,5 @@
+test:
+ cd tests && python -m pytest . -s --disable-warnings
+
+lint:
+ python -m pylint deepface/ --fail-under=10
\ No newline at end of file
diff --git a/modules/deepface-master/README.md b/modules/deepface-master/README.md
new file mode 100644
index 000000000..a4549c3f0
--- /dev/null
+++ b/modules/deepface-master/README.md
@@ -0,0 +1,375 @@
+# deepface
+
+
+
+[](https://pepy.tech/project/deepface)
+[](https://anaconda.org/conda-forge/deepface)
+[](https://github.com/serengil/deepface/stargazers)
+[](https://github.com/serengil/deepface/blob/master/LICENSE)
+[](https://github.com/serengil/deepface/actions/workflows/tests.yml)
+
+[](https://sefiks.com)
+[](https://www.youtube.com/@sefiks?sub_confirmation=1)
+[](https://twitter.com/intent/user?screen_name=serengil)
+[](https://www.patreon.com/serengil?repo=deepface)
+[](https://github.com/sponsors/serengil)
+
+[](https://doi.org/10.1109/ASYU50717.2020.9259802)
+[](https://doi.org/10.1109/ICEET53442.2021.9659697)
+
+
+
+
+
+Deepface is a lightweight [face recognition](https://sefiks.com/2018/08/06/deep-face-recognition-with-keras/) and facial attribute analysis ([age](https://sefiks.com/2019/02/13/apparent-age-and-gender-prediction-in-keras/), [gender](https://sefiks.com/2019/02/13/apparent-age-and-gender-prediction-in-keras/), [emotion](https://sefiks.com/2018/01/01/facial-expression-recognition-with-keras/) and [race](https://sefiks.com/2019/11/11/race-and-ethnicity-prediction-in-keras/)) framework for python. It is a hybrid face recognition framework wrapping **state-of-the-art** models: [`VGG-Face`](https://sefiks.com/2018/08/06/deep-face-recognition-with-keras/), [`Google FaceNet`](https://sefiks.com/2018/09/03/face-recognition-with-facenet-in-keras/), [`OpenFace`](https://sefiks.com/2019/07/21/face-recognition-with-openface-in-keras/), [`Facebook DeepFace`](https://sefiks.com/2020/02/17/face-recognition-with-facebook-deepface-in-keras/), [`DeepID`](https://sefiks.com/2020/06/16/face-recognition-with-deepid-in-keras/), [`ArcFace`](https://sefiks.com/2020/12/14/deep-face-recognition-with-arcface-in-keras-and-python/), [`Dlib`](https://sefiks.com/2020/07/11/face-recognition-with-dlib-in-python/) and `SFace`.
+
+Experiments show that human beings have 97.53% accuracy on facial recognition tasks whereas those models already reached and passed that accuracy level.
+
+## Installation [](https://pypi.org/project/deepface/) [](https://anaconda.org/conda-forge/deepface)
+
+The easiest way to install deepface is to download it from [`PyPI`](https://pypi.org/project/deepface/). It's going to install the library itself and its prerequisites as well.
+
+```shell
+$ pip install deepface
+```
+
+Secondly, DeepFace is also available at [`Conda`](https://anaconda.org/conda-forge/deepface). You can alternatively install the package via conda.
+
+```shell
+$ conda install -c conda-forge deepface
+```
+
+Thirdly, you can install deepface from its source code.
+
+```shell
+$ git clone https://github.com/serengil/deepface.git
+$ cd deepface
+$ pip install -e .
+```
+
+Then you will be able to import the library and use its functionalities.
+
+```python
+from deepface import DeepFace
+```
+
+**Facial Recognition** - [`Demo`](https://youtu.be/WnUVYQP4h44)
+
+A modern [**face recognition pipeline**](https://sefiks.com/2020/05/01/a-gentle-introduction-to-face-recognition-in-deep-learning/) consists of 5 common stages: [detect](https://sefiks.com/2020/08/25/deep-face-detection-with-opencv-in-python/), [align](https://sefiks.com/2020/02/23/face-alignment-for-face-recognition-in-python-within-opencv/), [normalize](https://sefiks.com/2020/11/20/facial-landmarks-for-face-recognition-with-dlib/), [represent](https://sefiks.com/2018/08/06/deep-face-recognition-with-keras/) and [verify](https://sefiks.com/2020/05/22/fine-tuning-the-threshold-in-face-recognition/). While Deepface handles all these common stages in the background, you don’t need to acquire in-depth knowledge about all the processes behind it. You can just call its verification, find or analysis function with a single line of code.
+
+**Face Verification** - [`Demo`](https://youtu.be/KRCvkNCOphE)
+
+This function verifies face pairs as same person or different persons. It expects exact image paths as inputs. Passing numpy or base64 encoded images is also welcome. Then, it is going to return a dictionary and you should check just its verified key.
+
+```python
+result = DeepFace.verify(img1_path = "img1.jpg", img2_path = "img2.jpg")
+```
+
+
+
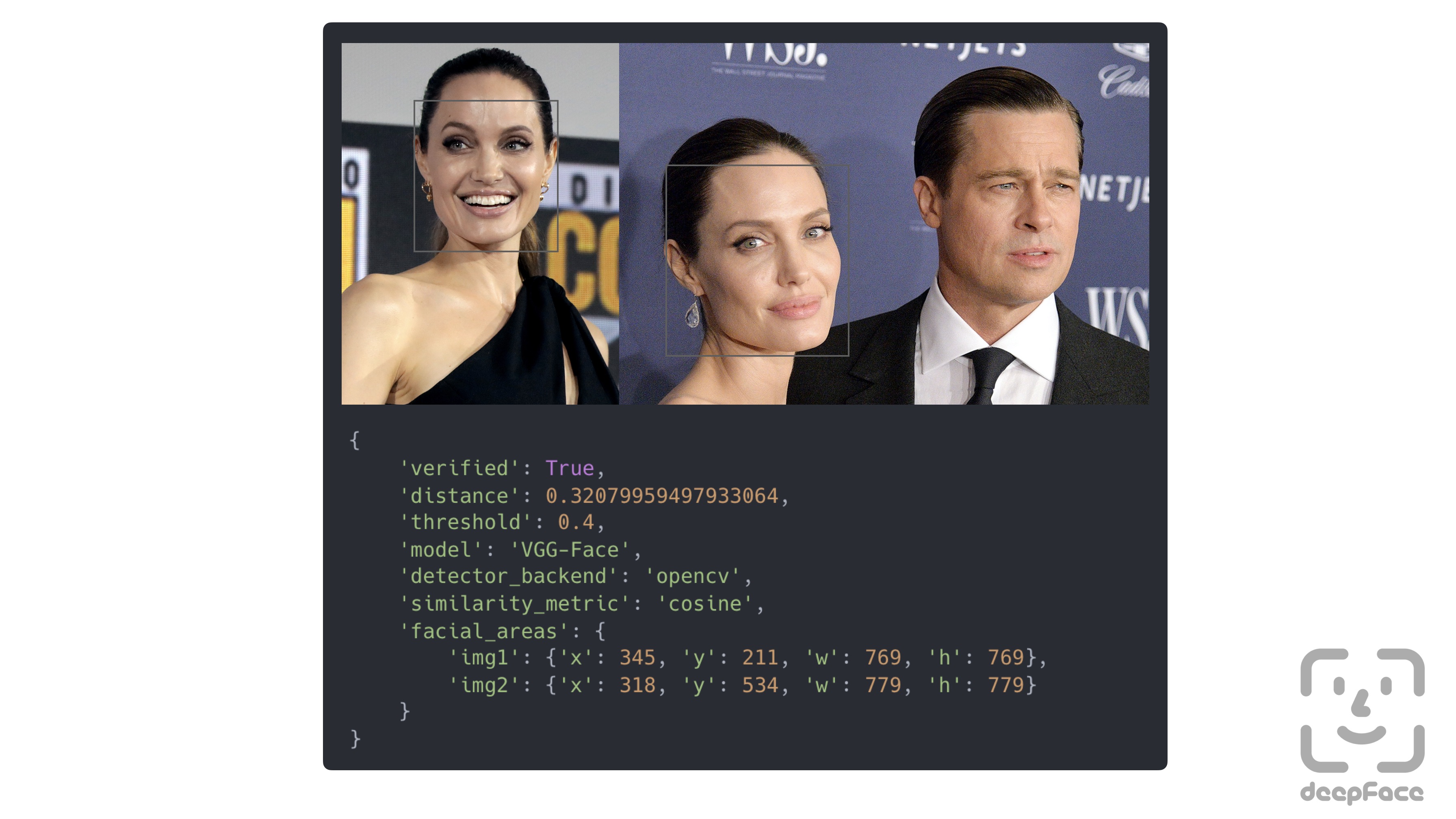
+Verification function can also handle many faces in the face pairs. In this case, the most similar faces will be compared.
+
+
+
+**Face recognition** - [`Demo`](https://youtu.be/Hrjp-EStM_s)
+
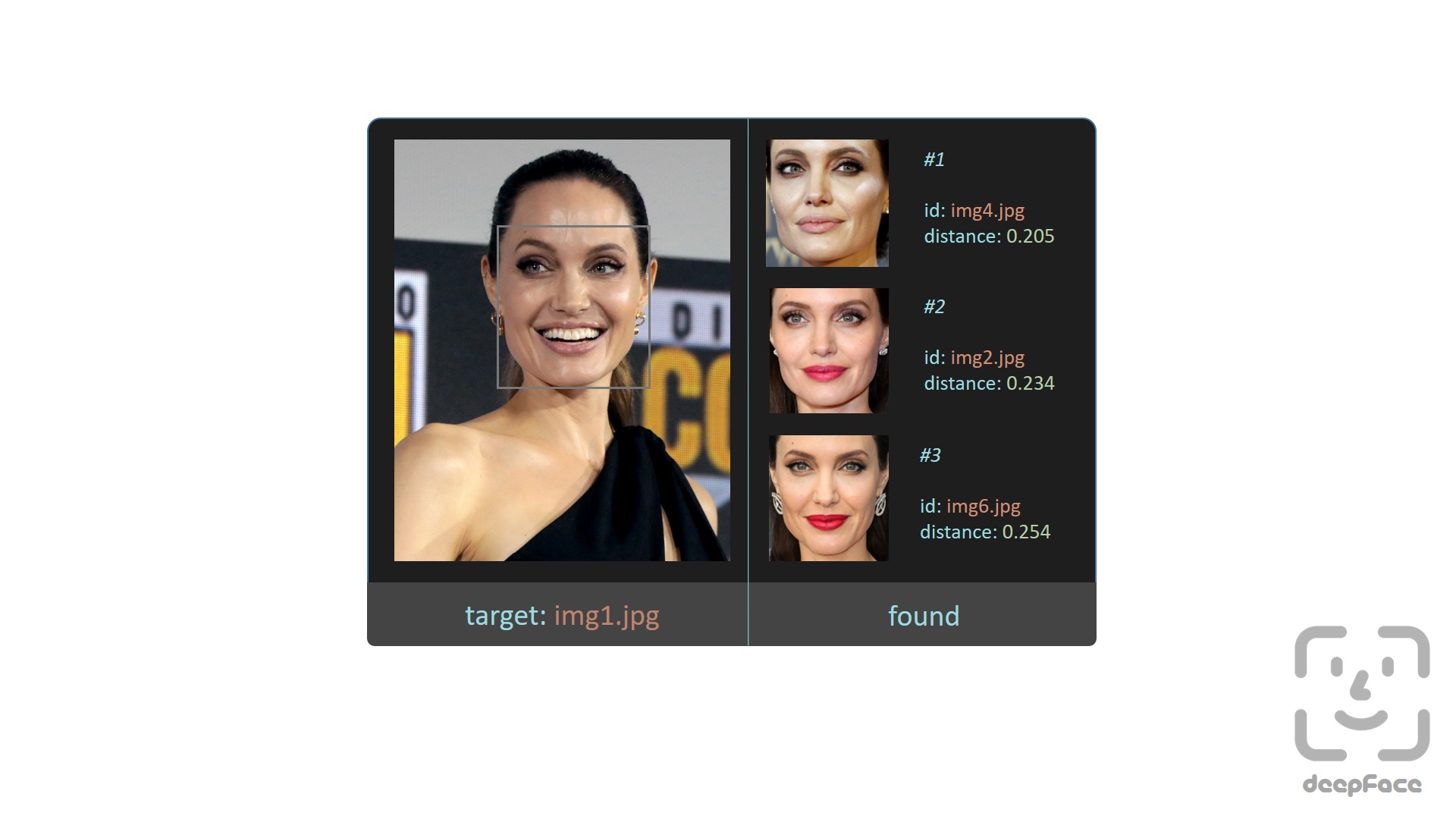
+[Face recognition](https://sefiks.com/2020/05/25/large-scale-face-recognition-for-deep-learning/) requires applying face verification many times. Herein, deepface has an out-of-the-box find function to handle this action. It's going to look for the identity of input image in the database path and it will return list of pandas data frame as output. Meanwhile, facial embeddings of the facial database are stored in a pickle file to be searched faster in next time. Result is going to be the size of faces appearing in the source image. Besides, target images in the database can have many faces as well.
+
+
+```python
+dfs = DeepFace.find(img_path = "img1.jpg", db_path = "C:/workspace/my_db")
+```
+
+
+
+**Embeddings**
+
+Face recognition models basically represent facial images as multi-dimensional vectors. Sometimes, you need those embedding vectors directly. DeepFace comes with a dedicated representation function. Represent function returns a list of embeddings. Result is going to be the size of faces appearing in the image path.
+
+```python
+embedding_objs = DeepFace.represent(img_path = "img.jpg")
+```
+
+This function returns an array as embedding. The size of the embedding array would be different based on the model name. For instance, VGG-Face is the default model and it represents facial images as 4096 dimensional vectors.
+
+```python
+embedding = embedding_objs[0]["embedding"]
+assert isinstance(embedding, list)
+assert model_name = "VGG-Face" and len(embedding) == 4096
+```
+
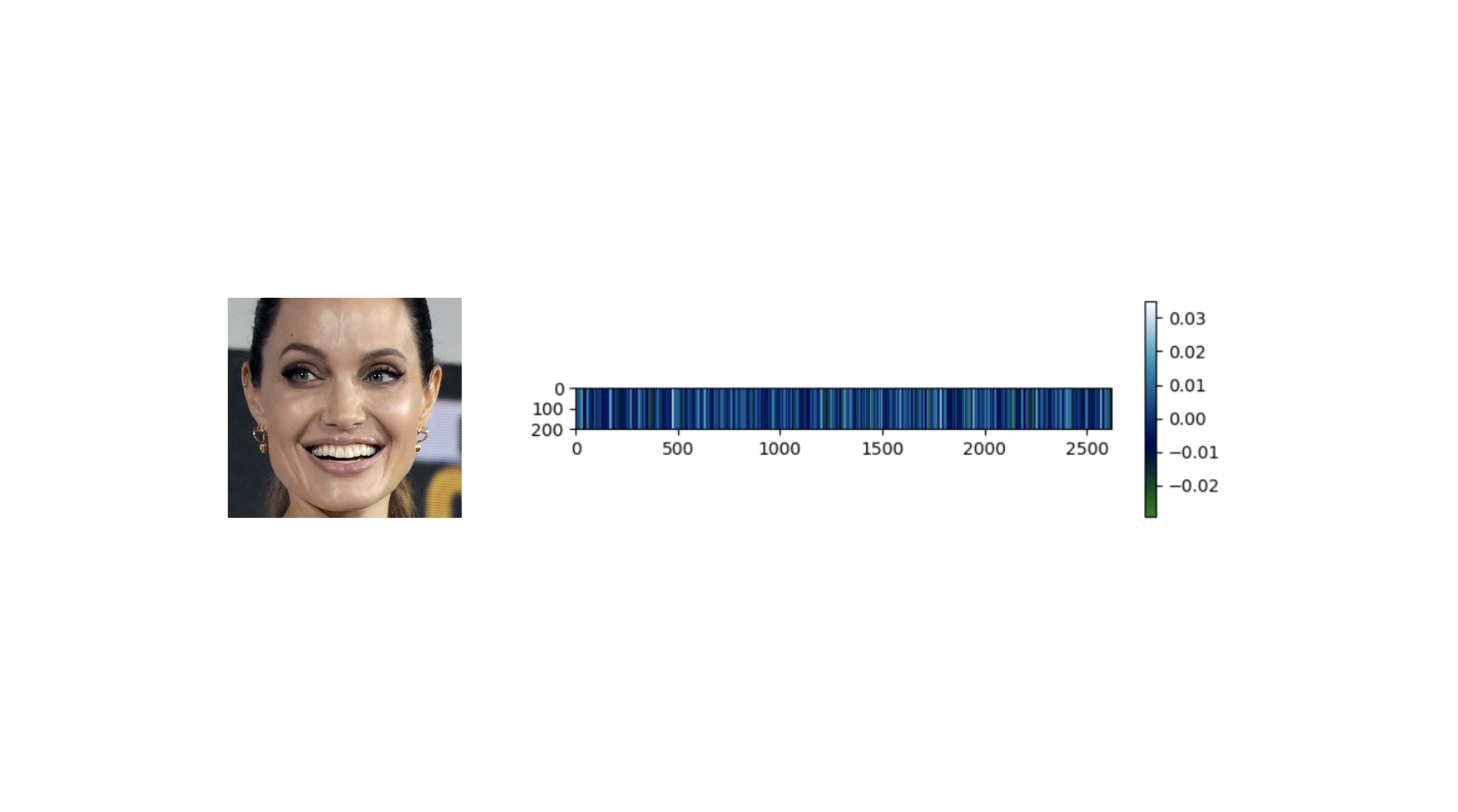
+Here, embedding is also [plotted](https://sefiks.com/2020/05/01/a-gentle-introduction-to-face-recognition-in-deep-learning/) with 4096 slots horizontally. Each slot is corresponding to a dimension value in the embedding vector and dimension value is explained in the colorbar on the right. Similar to 2D barcodes, vertical dimension stores no information in the illustration.
+
+
+
+**Face recognition models** - [`Demo`](https://youtu.be/i_MOwvhbLdI)
+
+Deepface is a **hybrid** face recognition package. It currently wraps many **state-of-the-art** face recognition models: [`VGG-Face`](https://sefiks.com/2018/08/06/deep-face-recognition-with-keras/) , [`Google FaceNet`](https://sefiks.com/2018/09/03/face-recognition-with-facenet-in-keras/), [`OpenFace`](https://sefiks.com/2019/07/21/face-recognition-with-openface-in-keras/), [`Facebook DeepFace`](https://sefiks.com/2020/02/17/face-recognition-with-facebook-deepface-in-keras/), [`DeepID`](https://sefiks.com/2020/06/16/face-recognition-with-deepid-in-keras/), [`ArcFace`](https://sefiks.com/2020/12/14/deep-face-recognition-with-arcface-in-keras-and-python/), [`Dlib`](https://sefiks.com/2020/07/11/face-recognition-with-dlib-in-python/) and `SFace`. The default configuration uses VGG-Face model.
+
+```python
+models = [
+ "VGG-Face",
+ "Facenet",
+ "Facenet512",
+ "OpenFace",
+ "DeepFace",
+ "DeepID",
+ "ArcFace",
+ "Dlib",
+ "SFace",
+]
+
+#face verification
+result = DeepFace.verify(img1_path = "img1.jpg",
+ img2_path = "img2.jpg",
+ model_name = models[0]
+)
+
+#face recognition
+dfs = DeepFace.find(img_path = "img1.jpg",
+ db_path = "C:/workspace/my_db",
+ model_name = models[1]
+)
+
+#embeddings
+embedding_objs = DeepFace.represent(img_path = "img.jpg",
+ model_name = models[2]
+)
+```
+
+
+
+FaceNet, VGG-Face, ArcFace and Dlib are [overperforming](https://youtu.be/i_MOwvhbLdI) ones based on experiments. You can find out the scores of those models below on both [Labeled Faces in the Wild](https://sefiks.com/2020/08/27/labeled-faces-in-the-wild-for-face-recognition/) and YouTube Faces in the Wild data sets declared by its creators.
+
+| Model | LFW Score | YTF Score |
+| --- | --- | --- |
+| Facenet512 | 99.65% | - |
+| SFace | 99.60% | - |
+| ArcFace | 99.41% | - |
+| Dlib | 99.38 % | - |
+| Facenet | 99.20% | - |
+| VGG-Face | 98.78% | 97.40% |
+| *Human-beings* | *97.53%* | - |
+| OpenFace | 93.80% | - |
+| DeepID | - | 97.05% |
+
+**Similarity**
+
+Face recognition models are regular [convolutional neural networks](https://sefiks.com/2018/03/23/convolutional-autoencoder-clustering-images-with-neural-networks/) and they are responsible to represent faces as vectors. We expect that a face pair of same person should be [more similar](https://sefiks.com/2020/05/22/fine-tuning-the-threshold-in-face-recognition/) than a face pair of different persons.
+
+Similarity could be calculated by different metrics such as [Cosine Similarity](https://sefiks.com/2018/08/13/cosine-similarity-in-machine-learning/), Euclidean Distance and L2 form. The default configuration uses cosine similarity.
+
+```python
+metrics = ["cosine", "euclidean", "euclidean_l2"]
+
+#face verification
+result = DeepFace.verify(img1_path = "img1.jpg",
+ img2_path = "img2.jpg",
+ distance_metric = metrics[1]
+)
+
+#face recognition
+dfs = DeepFace.find(img_path = "img1.jpg",
+ db_path = "C:/workspace/my_db",
+ distance_metric = metrics[2]
+)
+```
+
+Euclidean L2 form [seems](https://youtu.be/i_MOwvhbLdI) to be more stable than cosine and regular Euclidean distance based on experiments.
+
+**Facial Attribute Analysis** - [`Demo`](https://youtu.be/GT2UeN85BdA)
+
+Deepface also comes with a strong facial attribute analysis module including [`age`](https://sefiks.com/2019/02/13/apparent-age-and-gender-prediction-in-keras/), [`gender`](https://sefiks.com/2019/02/13/apparent-age-and-gender-prediction-in-keras/), [`facial expression`](https://sefiks.com/2018/01/01/facial-expression-recognition-with-keras/) (including angry, fear, neutral, sad, disgust, happy and surprise) and [`race`](https://sefiks.com/2019/11/11/race-and-ethnicity-prediction-in-keras/) (including asian, white, middle eastern, indian, latino and black) predictions. Result is going to be the size of faces appearing in the source image.
+
+```python
+objs = DeepFace.analyze(img_path = "img4.jpg",
+ actions = ['age', 'gender', 'race', 'emotion']
+)
+```
+
+
+
+Age model got ± 4.65 MAE; gender model got 97.44% accuracy, 96.29% precision and 95.05% recall as mentioned in its [tutorial](https://sefiks.com/2019/02/13/apparent-age-and-gender-prediction-in-keras/).
+
+
+**Face Detectors** - [`Demo`](https://youtu.be/GZ2p2hj2H5k)
+
+Face detection and alignment are important early stages of a modern face recognition pipeline. Experiments show that just alignment increases the face recognition accuracy almost 1%. [`OpenCV`](https://sefiks.com/2020/02/23/face-alignment-for-face-recognition-in-python-within-opencv/), [`SSD`](https://sefiks.com/2020/08/25/deep-face-detection-with-opencv-in-python/), [`Dlib`](https://sefiks.com/2020/07/11/face-recognition-with-dlib-in-python/), [`MTCNN`](https://sefiks.com/2020/09/09/deep-face-detection-with-mtcnn-in-python/), [`Faster MTCNN`](https://github.com/timesler/facenet-pytorch), [`RetinaFace`](https://sefiks.com/2021/04/27/deep-face-detection-with-retinaface-in-python/), [`MediaPipe`](https://sefiks.com/2022/01/14/deep-face-detection-with-mediapipe/), [`YOLOv8 Face`](https://github.com/derronqi/yolov8-face) and [`YuNet`](https://github.com/ShiqiYu/libfacedetection) detectors are wrapped in deepface.
+
+
+
+All deepface functions accept an optional detector backend input argument. You can switch among those detectors with this argument. OpenCV is the default detector.
+
+```python
+backends = [
+ 'opencv',
+ 'ssd',
+ 'dlib',
+ 'mtcnn',
+ 'retinaface',
+ 'mediapipe',
+ 'yolov8',
+ 'yunet',
+ 'fastmtcnn',
+]
+
+#face verification
+obj = DeepFace.verify(img1_path = "img1.jpg",
+ img2_path = "img2.jpg",
+ detector_backend = backends[0]
+)
+
+#face recognition
+dfs = DeepFace.find(img_path = "img.jpg",
+ db_path = "my_db",
+ detector_backend = backends[1]
+)
+
+#embeddings
+embedding_objs = DeepFace.represent(img_path = "img.jpg",
+ detector_backend = backends[2]
+)
+
+#facial analysis
+demographies = DeepFace.analyze(img_path = "img4.jpg",
+ detector_backend = backends[3]
+)
+
+#face detection and alignment
+face_objs = DeepFace.extract_faces(img_path = "img.jpg",
+ target_size = (224, 224),
+ detector_backend = backends[4]
+)
+```
+
+Face recognition models are actually CNN models and they expect standard sized inputs. So, resizing is required before representation. To avoid deformation, deepface adds black padding pixels according to the target size argument after detection and alignment.
+
+
+
+[RetinaFace](https://sefiks.com/2021/04/27/deep-face-detection-with-retinaface-in-python/) and [MTCNN](https://sefiks.com/2020/09/09/deep-face-detection-with-mtcnn-in-python/) seem to overperform in detection and alignment stages but they are much slower. If the speed of your pipeline is more important, then you should use opencv or ssd. On the other hand, if you consider the accuracy, then you should use retinaface or mtcnn.
+
+The performance of RetinaFace is very satisfactory even in the crowd as seen in the following illustration. Besides, it comes with an incredible facial landmark detection performance. Highlighted red points show some facial landmarks such as eyes, nose and mouth. That's why, alignment score of RetinaFace is high as well.
+
+ +
+
The Yellow Angels - Fenerbahce Women's Volleyball Team
+
+
+You can find out more about RetinaFace on this [repo](https://github.com/serengil/retinaface).
+
+**Real Time Analysis** - [`Demo`](https://youtu.be/-c9sSJcx6wI)
+
+You can run deepface for real time videos as well. Stream function will access your webcam and apply both face recognition and facial attribute analysis. The function starts to analyze a frame if it can focus a face sequentially 5 frames. Then, it shows results 5 seconds.
+
+```python
+DeepFace.stream(db_path = "C:/User/Sefik/Desktop/database")
+```
+
+
+
+Even though face recognition is based on one-shot learning, you can use multiple face pictures of a person as well. You should rearrange your directory structure as illustrated below.
+
+```bash
+user
+├── database
+│ ├── Alice
+│ │ ├── Alice1.jpg
+│ │ ├── Alice2.jpg
+│ ├── Bob
+│ │ ├── Bob.jpg
+```
+
+**API** - [`Demo`](https://youtu.be/HeKCQ6U9XmI)
+
+DeepFace serves an API as well. You can clone [`/api`](https://github.com/serengil/deepface/tree/master/api) folder and run the api via gunicorn server. This will get a rest service up. In this way, you can call deepface from an external system such as mobile app or web.
+
+```shell
+cd scripts
+./service.sh
+```
+
+
+
+Face recognition, facial attribute analysis and vector representation functions are covered in the API. You are expected to call these functions as http post methods. Default service endpoints will be `http://localhost:5000/verify` for face recognition, `http://localhost:5000/analyze` for facial attribute analysis, and `http://localhost:5000/represent` for vector representation. You can pass input images as exact image paths on your environment, base64 encoded strings or images on web. [Here](https://github.com/serengil/deepface/tree/master/api), you can find a postman project to find out how these methods should be called.
+
+**Dockerized Service**
+
+You can deploy the deepface api on a kubernetes cluster with docker. The following [shell script](https://github.com/serengil/deepface/blob/master/scripts/dockerize.sh) will serve deepface on `localhost:5000`. You need to re-configure the [Dockerfile](https://github.com/serengil/deepface/blob/master/Dockerfile) if you want to change the port. Then, even if you do not have a development environment, you will be able to consume deepface services such as verify and analyze. You can also access the inside of the docker image to run deepface related commands. Please follow the instructions in the [shell script](https://github.com/serengil/deepface/blob/master/scripts/dockerize.sh).
+
+```shell
+cd scripts
+./dockerize.sh
+```
+
+
+
+**Command Line Interface** - [`Demo`](https://youtu.be/PKKTAr3ts2s)
+
+DeepFace comes with a command line interface as well. You are able to access its functions in command line as shown below. The command deepface expects the function name as 1st argument and function arguments thereafter.
+
+```shell
+#face verification
+$ deepface verify -img1_path tests/dataset/img1.jpg -img2_path tests/dataset/img2.jpg
+
+#facial analysis
+$ deepface analyze -img_path tests/dataset/img1.jpg
+```
+
+You can also run these commands if you are running deepface with docker. Please follow the instructions in the [shell script](https://github.com/serengil/deepface/blob/master/scripts/dockerize.sh#L17).
+
+## Contribution [](https://github.com/serengil/deepface/actions/workflows/tests.yml)
+
+Pull requests are more than welcome! You should run the unit tests locally by running [`test/unit_tests.py`](https://github.com/serengil/deepface/blob/master/tests/unit_tests.py) before creating a PR. Once a PR sent, GitHub test workflow will be run automatically and unit test results will be available in [GitHub actions](https://github.com/serengil/deepface/actions) before approval. Besides, workflow will evaluate the code with pylint as well.
+
+## Support
+
+There are many ways to support a project - starring⭐️ the GitHub repo is just one 🙏
+
+You can also support this work on [Patreon](https://www.patreon.com/serengil?repo=deepface) or [GitHub Sponsors](https://github.com/sponsors/serengil).
+
+
+ +
+
+## Citation
+
+Please cite deepface in your publications if it helps your research. Here are its BibTex entries:
+
+If you use deepface for facial recogntion purposes, please cite the this publication.
+
+```BibTeX
+@inproceedings{serengil2020lightface,
+ title = {LightFace: A Hybrid Deep Face Recognition Framework},
+ author = {Serengil, Sefik Ilkin and Ozpinar, Alper},
+ booktitle = {2020 Innovations in Intelligent Systems and Applications Conference (ASYU)},
+ pages = {23-27},
+ year = {2020},
+ doi = {10.1109/ASYU50717.2020.9259802},
+ url = {https://doi.org/10.1109/ASYU50717.2020.9259802},
+ organization = {IEEE}
+}
+```
+
+ If you use deepface for facial attribute analysis purposes such as age, gender, emotion or ethnicity prediction or face detection purposes, please cite the this publication.
+
+```BibTeX
+@inproceedings{serengil2021lightface,
+ title = {HyperExtended LightFace: A Facial Attribute Analysis Framework},
+ author = {Serengil, Sefik Ilkin and Ozpinar, Alper},
+ booktitle = {2021 International Conference on Engineering and Emerging Technologies (ICEET)},
+ pages = {1-4},
+ year = {2021},
+ doi = {10.1109/ICEET53442.2021.9659697},
+ url = {https://doi.org/10.1109/ICEET53442.2021.9659697},
+ organization = {IEEE}
+}
+```
+
+Also, if you use deepface in your GitHub projects, please add `deepface` in the `requirements.txt`.
+
+## Licence
+
+DeepFace is licensed under the MIT License - see [`LICENSE`](https://github.com/serengil/deepface/blob/master/LICENSE) for more details.
+
+DeepFace wraps some external face recognition models: [VGG-Face](http://www.robots.ox.ac.uk/~vgg/software/vgg_face/), [Facenet](https://github.com/davidsandberg/facenet/blob/master/LICENSE.md), [OpenFace](https://github.com/iwantooxxoox/Keras-OpenFace/blob/master/LICENSE), [DeepFace](https://github.com/swghosh/DeepFace), [DeepID](https://github.com/Ruoyiran/DeepID/blob/master/LICENSE.md), [ArcFace](https://github.com/leondgarse/Keras_insightface/blob/master/LICENSE), [Dlib](https://github.com/davisking/dlib/blob/master/dlib/LICENSE.txt), and [SFace](https://github.com/opencv/opencv_zoo/blob/master/models/face_recognition_sface/LICENSE). Besides, age, gender and race / ethnicity models were trained on the backbone of VGG-Face with transfer learning. Licence types will be inherited if you are going to use those models. Please check the license types of those models for production purposes.
+
+DeepFace [logo](https://thenounproject.com/term/face-recognition/2965879/) is created by [Adrien Coquet](https://thenounproject.com/coquet_adrien/) and it is licensed under [Creative Commons: By Attribution 3.0 License](https://creativecommons.org/licenses/by/3.0/).
diff --git a/modules/deepface-master/api/api.py b/modules/deepface-master/api/api.py
new file mode 100644
index 000000000..e6f66832e
--- /dev/null
+++ b/modules/deepface-master/api/api.py
@@ -0,0 +1,9 @@
+import argparse
+import app
+
+if __name__ == "__main__":
+ deepface_app = app.create_app()
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-p", "--port", type=int, default=5000, help="Port of serving api")
+ args = parser.parse_args()
+ deepface_app.run(host="0.0.0.0", port=args.port)
diff --git a/modules/deepface-master/api/app.py b/modules/deepface-master/api/app.py
new file mode 100644
index 000000000..7ad23ee11
--- /dev/null
+++ b/modules/deepface-master/api/app.py
@@ -0,0 +1,9 @@
+# 3rd parth dependencies
+from flask import Flask
+from routes import blueprint
+
+
+def create_app():
+ app = Flask(__name__)
+ app.register_blueprint(blueprint)
+ return app
diff --git a/modules/deepface-master/api/deepface-api.postman_collection.json b/modules/deepface-master/api/deepface-api.postman_collection.json
new file mode 100644
index 000000000..0cbb0a388
--- /dev/null
+++ b/modules/deepface-master/api/deepface-api.postman_collection.json
@@ -0,0 +1,102 @@
+{
+ "info": {
+ "_postman_id": "4c0b144e-4294-4bdd-8072-bcb326b1fed2",
+ "name": "deepface-api",
+ "schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
+ },
+ "item": [
+ {
+ "name": "Represent",
+ "request": {
+ "method": "POST",
+ "header": [],
+ "body": {
+ "mode": "raw",
+ "raw": "{\n \"model_name\": \"Facenet\",\n \"img\": \"/Users/sefik/Desktop/deepface/tests/dataset/img1.jpg\"\n}",
+ "options": {
+ "raw": {
+ "language": "json"
+ }
+ }
+ },
+ "url": {
+ "raw": "http://127.0.0.1:5000/represent",
+ "protocol": "http",
+ "host": [
+ "127",
+ "0",
+ "0",
+ "1"
+ ],
+ "port": "5000",
+ "path": [
+ "represent"
+ ]
+ }
+ },
+ "response": []
+ },
+ {
+ "name": "Face verification",
+ "request": {
+ "method": "POST",
+ "header": [],
+ "body": {
+ "mode": "raw",
+ "raw": " {\n \t\"img1_path\": \"/Users/sefik/Desktop/deepface/tests/dataset/img1.jpg\",\n \"img2_path\": \"/Users/sefik/Desktop/deepface/tests/dataset/img2.jpg\",\n \"model_name\": \"Facenet\",\n \"detector_backend\": \"mtcnn\",\n \"distance_metric\": \"euclidean\"\n }",
+ "options": {
+ "raw": {
+ "language": "json"
+ }
+ }
+ },
+ "url": {
+ "raw": "http://127.0.0.1:5000/verify",
+ "protocol": "http",
+ "host": [
+ "127",
+ "0",
+ "0",
+ "1"
+ ],
+ "port": "5000",
+ "path": [
+ "verify"
+ ]
+ }
+ },
+ "response": []
+ },
+ {
+ "name": "Face analysis",
+ "request": {
+ "method": "POST",
+ "header": [],
+ "body": {
+ "mode": "raw",
+ "raw": "{\n \"img_path\": \"/Users/sefik/Desktop/deepface/tests/dataset/couple.jpg\",\n \"actions\": [\"age\", \"gender\", \"emotion\", \"race\"]\n}",
+ "options": {
+ "raw": {
+ "language": "json"
+ }
+ }
+ },
+ "url": {
+ "raw": "http://127.0.0.1:5000/analyze",
+ "protocol": "http",
+ "host": [
+ "127",
+ "0",
+ "0",
+ "1"
+ ],
+ "port": "5000",
+ "path": [
+ "analyze"
+ ]
+ }
+ },
+ "response": []
+ }
+ ]
+}
\ No newline at end of file
diff --git a/modules/deepface-master/api/routes.py b/modules/deepface-master/api/routes.py
new file mode 100644
index 000000000..45808320b
--- /dev/null
+++ b/modules/deepface-master/api/routes.py
@@ -0,0 +1,100 @@
+from flask import Blueprint, request
+import service
+
+blueprint = Blueprint("routes", __name__)
+
+
+@blueprint.route("/")
+def home():
+ return "
+
+
+## Citation
+
+Please cite deepface in your publications if it helps your research. Here are its BibTex entries:
+
+If you use deepface for facial recogntion purposes, please cite the this publication.
+
+```BibTeX
+@inproceedings{serengil2020lightface,
+ title = {LightFace: A Hybrid Deep Face Recognition Framework},
+ author = {Serengil, Sefik Ilkin and Ozpinar, Alper},
+ booktitle = {2020 Innovations in Intelligent Systems and Applications Conference (ASYU)},
+ pages = {23-27},
+ year = {2020},
+ doi = {10.1109/ASYU50717.2020.9259802},
+ url = {https://doi.org/10.1109/ASYU50717.2020.9259802},
+ organization = {IEEE}
+}
+```
+
+ If you use deepface for facial attribute analysis purposes such as age, gender, emotion or ethnicity prediction or face detection purposes, please cite the this publication.
+
+```BibTeX
+@inproceedings{serengil2021lightface,
+ title = {HyperExtended LightFace: A Facial Attribute Analysis Framework},
+ author = {Serengil, Sefik Ilkin and Ozpinar, Alper},
+ booktitle = {2021 International Conference on Engineering and Emerging Technologies (ICEET)},
+ pages = {1-4},
+ year = {2021},
+ doi = {10.1109/ICEET53442.2021.9659697},
+ url = {https://doi.org/10.1109/ICEET53442.2021.9659697},
+ organization = {IEEE}
+}
+```
+
+Also, if you use deepface in your GitHub projects, please add `deepface` in the `requirements.txt`.
+
+## Licence
+
+DeepFace is licensed under the MIT License - see [`LICENSE`](https://github.com/serengil/deepface/blob/master/LICENSE) for more details.
+
+DeepFace wraps some external face recognition models: [VGG-Face](http://www.robots.ox.ac.uk/~vgg/software/vgg_face/), [Facenet](https://github.com/davidsandberg/facenet/blob/master/LICENSE.md), [OpenFace](https://github.com/iwantooxxoox/Keras-OpenFace/blob/master/LICENSE), [DeepFace](https://github.com/swghosh/DeepFace), [DeepID](https://github.com/Ruoyiran/DeepID/blob/master/LICENSE.md), [ArcFace](https://github.com/leondgarse/Keras_insightface/blob/master/LICENSE), [Dlib](https://github.com/davisking/dlib/blob/master/dlib/LICENSE.txt), and [SFace](https://github.com/opencv/opencv_zoo/blob/master/models/face_recognition_sface/LICENSE). Besides, age, gender and race / ethnicity models were trained on the backbone of VGG-Face with transfer learning. Licence types will be inherited if you are going to use those models. Please check the license types of those models for production purposes.
+
+DeepFace [logo](https://thenounproject.com/term/face-recognition/2965879/) is created by [Adrien Coquet](https://thenounproject.com/coquet_adrien/) and it is licensed under [Creative Commons: By Attribution 3.0 License](https://creativecommons.org/licenses/by/3.0/).
diff --git a/modules/deepface-master/api/api.py b/modules/deepface-master/api/api.py
new file mode 100644
index 000000000..e6f66832e
--- /dev/null
+++ b/modules/deepface-master/api/api.py
@@ -0,0 +1,9 @@
+import argparse
+import app
+
+if __name__ == "__main__":
+ deepface_app = app.create_app()
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-p", "--port", type=int, default=5000, help="Port of serving api")
+ args = parser.parse_args()
+ deepface_app.run(host="0.0.0.0", port=args.port)
diff --git a/modules/deepface-master/api/app.py b/modules/deepface-master/api/app.py
new file mode 100644
index 000000000..7ad23ee11
--- /dev/null
+++ b/modules/deepface-master/api/app.py
@@ -0,0 +1,9 @@
+# 3rd parth dependencies
+from flask import Flask
+from routes import blueprint
+
+
+def create_app():
+ app = Flask(__name__)
+ app.register_blueprint(blueprint)
+ return app
diff --git a/modules/deepface-master/api/deepface-api.postman_collection.json b/modules/deepface-master/api/deepface-api.postman_collection.json
new file mode 100644
index 000000000..0cbb0a388
--- /dev/null
+++ b/modules/deepface-master/api/deepface-api.postman_collection.json
@@ -0,0 +1,102 @@
+{
+ "info": {
+ "_postman_id": "4c0b144e-4294-4bdd-8072-bcb326b1fed2",
+ "name": "deepface-api",
+ "schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
+ },
+ "item": [
+ {
+ "name": "Represent",
+ "request": {
+ "method": "POST",
+ "header": [],
+ "body": {
+ "mode": "raw",
+ "raw": "{\n \"model_name\": \"Facenet\",\n \"img\": \"/Users/sefik/Desktop/deepface/tests/dataset/img1.jpg\"\n}",
+ "options": {
+ "raw": {
+ "language": "json"
+ }
+ }
+ },
+ "url": {
+ "raw": "http://127.0.0.1:5000/represent",
+ "protocol": "http",
+ "host": [
+ "127",
+ "0",
+ "0",
+ "1"
+ ],
+ "port": "5000",
+ "path": [
+ "represent"
+ ]
+ }
+ },
+ "response": []
+ },
+ {
+ "name": "Face verification",
+ "request": {
+ "method": "POST",
+ "header": [],
+ "body": {
+ "mode": "raw",
+ "raw": " {\n \t\"img1_path\": \"/Users/sefik/Desktop/deepface/tests/dataset/img1.jpg\",\n \"img2_path\": \"/Users/sefik/Desktop/deepface/tests/dataset/img2.jpg\",\n \"model_name\": \"Facenet\",\n \"detector_backend\": \"mtcnn\",\n \"distance_metric\": \"euclidean\"\n }",
+ "options": {
+ "raw": {
+ "language": "json"
+ }
+ }
+ },
+ "url": {
+ "raw": "http://127.0.0.1:5000/verify",
+ "protocol": "http",
+ "host": [
+ "127",
+ "0",
+ "0",
+ "1"
+ ],
+ "port": "5000",
+ "path": [
+ "verify"
+ ]
+ }
+ },
+ "response": []
+ },
+ {
+ "name": "Face analysis",
+ "request": {
+ "method": "POST",
+ "header": [],
+ "body": {
+ "mode": "raw",
+ "raw": "{\n \"img_path\": \"/Users/sefik/Desktop/deepface/tests/dataset/couple.jpg\",\n \"actions\": [\"age\", \"gender\", \"emotion\", \"race\"]\n}",
+ "options": {
+ "raw": {
+ "language": "json"
+ }
+ }
+ },
+ "url": {
+ "raw": "http://127.0.0.1:5000/analyze",
+ "protocol": "http",
+ "host": [
+ "127",
+ "0",
+ "0",
+ "1"
+ ],
+ "port": "5000",
+ "path": [
+ "analyze"
+ ]
+ }
+ },
+ "response": []
+ }
+ ]
+}
\ No newline at end of file
diff --git a/modules/deepface-master/api/routes.py b/modules/deepface-master/api/routes.py
new file mode 100644
index 000000000..45808320b
--- /dev/null
+++ b/modules/deepface-master/api/routes.py
@@ -0,0 +1,100 @@
+from flask import Blueprint, request
+import service
+
+blueprint = Blueprint("routes", __name__)
+
+
+@blueprint.route("/")
+def home():
+ return "Welcome to DeepFace API!
"
+
+
+@blueprint.route("/represent", methods=["POST"])
+def represent():
+ input_args = request.get_json()
+
+ if input_args is None:
+ return {"message": "empty input set passed"}
+
+ img_path = input_args.get("img")
+ if img_path is None:
+ return {"message": "you must pass img_path input"}
+
+ model_name = input_args.get("model_name", "VGG-Face")
+ detector_backend = input_args.get("detector_backend", "opencv")
+ enforce_detection = input_args.get("enforce_detection", True)
+ align = input_args.get("align", True)
+
+ obj = service.represent(
+ img_path=img_path,
+ model_name=model_name,
+ detector_backend=detector_backend,
+ enforce_detection=enforce_detection,
+ align=align,
+ )
+
+ return obj
+
+
+@blueprint.route("/verify", methods=["POST"])
+def verify():
+ input_args = request.get_json()
+
+ if input_args is None:
+ return {"message": "empty input set passed"}
+
+ img1_path = input_args.get("img1_path")
+ img2_path = input_args.get("img2_path")
+
+ if img1_path is None:
+ return {"message": "you must pass img1_path input"}
+
+ if img2_path is None:
+ return {"message": "you must pass img2_path input"}
+
+ model_name = input_args.get("model_name", "VGG-Face")
+ detector_backend = input_args.get("detector_backend", "opencv")
+ enforce_detection = input_args.get("enforce_detection", True)
+ distance_metric = input_args.get("distance_metric", "cosine")
+ align = input_args.get("align", True)
+
+ verification = service.verify(
+ img1_path=img1_path,
+ img2_path=img2_path,
+ model_name=model_name,
+ detector_backend=detector_backend,
+ distance_metric=distance_metric,
+ align=align,
+ enforce_detection=enforce_detection,
+ )
+
+ verification["verified"] = str(verification["verified"])
+
+ return verification
+
+
+@blueprint.route("/analyze", methods=["POST"])
+def analyze():
+ input_args = request.get_json()
+
+ if input_args is None:
+ return {"message": "empty input set passed"}
+
+ img_path = input_args.get("img_path")
+ if img_path is None:
+ return {"message": "you must pass img_path input"}
+
+ detector_backend = input_args.get("detector_backend", "opencv")
+ enforce_detection = input_args.get("enforce_detection", True)
+ align = input_args.get("align", True)
+ actions = input_args.get("actions", ["age", "gender", "emotion", "race"])
+
+ demographies = service.analyze(
+ img_path=img_path,
+ actions=actions,
+ detector_backend=detector_backend,
+ enforce_detection=enforce_detection,
+ align=align,
+ )
+
+ return demographies
diff --git a/modules/deepface-master/api/service.py b/modules/deepface-master/api/service.py
new file mode 100644
index 000000000..f3a9bbc95
--- /dev/null
+++ b/modules/deepface-master/api/service.py
@@ -0,0 +1,42 @@
+from deepface import DeepFace
+
+
+def represent(img_path, model_name, detector_backend, enforce_detection, align):
+ result = {}
+ embedding_objs = DeepFace.represent(
+ img_path=img_path,
+ model_name=model_name,
+ detector_backend=detector_backend,
+ enforce_detection=enforce_detection,
+ align=align,
+ )
+ result["results"] = embedding_objs
+ return result
+
+
+def verify(
+ img1_path, img2_path, model_name, detector_backend, distance_metric, enforce_detection, align
+):
+ obj = DeepFace.verify(
+ img1_path=img1_path,
+ img2_path=img2_path,
+ model_name=model_name,
+ detector_backend=detector_backend,
+ distance_metric=distance_metric,
+ align=align,
+ enforce_detection=enforce_detection,
+ )
+ return obj
+
+
+def analyze(img_path, actions, detector_backend, enforce_detection, align):
+ result = {}
+ demographies = DeepFace.analyze(
+ img_path=img_path,
+ actions=actions,
+ detector_backend=detector_backend,
+ enforce_detection=enforce_detection,
+ align=align,
+ )
+ result["results"] = demographies
+ return result
diff --git a/modules/deepface-master/deepface/DeepFace.py b/modules/deepface-master/deepface/DeepFace.py
new file mode 100644
index 000000000..84d5f42fc
--- /dev/null
+++ b/modules/deepface-master/deepface/DeepFace.py
@@ -0,0 +1,485 @@
+# common dependencies
+import os
+import warnings
+import logging
+from typing import Any, Dict, List, Tuple, Union
+
+# 3rd party dependencies
+import numpy as np
+import pandas as pd
+import tensorflow as tf
+from deprecated import deprecated
+
+# package dependencies
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+from deepface.modules import (
+ modeling,
+ representation,
+ verification,
+ recognition,
+ demography,
+ detection,
+ realtime,
+)
+
+# pylint: disable=no-else-raise, simplifiable-if-expression
+
+logger = Logger(module="DeepFace")
+
+# -----------------------------------
+# configurations for dependencies
+
+warnings.filterwarnings("ignore")
+os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
+tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
+if tf_version == 2:
+ tf.get_logger().setLevel(logging.ERROR)
+ from tensorflow.keras.models import Model
+else:
+ from keras.models import Model
+# -----------------------------------
+
+
+def build_model(model_name: str) -> Union[Model, Any]:
+ """
+ This function builds a deepface model
+ Parameters:
+ model_name (string): face recognition or facial attribute model
+ VGG-Face, Facenet, OpenFace, DeepFace, DeepID for face recognition
+ Age, Gender, Emotion, Race for facial attributes
+
+ Returns:
+ built deepface model ( (tf.)keras.models.Model )
+ """
+ return modeling.build_model(model_name=model_name)
+
+
+def verify(
+ img1_path: Union[str, np.ndarray],
+ img2_path: Union[str, np.ndarray],
+ model_name: str = "VGG-Face",
+ detector_backend: str = "opencv",
+ distance_metric: str = "cosine",
+ enforce_detection: bool = True,
+ align: bool = True,
+ normalization: str = "base",
+) -> Dict[str, Any]:
+ """
+ This function verifies an image pair is same person or different persons. In the background,
+ verification function represents facial images as vectors and then calculates the similarity
+ between those vectors. Vectors of same person images should have more similarity (or less
+ distance) than vectors of different persons.
+
+ Parameters:
+ img1_path, img2_path: exact image path as string. numpy array (BGR) or based64 encoded
+ images are also welcome. If one of pair has more than one face, then we will compare the
+ face pair with max similarity.
+
+ model_name (str): VGG-Face, Facenet, Facenet512, OpenFace, DeepFace, DeepID, Dlib
+ , ArcFace and SFace
+
+ distance_metric (string): cosine, euclidean, euclidean_l2
+
+ enforce_detection (boolean): If no face could not be detected in an image, then this
+ function will return exception by default. Set this to False not to have this exception.
+ This might be convenient for low resolution images.
+
+ detector_backend (string): set face detector backend to opencv, retinaface, mtcnn, ssd,
+ dlib, mediapipe or yolov8.
+
+ align (boolean): alignment according to the eye positions.
+
+ normalization (string): normalize the input image before feeding to model
+
+ Returns:
+ Verify function returns a dictionary.
+
+ {
+ "verified": True
+ , "distance": 0.2563
+ , "max_threshold_to_verify": 0.40
+ , "model": "VGG-Face"
+ , "similarity_metric": "cosine"
+ , 'facial_areas': {
+ 'img1': {'x': 345, 'y': 211, 'w': 769, 'h': 769},
+ 'img2': {'x': 318, 'y': 534, 'w': 779, 'h': 779}
+ }
+ , "time": 2
+ }
+
+ """
+
+ return verification.verify(
+ img1_path=img1_path,
+ img2_path=img2_path,
+ model_name=model_name,
+ detector_backend=detector_backend,
+ distance_metric=distance_metric,
+ enforce_detection=enforce_detection,
+ align=align,
+ normalization=normalization,
+ )
+
+
+def analyze(
+ img_path: Union[str, np.ndarray],
+ actions: Union[tuple, list] = ("emotion", "age", "gender", "race"),
+ enforce_detection: bool = True,
+ detector_backend: str = "opencv",
+ align: bool = True,
+ silent: bool = False,
+) -> List[Dict[str, Any]]:
+ """
+ This function analyzes facial attributes including age, gender, emotion and race.
+ In the background, analysis function builds convolutional neural network models to
+ classify age, gender, emotion and race of the input image.
+
+ Parameters:
+ img_path: exact image path, numpy array (BGR) or base64 encoded image could be passed.
+ If source image has more than one face, then result will be size of number of faces
+ appearing in the image.
+
+ actions (tuple): The default is ('age', 'gender', 'emotion', 'race'). You can drop
+ some of those attributes.
+
+ enforce_detection (bool): The function throws exception if no face detected by default.
+ Set this to False if you don't want to get exception. This might be convenient for low
+ resolution images.
+
+ detector_backend (string): set face detector backend to opencv, retinaface, mtcnn, ssd,
+ dlib, mediapipe or yolov8.
+
+ align (boolean): alignment according to the eye positions.
+
+ silent (boolean): disable (some) log messages
+
+ Returns:
+ The function returns a list of dictionaries for each face appearing in the image.
+
+ [
+ {
+ "region": {'x': 230, 'y': 120, 'w': 36, 'h': 45},
+ "age": 28.66,
+ 'face_confidence': 0.9993908405303955,
+ "dominant_gender": "Woman",
+ "gender": {
+ 'Woman': 99.99407529830933,
+ 'Man': 0.005928758764639497,
+ }
+ "dominant_emotion": "neutral",
+ "emotion": {
+ 'sad': 37.65260875225067,
+ 'angry': 0.15512987738475204,
+ 'surprise': 0.0022171278033056296,
+ 'fear': 1.2489334680140018,
+ 'happy': 4.609785228967667,
+ 'disgust': 9.698561953541684e-07,
+ 'neutral': 56.33133053779602
+ }
+ "dominant_race": "white",
+ "race": {
+ 'indian': 0.5480832420289516,
+ 'asian': 0.7830780930817127,
+ 'latino hispanic': 2.0677512511610985,
+ 'black': 0.06337375962175429,
+ 'middle eastern': 3.088453598320484,
+ 'white': 93.44925880432129
+ }
+ }
+ ]
+ """
+ return demography.analyze(
+ img_path=img_path,
+ actions=actions,
+ enforce_detection=enforce_detection,
+ detector_backend=detector_backend,
+ align=align,
+ silent=silent,
+ )
+
+
+def find(
+ img_path: Union[str, np.ndarray],
+ db_path: str,
+ model_name: str = "VGG-Face",
+ distance_metric: str = "cosine",
+ enforce_detection: bool = True,
+ detector_backend: str = "opencv",
+ align: bool = True,
+ normalization: str = "base",
+ silent: bool = False,
+) -> List[pd.DataFrame]:
+ """
+ This function applies verification several times and find the identities in a database
+
+ Parameters:
+ img_path: exact image path, numpy array (BGR) or based64 encoded image.
+ Source image can have many faces. Then, result will be the size of number of
+ faces in the source image.
+
+ db_path (string): You should store some image files in a folder and pass the
+ exact folder path to this. A database image can also have many faces.
+ Then, all detected faces in db side will be considered in the decision.
+
+ model_name (string): VGG-Face, Facenet, Facenet512, OpenFace, DeepFace, DeepID,
+ Dlib, ArcFace, SFace or Ensemble
+
+ distance_metric (string): cosine, euclidean, euclidean_l2
+
+ enforce_detection (bool): The function throws exception if a face could not be detected.
+ Set this to False if you don't want to get exception. This might be convenient for low
+ resolution images.
+
+ detector_backend (string): set face detector backend to opencv, retinaface, mtcnn, ssd,
+ dlib, mediapipe or yolov8.
+
+ align (boolean): alignment according to the eye positions.
+
+ normalization (string): normalize the input image before feeding to model
+
+ silent (boolean): disable some logging and progress bars
+
+ Returns:
+ This function returns list of pandas data frame. Each item of the list corresponding to
+ an identity in the img_path.
+ """
+ return recognition.find(
+ img_path=img_path,
+ db_path=db_path,
+ model_name=model_name,
+ distance_metric=distance_metric,
+ enforce_detection=enforce_detection,
+ detector_backend=detector_backend,
+ align=align,
+ normalization=normalization,
+ silent=silent,
+ )
+
+
+def represent(
+ img_path: Union[str, np.ndarray],
+ model_name: str = "VGG-Face",
+ enforce_detection: bool = True,
+ detector_backend: str = "opencv",
+ align: bool = True,
+ normalization: str = "base",
+) -> List[Dict[str, Any]]:
+ """
+ This function represents facial images as vectors. The function uses convolutional neural
+ networks models to generate vector embeddings.
+
+ Parameters:
+ img_path (string): exact image path. Alternatively, numpy array (BGR) or based64
+ encoded images could be passed. Source image can have many faces. Then, result will
+ be the size of number of faces appearing in the source image.
+
+ model_name (string): VGG-Face, Facenet, Facenet512, OpenFace, DeepFace, DeepID, Dlib,
+ ArcFace, SFace
+
+ enforce_detection (boolean): If no face could not be detected in an image, then this
+ function will return exception by default. Set this to False not to have this exception.
+ This might be convenient for low resolution images.
+
+ detector_backend (string): set face detector backend to opencv, retinaface, mtcnn, ssd,
+ dlib, mediapipe or yolov8. A special value `skip` could be used to skip face-detection
+ and only encode the given image.
+
+ align (boolean): alignment according to the eye positions.
+
+ normalization (string): normalize the input image before feeding to model
+
+ Returns:
+ Represent function returns a list of object, each object has fields as follows:
+ {
+ // Multidimensional vector
+ // The number of dimensions is changing based on the reference model.
+ // E.g. FaceNet returns 128 dimensional vector;
+ // VGG-Face returns 2622 dimensional vector.
+ "embedding": np.array,
+
+ // Detected Facial-Area by Face detection in dict format.
+ // (x, y) is left-corner point, and (w, h) is the width and height
+ // If `detector_backend` == `skip`, it is the full image area and nonsense.
+ "facial_area": dict{"x": int, "y": int, "w": int, "h": int},
+
+ // Face detection confidence.
+ // If `detector_backend` == `skip`, will be 0 and nonsense.
+ "face_confidence": float
+ }
+ """
+ return representation.represent(
+ img_path=img_path,
+ model_name=model_name,
+ enforce_detection=enforce_detection,
+ detector_backend=detector_backend,
+ align=align,
+ normalization=normalization,
+ )
+
+
+def stream(
+ db_path: str = "",
+ model_name: str = "VGG-Face",
+ detector_backend: str = "opencv",
+ distance_metric: str = "cosine",
+ enable_face_analysis: bool = True,
+ source: Any = 0,
+ time_threshold: int = 5,
+ frame_threshold: int = 5,
+) -> None:
+ """
+ This function applies real time face recognition and facial attribute analysis
+
+ Parameters:
+ db_path (string): facial database path. You should store some .jpg files in this folder.
+
+ model_name (string): VGG-Face, Facenet, Facenet512, OpenFace, DeepFace, DeepID, Dlib,
+ ArcFace, SFace
+
+ detector_backend (string): opencv, retinaface, mtcnn, ssd, dlib, mediapipe or yolov8.
+
+ distance_metric (string): cosine, euclidean, euclidean_l2
+
+ enable_facial_analysis (boolean): Set this to False to just run face recognition
+
+ source: Set this to 0 for access web cam. Otherwise, pass exact video path.
+
+ time_threshold (int): how many second analyzed image will be displayed
+
+ frame_threshold (int): how many frames required to focus on face
+
+ """
+
+ time_threshold = max(time_threshold, 1)
+ frame_threshold = max(frame_threshold, 1)
+
+ realtime.analysis(
+ db_path=db_path,
+ model_name=model_name,
+ detector_backend=detector_backend,
+ distance_metric=distance_metric,
+ enable_face_analysis=enable_face_analysis,
+ source=source,
+ time_threshold=time_threshold,
+ frame_threshold=frame_threshold,
+ )
+
+
+def extract_faces(
+ img_path: Union[str, np.ndarray],
+ target_size: Tuple[int, int] = (224, 224),
+ detector_backend: str = "opencv",
+ enforce_detection: bool = True,
+ align: bool = True,
+ grayscale: bool = False,
+) -> List[Dict[str, Any]]:
+ """
+ This function applies pre-processing stages of a face recognition pipeline
+ including detection and alignment
+
+ Parameters:
+ img_path: exact image path, numpy array (BGR) or base64 encoded image.
+ Source image can have many face. Then, result will be the size of number
+ of faces appearing in that source image.
+
+ target_size (tuple): final shape of facial image. black pixels will be
+ added to resize the image.
+
+ detector_backend (string): face detection backends are retinaface, mtcnn,
+ opencv, ssd or dlib
+
+ enforce_detection (boolean): function throws exception if face cannot be
+ detected in the fed image. Set this to False if you do not want to get
+ an exception and run the function anyway.
+
+ align (boolean): alignment according to the eye positions.
+
+ grayscale (boolean): extracting faces in rgb or gray scale
+
+ Returns:
+ list of dictionaries. Each dictionary will have facial image itself,
+ extracted area from the original image and confidence score.
+
+ """
+
+ return detection.extract_faces(
+ img_path=img_path,
+ target_size=target_size,
+ detector_backend=detector_backend,
+ enforce_detection=enforce_detection,
+ align=align,
+ grayscale=grayscale,
+ )
+
+
+# ---------------------------
+# deprecated functions
+
+
+@deprecated(version="0.0.78", reason="Use DeepFace.extract_faces instead of DeepFace.detectFace")
+def detectFace(
+ img_path: Union[str, np.ndarray],
+ target_size: tuple = (224, 224),
+ detector_backend: str = "opencv",
+ enforce_detection: bool = True,
+ align: bool = True,
+) -> Union[np.ndarray, None]:
+ """
+ Deprecated function. Use extract_faces for same functionality.
+
+ This function applies pre-processing stages of a face recognition pipeline
+ including detection and alignment
+
+ Parameters:
+ img_path: exact image path, numpy array (BGR) or base64 encoded image.
+ Source image can have many face. Then, result will be the size of number
+ of faces appearing in that source image.
+
+ target_size (tuple): final shape of facial image. black pixels will be
+ added to resize the image.
+
+ detector_backend (string): face detection backends are retinaface, mtcnn,
+ opencv, ssd or dlib
+
+ enforce_detection (boolean): function throws exception if face cannot be
+ detected in the fed image. Set this to False if you do not want to get
+ an exception and run the function anyway.
+
+ align (boolean): alignment according to the eye positions.
+
+ grayscale (boolean): extracting faces in rgb or gray scale
+
+ Returns:
+ detected and aligned face as numpy array
+
+ """
+ logger.warn("Function detectFace is deprecated. Use extract_faces instead.")
+ face_objs = extract_faces(
+ img_path=img_path,
+ target_size=target_size,
+ detector_backend=detector_backend,
+ enforce_detection=enforce_detection,
+ align=align,
+ grayscale=False,
+ )
+
+ extracted_face = None
+ if len(face_objs) > 0:
+ extracted_face = face_objs[0]["face"]
+ return extracted_face
+
+
+# ---------------------------
+# main
+
+functions.initialize_folder()
+
+
+def cli() -> None:
+ """
+ command line interface function will be offered in this block
+ """
+ import fire
+
+ fire.Fire()
diff --git a/modules/deepface-master/deepface/__init__.py b/modules/deepface-master/deepface/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/modules/deepface-master/deepface/basemodels/ArcFace.py b/modules/deepface-master/deepface/basemodels/ArcFace.py
new file mode 100644
index 000000000..b3059bda7
--- /dev/null
+++ b/modules/deepface-master/deepface/basemodels/ArcFace.py
@@ -0,0 +1,157 @@
+import os
+import gdown
+import tensorflow as tf
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="basemodels.ArcFace")
+
+# pylint: disable=unsubscriptable-object
+
+# --------------------------------
+# dependency configuration
+
+tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
+
+if tf_version == 1:
+ from keras.models import Model
+ from keras.engine import training
+ from keras.layers import (
+ ZeroPadding2D,
+ Input,
+ Conv2D,
+ BatchNormalization,
+ PReLU,
+ Add,
+ Dropout,
+ Flatten,
+ Dense,
+ )
+else:
+ from tensorflow.keras.models import Model
+ from tensorflow.python.keras.engine import training
+ from tensorflow.keras.layers import (
+ ZeroPadding2D,
+ Input,
+ Conv2D,
+ BatchNormalization,
+ PReLU,
+ Add,
+ Dropout,
+ Flatten,
+ Dense,
+ )
+
+
+def loadModel(
+ url="https://github.com/serengil/deepface_models/releases/download/v1.0/arcface_weights.h5",
+) -> Model:
+ base_model = ResNet34()
+ inputs = base_model.inputs[0]
+ arcface_model = base_model.outputs[0]
+ arcface_model = BatchNormalization(momentum=0.9, epsilon=2e-5)(arcface_model)
+ arcface_model = Dropout(0.4)(arcface_model)
+ arcface_model = Flatten()(arcface_model)
+ arcface_model = Dense(512, activation=None, use_bias=True, kernel_initializer="glorot_normal")(
+ arcface_model
+ )
+ embedding = BatchNormalization(momentum=0.9, epsilon=2e-5, name="embedding", scale=True)(
+ arcface_model
+ )
+ model = Model(inputs, embedding, name=base_model.name)
+
+ # ---------------------------------------
+ # check the availability of pre-trained weights
+
+ home = functions.get_deepface_home()
+
+ file_name = "arcface_weights.h5"
+ output = home + "/.deepface/weights/" + file_name
+
+ if os.path.isfile(output) != True:
+
+ logger.info(f"{file_name} will be downloaded to {output}")
+ gdown.download(url, output, quiet=False)
+
+ # ---------------------------------------
+
+ model.load_weights(output)
+
+ return model
+
+
+def ResNet34() -> Model:
+
+ img_input = Input(shape=(112, 112, 3))
+
+ x = ZeroPadding2D(padding=1, name="conv1_pad")(img_input)
+ x = Conv2D(
+ 64, 3, strides=1, use_bias=False, kernel_initializer="glorot_normal", name="conv1_conv"
+ )(x)
+ x = BatchNormalization(axis=3, epsilon=2e-5, momentum=0.9, name="conv1_bn")(x)
+ x = PReLU(shared_axes=[1, 2], name="conv1_prelu")(x)
+ x = stack_fn(x)
+
+ model = training.Model(img_input, x, name="ResNet34")
+
+ return model
+
+
+def block1(x, filters, kernel_size=3, stride=1, conv_shortcut=True, name=None):
+ bn_axis = 3
+
+ if conv_shortcut:
+ shortcut = Conv2D(
+ filters,
+ 1,
+ strides=stride,
+ use_bias=False,
+ kernel_initializer="glorot_normal",
+ name=name + "_0_conv",
+ )(x)
+ shortcut = BatchNormalization(
+ axis=bn_axis, epsilon=2e-5, momentum=0.9, name=name + "_0_bn"
+ )(shortcut)
+ else:
+ shortcut = x
+
+ x = BatchNormalization(axis=bn_axis, epsilon=2e-5, momentum=0.9, name=name + "_1_bn")(x)
+ x = ZeroPadding2D(padding=1, name=name + "_1_pad")(x)
+ x = Conv2D(
+ filters,
+ 3,
+ strides=1,
+ kernel_initializer="glorot_normal",
+ use_bias=False,
+ name=name + "_1_conv",
+ )(x)
+ x = BatchNormalization(axis=bn_axis, epsilon=2e-5, momentum=0.9, name=name + "_2_bn")(x)
+ x = PReLU(shared_axes=[1, 2], name=name + "_1_prelu")(x)
+
+ x = ZeroPadding2D(padding=1, name=name + "_2_pad")(x)
+ x = Conv2D(
+ filters,
+ kernel_size,
+ strides=stride,
+ kernel_initializer="glorot_normal",
+ use_bias=False,
+ name=name + "_2_conv",
+ )(x)
+ x = BatchNormalization(axis=bn_axis, epsilon=2e-5, momentum=0.9, name=name + "_3_bn")(x)
+
+ x = Add(name=name + "_add")([shortcut, x])
+ return x
+
+
+def stack1(x, filters, blocks, stride1=2, name=None):
+ x = block1(x, filters, stride=stride1, name=name + "_block1")
+ for i in range(2, blocks + 1):
+ x = block1(x, filters, conv_shortcut=False, name=name + "_block" + str(i))
+ return x
+
+
+def stack_fn(x):
+ x = stack1(x, 64, 3, name="conv2")
+ x = stack1(x, 128, 4, name="conv3")
+ x = stack1(x, 256, 6, name="conv4")
+ return stack1(x, 512, 3, name="conv5")
diff --git a/modules/deepface-master/deepface/basemodels/DeepID.py b/modules/deepface-master/deepface/basemodels/DeepID.py
new file mode 100644
index 000000000..fa128b083
--- /dev/null
+++ b/modules/deepface-master/deepface/basemodels/DeepID.py
@@ -0,0 +1,84 @@
+import os
+import gdown
+import tensorflow as tf
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="basemodels.DeepID")
+
+tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
+
+if tf_version == 1:
+ from keras.models import Model
+ from keras.layers import (
+ Conv2D,
+ Activation,
+ Input,
+ Add,
+ MaxPooling2D,
+ Flatten,
+ Dense,
+ Dropout,
+ )
+else:
+ from tensorflow.keras.models import Model
+ from tensorflow.keras.layers import (
+ Conv2D,
+ Activation,
+ Input,
+ Add,
+ MaxPooling2D,
+ Flatten,
+ Dense,
+ Dropout,
+ )
+
+# pylint: disable=line-too-long
+
+
+# -------------------------------------
+
+
+def loadModel(
+ url="https://github.com/serengil/deepface_models/releases/download/v1.0/deepid_keras_weights.h5",
+) -> Model:
+
+ myInput = Input(shape=(55, 47, 3))
+
+ x = Conv2D(20, (4, 4), name="Conv1", activation="relu", input_shape=(55, 47, 3))(myInput)
+ x = MaxPooling2D(pool_size=2, strides=2, name="Pool1")(x)
+ x = Dropout(rate=0.99, name="D1")(x)
+
+ x = Conv2D(40, (3, 3), name="Conv2", activation="relu")(x)
+ x = MaxPooling2D(pool_size=2, strides=2, name="Pool2")(x)
+ x = Dropout(rate=0.99, name="D2")(x)
+
+ x = Conv2D(60, (3, 3), name="Conv3", activation="relu")(x)
+ x = MaxPooling2D(pool_size=2, strides=2, name="Pool3")(x)
+ x = Dropout(rate=0.99, name="D3")(x)
+
+ x1 = Flatten()(x)
+ fc11 = Dense(160, name="fc11")(x1)
+
+ x2 = Conv2D(80, (2, 2), name="Conv4", activation="relu")(x)
+ x2 = Flatten()(x2)
+ fc12 = Dense(160, name="fc12")(x2)
+
+ y = Add()([fc11, fc12])
+ y = Activation("relu", name="deepid")(y)
+
+ model = Model(inputs=[myInput], outputs=y)
+
+ # ---------------------------------
+
+ home = functions.get_deepface_home()
+
+ if os.path.isfile(home + "/.deepface/weights/deepid_keras_weights.h5") != True:
+ logger.info("deepid_keras_weights.h5 will be downloaded...")
+
+ output = home + "/.deepface/weights/deepid_keras_weights.h5"
+ gdown.download(url, output, quiet=False)
+
+ model.load_weights(home + "/.deepface/weights/deepid_keras_weights.h5")
+
+ return model
diff --git a/modules/deepface-master/deepface/basemodels/DlibResNet.py b/modules/deepface-master/deepface/basemodels/DlibResNet.py
new file mode 100644
index 000000000..3cc57f10b
--- /dev/null
+++ b/modules/deepface-master/deepface/basemodels/DlibResNet.py
@@ -0,0 +1,86 @@
+import os
+import bz2
+import gdown
+import numpy as np
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="basemodels.DlibResNet")
+
+# pylint: disable=too-few-public-methods
+
+
+class DlibResNet:
+ def __init__(self):
+
+ ## this is not a must dependency. do not import it in the global level.
+ try:
+ import dlib
+ except ModuleNotFoundError as e:
+ raise ImportError(
+ "Dlib is an optional dependency, ensure the library is installed."
+ "Please install using 'pip install dlib' "
+ ) from e
+
+ self.layers = [DlibMetaData()]
+
+ # ---------------------
+
+ home = functions.get_deepface_home()
+ weight_file = home + "/.deepface/weights/dlib_face_recognition_resnet_model_v1.dat"
+
+ # ---------------------
+
+ # download pre-trained model if it does not exist
+ if os.path.isfile(weight_file) != True:
+ logger.info("dlib_face_recognition_resnet_model_v1.dat is going to be downloaded")
+
+ file_name = "dlib_face_recognition_resnet_model_v1.dat.bz2"
+ url = f"http://dlib.net/files/{file_name}"
+ output = f"{home}/.deepface/weights/{file_name}"
+ gdown.download(url, output, quiet=False)
+
+ zipfile = bz2.BZ2File(output)
+ data = zipfile.read()
+ newfilepath = output[:-4] # discard .bz2 extension
+ with open(newfilepath, "wb") as f:
+ f.write(data)
+
+ # ---------------------
+
+ model = dlib.face_recognition_model_v1(weight_file)
+ self.__model = model
+
+ # ---------------------
+
+ # return None # classes must return None
+
+ def predict(self, img_aligned: np.ndarray) -> np.ndarray:
+
+ # functions.detectFace returns 4 dimensional images
+ if len(img_aligned.shape) == 4:
+ img_aligned = img_aligned[0]
+
+ # functions.detectFace returns bgr images
+ img_aligned = img_aligned[:, :, ::-1] # bgr to rgb
+
+ # deepface.detectFace returns an array in scale of [0, 1]
+ # but dlib expects in scale of [0, 255]
+ if img_aligned.max() <= 1:
+ img_aligned = img_aligned * 255
+
+ img_aligned = img_aligned.astype(np.uint8)
+
+ model = self.__model
+
+ img_representation = model.compute_face_descriptor(img_aligned)
+
+ img_representation = np.array(img_representation)
+ img_representation = np.expand_dims(img_representation, axis=0)
+
+ return img_representation
+
+
+class DlibMetaData:
+ def __init__(self):
+ self.input_shape = [[1, 150, 150, 3]]
diff --git a/modules/deepface-master/deepface/basemodels/DlibWrapper.py b/modules/deepface-master/deepface/basemodels/DlibWrapper.py
new file mode 100644
index 000000000..51f0a0b98
--- /dev/null
+++ b/modules/deepface-master/deepface/basemodels/DlibWrapper.py
@@ -0,0 +1,6 @@
+from typing import Any
+from deepface.basemodels.DlibResNet import DlibResNet
+
+
+def loadModel() -> Any:
+ return DlibResNet()
diff --git a/modules/deepface-master/deepface/basemodels/Facenet.py b/modules/deepface-master/deepface/basemodels/Facenet.py
new file mode 100644
index 000000000..1ad4f8791
--- /dev/null
+++ b/modules/deepface-master/deepface/basemodels/Facenet.py
@@ -0,0 +1,1642 @@
+import os
+import gdown
+import tensorflow as tf
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="basemodels.Facenet")
+
+# --------------------------------
+# dependency configuration
+
+tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
+
+if tf_version == 1:
+ from keras.models import Model
+ from keras.layers import Activation
+ from keras.layers import BatchNormalization
+ from keras.layers import Concatenate
+ from keras.layers import Conv2D
+ from keras.layers import Dense
+ from keras.layers import Dropout
+ from keras.layers import GlobalAveragePooling2D
+ from keras.layers import Input
+ from keras.layers import Lambda
+ from keras.layers import MaxPooling2D
+ from keras.layers import add
+ from keras import backend as K
+else:
+ from tensorflow.keras.models import Model
+ from tensorflow.keras.layers import Activation
+ from tensorflow.keras.layers import BatchNormalization
+ from tensorflow.keras.layers import Concatenate
+ from tensorflow.keras.layers import Conv2D
+ from tensorflow.keras.layers import Dense
+ from tensorflow.keras.layers import Dropout
+ from tensorflow.keras.layers import GlobalAveragePooling2D
+ from tensorflow.keras.layers import Input
+ from tensorflow.keras.layers import Lambda
+ from tensorflow.keras.layers import MaxPooling2D
+ from tensorflow.keras.layers import add
+ from tensorflow.keras import backend as K
+
+# --------------------------------
+
+
+def scaling(x, scale):
+ return x * scale
+
+
+def InceptionResNetV2(dimension=128) -> Model:
+
+ inputs = Input(shape=(160, 160, 3))
+ x = Conv2D(32, 3, strides=2, padding="valid", use_bias=False, name="Conv2d_1a_3x3")(inputs)
+ x = BatchNormalization(
+ axis=3, momentum=0.995, epsilon=0.001, scale=False, name="Conv2d_1a_3x3_BatchNorm"
+ )(x)
+ x = Activation("relu", name="Conv2d_1a_3x3_Activation")(x)
+ x = Conv2D(32, 3, strides=1, padding="valid", use_bias=False, name="Conv2d_2a_3x3")(x)
+ x = BatchNormalization(
+ axis=3, momentum=0.995, epsilon=0.001, scale=False, name="Conv2d_2a_3x3_BatchNorm"
+ )(x)
+ x = Activation("relu", name="Conv2d_2a_3x3_Activation")(x)
+ x = Conv2D(64, 3, strides=1, padding="same", use_bias=False, name="Conv2d_2b_3x3")(x)
+ x = BatchNormalization(
+ axis=3, momentum=0.995, epsilon=0.001, scale=False, name="Conv2d_2b_3x3_BatchNorm"
+ )(x)
+ x = Activation("relu", name="Conv2d_2b_3x3_Activation")(x)
+ x = MaxPooling2D(3, strides=2, name="MaxPool_3a_3x3")(x)
+ x = Conv2D(80, 1, strides=1, padding="valid", use_bias=False, name="Conv2d_3b_1x1")(x)
+ x = BatchNormalization(
+ axis=3, momentum=0.995, epsilon=0.001, scale=False, name="Conv2d_3b_1x1_BatchNorm"
+ )(x)
+ x = Activation("relu", name="Conv2d_3b_1x1_Activation")(x)
+ x = Conv2D(192, 3, strides=1, padding="valid", use_bias=False, name="Conv2d_4a_3x3")(x)
+ x = BatchNormalization(
+ axis=3, momentum=0.995, epsilon=0.001, scale=False, name="Conv2d_4a_3x3_BatchNorm"
+ )(x)
+ x = Activation("relu", name="Conv2d_4a_3x3_Activation")(x)
+ x = Conv2D(256, 3, strides=2, padding="valid", use_bias=False, name="Conv2d_4b_3x3")(x)
+ x = BatchNormalization(
+ axis=3, momentum=0.995, epsilon=0.001, scale=False, name="Conv2d_4b_3x3_BatchNorm"
+ )(x)
+ x = Activation("relu", name="Conv2d_4b_3x3_Activation")(x)
+
+ # 5x Block35 (Inception-ResNet-A block):
+ branch_0 = Conv2D(
+ 32, 1, strides=1, padding="same", use_bias=False, name="Block35_1_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_1_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block35_1_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 32, 1, strides=1, padding="same", use_bias=False, name="Block35_1_Branch_1_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_1_Branch_1_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block35_1_Branch_1_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 32, 3, strides=1, padding="same", use_bias=False, name="Block35_1_Branch_1_Conv2d_0b_3x3"
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_1_Branch_1_Conv2d_0b_3x3_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block35_1_Branch_1_Conv2d_0b_3x3_Activation")(branch_1)
+ branch_2 = Conv2D(
+ 32, 1, strides=1, padding="same", use_bias=False, name="Block35_1_Branch_2_Conv2d_0a_1x1"
+ )(x)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_1_Branch_2_Conv2d_0a_1x1_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Block35_1_Branch_2_Conv2d_0a_1x1_Activation")(branch_2)
+ branch_2 = Conv2D(
+ 32, 3, strides=1, padding="same", use_bias=False, name="Block35_1_Branch_2_Conv2d_0b_3x3"
+ )(branch_2)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_1_Branch_2_Conv2d_0b_3x3_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Block35_1_Branch_2_Conv2d_0b_3x3_Activation")(branch_2)
+ branch_2 = Conv2D(
+ 32, 3, strides=1, padding="same", use_bias=False, name="Block35_1_Branch_2_Conv2d_0c_3x3"
+ )(branch_2)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_1_Branch_2_Conv2d_0c_3x3_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Block35_1_Branch_2_Conv2d_0c_3x3_Activation")(branch_2)
+ branches = [branch_0, branch_1, branch_2]
+ mixed = Concatenate(axis=3, name="Block35_1_Concatenate")(branches)
+ up = Conv2D(256, 1, strides=1, padding="same", use_bias=True, name="Block35_1_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.17})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block35_1_Activation")(x)
+
+ branch_0 = Conv2D(
+ 32, 1, strides=1, padding="same", use_bias=False, name="Block35_2_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_2_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block35_2_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 32, 1, strides=1, padding="same", use_bias=False, name="Block35_2_Branch_1_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_2_Branch_1_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block35_2_Branch_1_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 32, 3, strides=1, padding="same", use_bias=False, name="Block35_2_Branch_1_Conv2d_0b_3x3"
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_2_Branch_1_Conv2d_0b_3x3_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block35_2_Branch_1_Conv2d_0b_3x3_Activation")(branch_1)
+ branch_2 = Conv2D(
+ 32, 1, strides=1, padding="same", use_bias=False, name="Block35_2_Branch_2_Conv2d_0a_1x1"
+ )(x)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_2_Branch_2_Conv2d_0a_1x1_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Block35_2_Branch_2_Conv2d_0a_1x1_Activation")(branch_2)
+ branch_2 = Conv2D(
+ 32, 3, strides=1, padding="same", use_bias=False, name="Block35_2_Branch_2_Conv2d_0b_3x3"
+ )(branch_2)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_2_Branch_2_Conv2d_0b_3x3_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Block35_2_Branch_2_Conv2d_0b_3x3_Activation")(branch_2)
+ branch_2 = Conv2D(
+ 32, 3, strides=1, padding="same", use_bias=False, name="Block35_2_Branch_2_Conv2d_0c_3x3"
+ )(branch_2)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_2_Branch_2_Conv2d_0c_3x3_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Block35_2_Branch_2_Conv2d_0c_3x3_Activation")(branch_2)
+ branches = [branch_0, branch_1, branch_2]
+ mixed = Concatenate(axis=3, name="Block35_2_Concatenate")(branches)
+ up = Conv2D(256, 1, strides=1, padding="same", use_bias=True, name="Block35_2_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.17})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block35_2_Activation")(x)
+
+ branch_0 = Conv2D(
+ 32, 1, strides=1, padding="same", use_bias=False, name="Block35_3_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_3_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block35_3_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 32, 1, strides=1, padding="same", use_bias=False, name="Block35_3_Branch_1_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_3_Branch_1_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block35_3_Branch_1_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 32, 3, strides=1, padding="same", use_bias=False, name="Block35_3_Branch_1_Conv2d_0b_3x3"
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_3_Branch_1_Conv2d_0b_3x3_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block35_3_Branch_1_Conv2d_0b_3x3_Activation")(branch_1)
+ branch_2 = Conv2D(
+ 32, 1, strides=1, padding="same", use_bias=False, name="Block35_3_Branch_2_Conv2d_0a_1x1"
+ )(x)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_3_Branch_2_Conv2d_0a_1x1_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Block35_3_Branch_2_Conv2d_0a_1x1_Activation")(branch_2)
+ branch_2 = Conv2D(
+ 32, 3, strides=1, padding="same", use_bias=False, name="Block35_3_Branch_2_Conv2d_0b_3x3"
+ )(branch_2)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_3_Branch_2_Conv2d_0b_3x3_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Block35_3_Branch_2_Conv2d_0b_3x3_Activation")(branch_2)
+ branch_2 = Conv2D(
+ 32, 3, strides=1, padding="same", use_bias=False, name="Block35_3_Branch_2_Conv2d_0c_3x3"
+ )(branch_2)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_3_Branch_2_Conv2d_0c_3x3_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Block35_3_Branch_2_Conv2d_0c_3x3_Activation")(branch_2)
+ branches = [branch_0, branch_1, branch_2]
+ mixed = Concatenate(axis=3, name="Block35_3_Concatenate")(branches)
+ up = Conv2D(256, 1, strides=1, padding="same", use_bias=True, name="Block35_3_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.17})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block35_3_Activation")(x)
+
+ branch_0 = Conv2D(
+ 32, 1, strides=1, padding="same", use_bias=False, name="Block35_4_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_4_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block35_4_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 32, 1, strides=1, padding="same", use_bias=False, name="Block35_4_Branch_1_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_4_Branch_1_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block35_4_Branch_1_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 32, 3, strides=1, padding="same", use_bias=False, name="Block35_4_Branch_1_Conv2d_0b_3x3"
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_4_Branch_1_Conv2d_0b_3x3_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block35_4_Branch_1_Conv2d_0b_3x3_Activation")(branch_1)
+ branch_2 = Conv2D(
+ 32, 1, strides=1, padding="same", use_bias=False, name="Block35_4_Branch_2_Conv2d_0a_1x1"
+ )(x)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_4_Branch_2_Conv2d_0a_1x1_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Block35_4_Branch_2_Conv2d_0a_1x1_Activation")(branch_2)
+ branch_2 = Conv2D(
+ 32, 3, strides=1, padding="same", use_bias=False, name="Block35_4_Branch_2_Conv2d_0b_3x3"
+ )(branch_2)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_4_Branch_2_Conv2d_0b_3x3_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Block35_4_Branch_2_Conv2d_0b_3x3_Activation")(branch_2)
+ branch_2 = Conv2D(
+ 32, 3, strides=1, padding="same", use_bias=False, name="Block35_4_Branch_2_Conv2d_0c_3x3"
+ )(branch_2)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_4_Branch_2_Conv2d_0c_3x3_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Block35_4_Branch_2_Conv2d_0c_3x3_Activation")(branch_2)
+ branches = [branch_0, branch_1, branch_2]
+ mixed = Concatenate(axis=3, name="Block35_4_Concatenate")(branches)
+ up = Conv2D(256, 1, strides=1, padding="same", use_bias=True, name="Block35_4_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.17})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block35_4_Activation")(x)
+
+ branch_0 = Conv2D(
+ 32, 1, strides=1, padding="same", use_bias=False, name="Block35_5_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_5_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block35_5_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 32, 1, strides=1, padding="same", use_bias=False, name="Block35_5_Branch_1_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_5_Branch_1_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block35_5_Branch_1_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 32, 3, strides=1, padding="same", use_bias=False, name="Block35_5_Branch_1_Conv2d_0b_3x3"
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_5_Branch_1_Conv2d_0b_3x3_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block35_5_Branch_1_Conv2d_0b_3x3_Activation")(branch_1)
+ branch_2 = Conv2D(
+ 32, 1, strides=1, padding="same", use_bias=False, name="Block35_5_Branch_2_Conv2d_0a_1x1"
+ )(x)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_5_Branch_2_Conv2d_0a_1x1_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Block35_5_Branch_2_Conv2d_0a_1x1_Activation")(branch_2)
+ branch_2 = Conv2D(
+ 32, 3, strides=1, padding="same", use_bias=False, name="Block35_5_Branch_2_Conv2d_0b_3x3"
+ )(branch_2)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_5_Branch_2_Conv2d_0b_3x3_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Block35_5_Branch_2_Conv2d_0b_3x3_Activation")(branch_2)
+ branch_2 = Conv2D(
+ 32, 3, strides=1, padding="same", use_bias=False, name="Block35_5_Branch_2_Conv2d_0c_3x3"
+ )(branch_2)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block35_5_Branch_2_Conv2d_0c_3x3_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Block35_5_Branch_2_Conv2d_0c_3x3_Activation")(branch_2)
+ branches = [branch_0, branch_1, branch_2]
+ mixed = Concatenate(axis=3, name="Block35_5_Concatenate")(branches)
+ up = Conv2D(256, 1, strides=1, padding="same", use_bias=True, name="Block35_5_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.17})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block35_5_Activation")(x)
+
+ # Mixed 6a (Reduction-A block):
+ branch_0 = Conv2D(
+ 384, 3, strides=2, padding="valid", use_bias=False, name="Mixed_6a_Branch_0_Conv2d_1a_3x3"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Mixed_6a_Branch_0_Conv2d_1a_3x3_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Mixed_6a_Branch_0_Conv2d_1a_3x3_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 192, 1, strides=1, padding="same", use_bias=False, name="Mixed_6a_Branch_1_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Mixed_6a_Branch_1_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Mixed_6a_Branch_1_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 192, 3, strides=1, padding="same", use_bias=False, name="Mixed_6a_Branch_1_Conv2d_0b_3x3"
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Mixed_6a_Branch_1_Conv2d_0b_3x3_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Mixed_6a_Branch_1_Conv2d_0b_3x3_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 256, 3, strides=2, padding="valid", use_bias=False, name="Mixed_6a_Branch_1_Conv2d_1a_3x3"
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Mixed_6a_Branch_1_Conv2d_1a_3x3_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Mixed_6a_Branch_1_Conv2d_1a_3x3_Activation")(branch_1)
+ branch_pool = MaxPooling2D(
+ 3, strides=2, padding="valid", name="Mixed_6a_Branch_2_MaxPool_1a_3x3"
+ )(x)
+ branches = [branch_0, branch_1, branch_pool]
+ x = Concatenate(axis=3, name="Mixed_6a")(branches)
+
+ # 10x Block17 (Inception-ResNet-B block):
+ branch_0 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_1_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_1_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block17_1_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_1_Branch_1_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_1_Branch_1_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_1_Branch_1_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [1, 7],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_1_Branch_1_Conv2d_0b_1x7",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_1_Branch_1_Conv2d_0b_1x7_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_1_Branch_1_Conv2d_0b_1x7_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [7, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_1_Branch_1_Conv2d_0c_7x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_1_Branch_1_Conv2d_0c_7x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_1_Branch_1_Conv2d_0c_7x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block17_1_Concatenate")(branches)
+ up = Conv2D(896, 1, strides=1, padding="same", use_bias=True, name="Block17_1_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.1})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block17_1_Activation")(x)
+
+ branch_0 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_2_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_2_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block17_2_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_2_Branch_2_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_2_Branch_2_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_2_Branch_2_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [1, 7],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_2_Branch_2_Conv2d_0b_1x7",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_2_Branch_2_Conv2d_0b_1x7_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_2_Branch_2_Conv2d_0b_1x7_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [7, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_2_Branch_2_Conv2d_0c_7x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_2_Branch_2_Conv2d_0c_7x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_2_Branch_2_Conv2d_0c_7x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block17_2_Concatenate")(branches)
+ up = Conv2D(896, 1, strides=1, padding="same", use_bias=True, name="Block17_2_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.1})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block17_2_Activation")(x)
+
+ branch_0 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_3_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_3_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block17_3_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_3_Branch_3_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_3_Branch_3_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_3_Branch_3_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [1, 7],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_3_Branch_3_Conv2d_0b_1x7",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_3_Branch_3_Conv2d_0b_1x7_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_3_Branch_3_Conv2d_0b_1x7_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [7, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_3_Branch_3_Conv2d_0c_7x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_3_Branch_3_Conv2d_0c_7x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_3_Branch_3_Conv2d_0c_7x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block17_3_Concatenate")(branches)
+ up = Conv2D(896, 1, strides=1, padding="same", use_bias=True, name="Block17_3_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.1})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block17_3_Activation")(x)
+
+ branch_0 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_4_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_4_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block17_4_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_4_Branch_4_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_4_Branch_4_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_4_Branch_4_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [1, 7],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_4_Branch_4_Conv2d_0b_1x7",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_4_Branch_4_Conv2d_0b_1x7_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_4_Branch_4_Conv2d_0b_1x7_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [7, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_4_Branch_4_Conv2d_0c_7x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_4_Branch_4_Conv2d_0c_7x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_4_Branch_4_Conv2d_0c_7x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block17_4_Concatenate")(branches)
+ up = Conv2D(896, 1, strides=1, padding="same", use_bias=True, name="Block17_4_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.1})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block17_4_Activation")(x)
+
+ branch_0 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_5_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_5_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block17_5_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_5_Branch_5_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_5_Branch_5_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_5_Branch_5_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [1, 7],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_5_Branch_5_Conv2d_0b_1x7",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_5_Branch_5_Conv2d_0b_1x7_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_5_Branch_5_Conv2d_0b_1x7_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [7, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_5_Branch_5_Conv2d_0c_7x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_5_Branch_5_Conv2d_0c_7x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_5_Branch_5_Conv2d_0c_7x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block17_5_Concatenate")(branches)
+ up = Conv2D(896, 1, strides=1, padding="same", use_bias=True, name="Block17_5_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.1})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block17_5_Activation")(x)
+
+ branch_0 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_6_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_6_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block17_6_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_6_Branch_6_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_6_Branch_6_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_6_Branch_6_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [1, 7],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_6_Branch_6_Conv2d_0b_1x7",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_6_Branch_6_Conv2d_0b_1x7_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_6_Branch_6_Conv2d_0b_1x7_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [7, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_6_Branch_6_Conv2d_0c_7x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_6_Branch_6_Conv2d_0c_7x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_6_Branch_6_Conv2d_0c_7x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block17_6_Concatenate")(branches)
+ up = Conv2D(896, 1, strides=1, padding="same", use_bias=True, name="Block17_6_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.1})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block17_6_Activation")(x)
+
+ branch_0 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_7_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_7_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block17_7_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_7_Branch_7_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_7_Branch_7_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_7_Branch_7_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [1, 7],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_7_Branch_7_Conv2d_0b_1x7",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_7_Branch_7_Conv2d_0b_1x7_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_7_Branch_7_Conv2d_0b_1x7_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [7, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_7_Branch_7_Conv2d_0c_7x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_7_Branch_7_Conv2d_0c_7x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_7_Branch_7_Conv2d_0c_7x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block17_7_Concatenate")(branches)
+ up = Conv2D(896, 1, strides=1, padding="same", use_bias=True, name="Block17_7_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.1})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block17_7_Activation")(x)
+
+ branch_0 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_8_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_8_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block17_8_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_8_Branch_8_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_8_Branch_8_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_8_Branch_8_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [1, 7],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_8_Branch_8_Conv2d_0b_1x7",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_8_Branch_8_Conv2d_0b_1x7_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_8_Branch_8_Conv2d_0b_1x7_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [7, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_8_Branch_8_Conv2d_0c_7x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_8_Branch_8_Conv2d_0c_7x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_8_Branch_8_Conv2d_0c_7x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block17_8_Concatenate")(branches)
+ up = Conv2D(896, 1, strides=1, padding="same", use_bias=True, name="Block17_8_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.1})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block17_8_Activation")(x)
+
+ branch_0 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_9_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_9_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block17_9_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_9_Branch_9_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_9_Branch_9_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_9_Branch_9_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [1, 7],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_9_Branch_9_Conv2d_0b_1x7",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_9_Branch_9_Conv2d_0b_1x7_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_9_Branch_9_Conv2d_0b_1x7_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [7, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_9_Branch_9_Conv2d_0c_7x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_9_Branch_9_Conv2d_0c_7x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_9_Branch_9_Conv2d_0c_7x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block17_9_Concatenate")(branches)
+ up = Conv2D(896, 1, strides=1, padding="same", use_bias=True, name="Block17_9_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.1})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block17_9_Activation")(x)
+
+ branch_0 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_10_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_10_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block17_10_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 128, 1, strides=1, padding="same", use_bias=False, name="Block17_10_Branch_10_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_10_Branch_10_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_10_Branch_10_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [1, 7],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_10_Branch_10_Conv2d_0b_1x7",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_10_Branch_10_Conv2d_0b_1x7_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_10_Branch_10_Conv2d_0b_1x7_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 128,
+ [7, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block17_10_Branch_10_Conv2d_0c_7x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block17_10_Branch_10_Conv2d_0c_7x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block17_10_Branch_10_Conv2d_0c_7x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block17_10_Concatenate")(branches)
+ up = Conv2D(896, 1, strides=1, padding="same", use_bias=True, name="Block17_10_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.1})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block17_10_Activation")(x)
+
+ # Mixed 7a (Reduction-B block): 8 x 8 x 2080
+ branch_0 = Conv2D(
+ 256, 1, strides=1, padding="same", use_bias=False, name="Mixed_7a_Branch_0_Conv2d_0a_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Mixed_7a_Branch_0_Conv2d_0a_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Mixed_7a_Branch_0_Conv2d_0a_1x1_Activation")(branch_0)
+ branch_0 = Conv2D(
+ 384, 3, strides=2, padding="valid", use_bias=False, name="Mixed_7a_Branch_0_Conv2d_1a_3x3"
+ )(branch_0)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Mixed_7a_Branch_0_Conv2d_1a_3x3_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Mixed_7a_Branch_0_Conv2d_1a_3x3_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 256, 1, strides=1, padding="same", use_bias=False, name="Mixed_7a_Branch_1_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Mixed_7a_Branch_1_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Mixed_7a_Branch_1_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 256, 3, strides=2, padding="valid", use_bias=False, name="Mixed_7a_Branch_1_Conv2d_1a_3x3"
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Mixed_7a_Branch_1_Conv2d_1a_3x3_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Mixed_7a_Branch_1_Conv2d_1a_3x3_Activation")(branch_1)
+ branch_2 = Conv2D(
+ 256, 1, strides=1, padding="same", use_bias=False, name="Mixed_7a_Branch_2_Conv2d_0a_1x1"
+ )(x)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Mixed_7a_Branch_2_Conv2d_0a_1x1_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Mixed_7a_Branch_2_Conv2d_0a_1x1_Activation")(branch_2)
+ branch_2 = Conv2D(
+ 256, 3, strides=1, padding="same", use_bias=False, name="Mixed_7a_Branch_2_Conv2d_0b_3x3"
+ )(branch_2)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Mixed_7a_Branch_2_Conv2d_0b_3x3_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Mixed_7a_Branch_2_Conv2d_0b_3x3_Activation")(branch_2)
+ branch_2 = Conv2D(
+ 256, 3, strides=2, padding="valid", use_bias=False, name="Mixed_7a_Branch_2_Conv2d_1a_3x3"
+ )(branch_2)
+ branch_2 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Mixed_7a_Branch_2_Conv2d_1a_3x3_BatchNorm",
+ )(branch_2)
+ branch_2 = Activation("relu", name="Mixed_7a_Branch_2_Conv2d_1a_3x3_Activation")(branch_2)
+ branch_pool = MaxPooling2D(
+ 3, strides=2, padding="valid", name="Mixed_7a_Branch_3_MaxPool_1a_3x3"
+ )(x)
+ branches = [branch_0, branch_1, branch_2, branch_pool]
+ x = Concatenate(axis=3, name="Mixed_7a")(branches)
+
+ # 5x Block8 (Inception-ResNet-C block):
+
+ branch_0 = Conv2D(
+ 192, 1, strides=1, padding="same", use_bias=False, name="Block8_1_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_1_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block8_1_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 192, 1, strides=1, padding="same", use_bias=False, name="Block8_1_Branch_1_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_1_Branch_1_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_1_Branch_1_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 192,
+ [1, 3],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block8_1_Branch_1_Conv2d_0b_1x3",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_1_Branch_1_Conv2d_0b_1x3_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_1_Branch_1_Conv2d_0b_1x3_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 192,
+ [3, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block8_1_Branch_1_Conv2d_0c_3x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_1_Branch_1_Conv2d_0c_3x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_1_Branch_1_Conv2d_0c_3x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block8_1_Concatenate")(branches)
+ up = Conv2D(1792, 1, strides=1, padding="same", use_bias=True, name="Block8_1_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.2})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block8_1_Activation")(x)
+
+ branch_0 = Conv2D(
+ 192, 1, strides=1, padding="same", use_bias=False, name="Block8_2_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_2_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block8_2_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 192, 1, strides=1, padding="same", use_bias=False, name="Block8_2_Branch_2_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_2_Branch_2_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_2_Branch_2_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 192,
+ [1, 3],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block8_2_Branch_2_Conv2d_0b_1x3",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_2_Branch_2_Conv2d_0b_1x3_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_2_Branch_2_Conv2d_0b_1x3_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 192,
+ [3, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block8_2_Branch_2_Conv2d_0c_3x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_2_Branch_2_Conv2d_0c_3x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_2_Branch_2_Conv2d_0c_3x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block8_2_Concatenate")(branches)
+ up = Conv2D(1792, 1, strides=1, padding="same", use_bias=True, name="Block8_2_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.2})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block8_2_Activation")(x)
+
+ branch_0 = Conv2D(
+ 192, 1, strides=1, padding="same", use_bias=False, name="Block8_3_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_3_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block8_3_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 192, 1, strides=1, padding="same", use_bias=False, name="Block8_3_Branch_3_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_3_Branch_3_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_3_Branch_3_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 192,
+ [1, 3],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block8_3_Branch_3_Conv2d_0b_1x3",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_3_Branch_3_Conv2d_0b_1x3_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_3_Branch_3_Conv2d_0b_1x3_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 192,
+ [3, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block8_3_Branch_3_Conv2d_0c_3x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_3_Branch_3_Conv2d_0c_3x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_3_Branch_3_Conv2d_0c_3x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block8_3_Concatenate")(branches)
+ up = Conv2D(1792, 1, strides=1, padding="same", use_bias=True, name="Block8_3_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.2})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block8_3_Activation")(x)
+
+ branch_0 = Conv2D(
+ 192, 1, strides=1, padding="same", use_bias=False, name="Block8_4_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_4_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block8_4_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 192, 1, strides=1, padding="same", use_bias=False, name="Block8_4_Branch_4_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_4_Branch_4_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_4_Branch_4_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 192,
+ [1, 3],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block8_4_Branch_4_Conv2d_0b_1x3",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_4_Branch_4_Conv2d_0b_1x3_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_4_Branch_4_Conv2d_0b_1x3_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 192,
+ [3, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block8_4_Branch_4_Conv2d_0c_3x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_4_Branch_4_Conv2d_0c_3x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_4_Branch_4_Conv2d_0c_3x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block8_4_Concatenate")(branches)
+ up = Conv2D(1792, 1, strides=1, padding="same", use_bias=True, name="Block8_4_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.2})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block8_4_Activation")(x)
+
+ branch_0 = Conv2D(
+ 192, 1, strides=1, padding="same", use_bias=False, name="Block8_5_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_5_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block8_5_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 192, 1, strides=1, padding="same", use_bias=False, name="Block8_5_Branch_5_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_5_Branch_5_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_5_Branch_5_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 192,
+ [1, 3],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block8_5_Branch_5_Conv2d_0b_1x3",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_5_Branch_5_Conv2d_0b_1x3_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_5_Branch_5_Conv2d_0b_1x3_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 192,
+ [3, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block8_5_Branch_5_Conv2d_0c_3x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_5_Branch_5_Conv2d_0c_3x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_5_Branch_5_Conv2d_0c_3x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block8_5_Concatenate")(branches)
+ up = Conv2D(1792, 1, strides=1, padding="same", use_bias=True, name="Block8_5_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 0.2})(up)
+ x = add([x, up])
+ x = Activation("relu", name="Block8_5_Activation")(x)
+
+ branch_0 = Conv2D(
+ 192, 1, strides=1, padding="same", use_bias=False, name="Block8_6_Branch_0_Conv2d_1x1"
+ )(x)
+ branch_0 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_6_Branch_0_Conv2d_1x1_BatchNorm",
+ )(branch_0)
+ branch_0 = Activation("relu", name="Block8_6_Branch_0_Conv2d_1x1_Activation")(branch_0)
+ branch_1 = Conv2D(
+ 192, 1, strides=1, padding="same", use_bias=False, name="Block8_6_Branch_1_Conv2d_0a_1x1"
+ )(x)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_6_Branch_1_Conv2d_0a_1x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_6_Branch_1_Conv2d_0a_1x1_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 192,
+ [1, 3],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block8_6_Branch_1_Conv2d_0b_1x3",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_6_Branch_1_Conv2d_0b_1x3_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_6_Branch_1_Conv2d_0b_1x3_Activation")(branch_1)
+ branch_1 = Conv2D(
+ 192,
+ [3, 1],
+ strides=1,
+ padding="same",
+ use_bias=False,
+ name="Block8_6_Branch_1_Conv2d_0c_3x1",
+ )(branch_1)
+ branch_1 = BatchNormalization(
+ axis=3,
+ momentum=0.995,
+ epsilon=0.001,
+ scale=False,
+ name="Block8_6_Branch_1_Conv2d_0c_3x1_BatchNorm",
+ )(branch_1)
+ branch_1 = Activation("relu", name="Block8_6_Branch_1_Conv2d_0c_3x1_Activation")(branch_1)
+ branches = [branch_0, branch_1]
+ mixed = Concatenate(axis=3, name="Block8_6_Concatenate")(branches)
+ up = Conv2D(1792, 1, strides=1, padding="same", use_bias=True, name="Block8_6_Conv2d_1x1")(
+ mixed
+ )
+ up = Lambda(scaling, output_shape=K.int_shape(up)[1:], arguments={"scale": 1})(up)
+ x = add([x, up])
+
+ # Classification block
+ x = GlobalAveragePooling2D(name="AvgPool")(x)
+ x = Dropout(1.0 - 0.8, name="Dropout")(x)
+ # Bottleneck
+ x = Dense(dimension, use_bias=False, name="Bottleneck")(x)
+ x = BatchNormalization(momentum=0.995, epsilon=0.001, scale=False, name="Bottleneck_BatchNorm")(
+ x
+ )
+
+ # Create model
+ model = Model(inputs, x, name="inception_resnet_v1")
+
+ return model
+
+
+def loadModel(
+ url="https://github.com/serengil/deepface_models/releases/download/v1.0/facenet_weights.h5",
+) -> Model:
+ model = InceptionResNetV2()
+
+ # -----------------------------------
+
+ home = functions.get_deepface_home()
+
+ if os.path.isfile(home + "/.deepface/weights/facenet_weights.h5") != True:
+ logger.info("facenet_weights.h5 will be downloaded...")
+
+ output = home + "/.deepface/weights/facenet_weights.h5"
+ gdown.download(url, output, quiet=False)
+
+ # -----------------------------------
+
+ model.load_weights(home + "/.deepface/weights/facenet_weights.h5")
+
+ # -----------------------------------
+
+ return model
diff --git a/modules/deepface-master/deepface/basemodels/Facenet512.py b/modules/deepface-master/deepface/basemodels/Facenet512.py
new file mode 100644
index 000000000..95aca65e9
--- /dev/null
+++ b/modules/deepface-master/deepface/basemodels/Facenet512.py
@@ -0,0 +1,40 @@
+import os
+import gdown
+import tensorflow as tf
+from deepface.basemodels import Facenet
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="basemodels.Facenet512")
+
+tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
+
+if tf_version == 1:
+ from keras.models import Model
+else:
+ from tensorflow.keras.models import Model
+
+
+def loadModel(
+ url="https://github.com/serengil/deepface_models/releases/download/v1.0/facenet512_weights.h5",
+) -> Model:
+
+ model = Facenet.InceptionResNetV2(dimension=512)
+
+ # -------------------------
+
+ home = functions.get_deepface_home()
+
+ if os.path.isfile(home + "/.deepface/weights/facenet512_weights.h5") != True:
+ logger.info("facenet512_weights.h5 will be downloaded...")
+
+ output = home + "/.deepface/weights/facenet512_weights.h5"
+ gdown.download(url, output, quiet=False)
+
+ # -------------------------
+
+ model.load_weights(home + "/.deepface/weights/facenet512_weights.h5")
+
+ # -------------------------
+
+ return model
diff --git a/modules/deepface-master/deepface/basemodels/FbDeepFace.py b/modules/deepface-master/deepface/basemodels/FbDeepFace.py
new file mode 100644
index 000000000..9f66a80ed
--- /dev/null
+++ b/modules/deepface-master/deepface/basemodels/FbDeepFace.py
@@ -0,0 +1,78 @@
+import os
+import zipfile
+import gdown
+import tensorflow as tf
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="basemodels.FbDeepFace")
+
+# --------------------------------
+# dependency configuration
+
+tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
+
+if tf_version == 1:
+ from keras.models import Model, Sequential
+ from keras.layers import (
+ Convolution2D,
+ LocallyConnected2D,
+ MaxPooling2D,
+ Flatten,
+ Dense,
+ Dropout,
+ )
+else:
+ from tensorflow.keras.models import Model, Sequential
+ from tensorflow.keras.layers import (
+ Convolution2D,
+ LocallyConnected2D,
+ MaxPooling2D,
+ Flatten,
+ Dense,
+ Dropout,
+ )
+
+
+# -------------------------------------
+# pylint: disable=line-too-long
+
+
+def loadModel(
+ url="https://github.com/swghosh/DeepFace/releases/download/weights-vggface2-2d-aligned/VGGFace2_DeepFace_weights_val-0.9034.h5.zip",
+) -> Model:
+ base_model = Sequential()
+ base_model.add(
+ Convolution2D(32, (11, 11), activation="relu", name="C1", input_shape=(152, 152, 3))
+ )
+ base_model.add(MaxPooling2D(pool_size=3, strides=2, padding="same", name="M2"))
+ base_model.add(Convolution2D(16, (9, 9), activation="relu", name="C3"))
+ base_model.add(LocallyConnected2D(16, (9, 9), activation="relu", name="L4"))
+ base_model.add(LocallyConnected2D(16, (7, 7), strides=2, activation="relu", name="L5"))
+ base_model.add(LocallyConnected2D(16, (5, 5), activation="relu", name="L6"))
+ base_model.add(Flatten(name="F0"))
+ base_model.add(Dense(4096, activation="relu", name="F7"))
+ base_model.add(Dropout(rate=0.5, name="D0"))
+ base_model.add(Dense(8631, activation="softmax", name="F8"))
+
+ # ---------------------------------
+
+ home = functions.get_deepface_home()
+
+ if os.path.isfile(home + "/.deepface/weights/VGGFace2_DeepFace_weights_val-0.9034.h5") != True:
+ logger.info("VGGFace2_DeepFace_weights_val-0.9034.h5 will be downloaded...")
+
+ output = home + "/.deepface/weights/VGGFace2_DeepFace_weights_val-0.9034.h5.zip"
+
+ gdown.download(url, output, quiet=False)
+
+ # unzip VGGFace2_DeepFace_weights_val-0.9034.h5.zip
+ with zipfile.ZipFile(output, "r") as zip_ref:
+ zip_ref.extractall(home + "/.deepface/weights/")
+
+ base_model.load_weights(home + "/.deepface/weights/VGGFace2_DeepFace_weights_val-0.9034.h5")
+
+ # drop F8 and D0. F7 is the representation layer.
+ deepface_model = Model(inputs=base_model.layers[0].input, outputs=base_model.layers[-3].output)
+
+ return deepface_model
diff --git a/modules/deepface-master/deepface/basemodels/OpenFace.py b/modules/deepface-master/deepface/basemodels/OpenFace.py
new file mode 100644
index 000000000..9ba161e7f
--- /dev/null
+++ b/modules/deepface-master/deepface/basemodels/OpenFace.py
@@ -0,0 +1,379 @@
+import os
+import gdown
+import tensorflow as tf
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="basemodels.OpenFace")
+
+tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
+if tf_version == 1:
+ from keras.models import Model
+ from keras.layers import Conv2D, ZeroPadding2D, Input, concatenate
+ from keras.layers import Dense, Activation, Lambda, Flatten, BatchNormalization
+ from keras.layers import MaxPooling2D, AveragePooling2D
+ from keras import backend as K
+else:
+ from tensorflow.keras.models import Model
+ from tensorflow.keras.layers import Conv2D, ZeroPadding2D, Input, concatenate
+ from tensorflow.keras.layers import Dense, Activation, Lambda, Flatten, BatchNormalization
+ from tensorflow.keras.layers import MaxPooling2D, AveragePooling2D
+ from tensorflow.keras import backend as K
+
+# pylint: disable=unnecessary-lambda
+
+# ---------------------------------------
+
+
+def loadModel(
+ url="https://github.com/serengil/deepface_models/releases/download/v1.0/openface_weights.h5",
+) -> Model:
+ myInput = Input(shape=(96, 96, 3))
+
+ x = ZeroPadding2D(padding=(3, 3), input_shape=(96, 96, 3))(myInput)
+ x = Conv2D(64, (7, 7), strides=(2, 2), name="conv1")(x)
+ x = BatchNormalization(axis=3, epsilon=0.00001, name="bn1")(x)
+ x = Activation("relu")(x)
+ x = ZeroPadding2D(padding=(1, 1))(x)
+ x = MaxPooling2D(pool_size=3, strides=2)(x)
+ x = Lambda(lambda x: tf.nn.lrn(x, alpha=1e-4, beta=0.75), name="lrn_1")(x)
+ x = Conv2D(64, (1, 1), name="conv2")(x)
+ x = BatchNormalization(axis=3, epsilon=0.00001, name="bn2")(x)
+ x = Activation("relu")(x)
+ x = ZeroPadding2D(padding=(1, 1))(x)
+ x = Conv2D(192, (3, 3), name="conv3")(x)
+ x = BatchNormalization(axis=3, epsilon=0.00001, name="bn3")(x)
+ x = Activation("relu")(x)
+ x = Lambda(lambda x: tf.nn.lrn(x, alpha=1e-4, beta=0.75), name="lrn_2")(x) # x is equal added
+ x = ZeroPadding2D(padding=(1, 1))(x)
+ x = MaxPooling2D(pool_size=3, strides=2)(x)
+
+ # Inception3a
+ inception_3a_3x3 = Conv2D(96, (1, 1), name="inception_3a_3x3_conv1")(x)
+ inception_3a_3x3 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_3a_3x3_bn1")(
+ inception_3a_3x3
+ )
+ inception_3a_3x3 = Activation("relu")(inception_3a_3x3)
+ inception_3a_3x3 = ZeroPadding2D(padding=(1, 1))(inception_3a_3x3)
+ inception_3a_3x3 = Conv2D(128, (3, 3), name="inception_3a_3x3_conv2")(inception_3a_3x3)
+ inception_3a_3x3 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_3a_3x3_bn2")(
+ inception_3a_3x3
+ )
+ inception_3a_3x3 = Activation("relu")(inception_3a_3x3)
+
+ inception_3a_5x5 = Conv2D(16, (1, 1), name="inception_3a_5x5_conv1")(x)
+ inception_3a_5x5 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_3a_5x5_bn1")(
+ inception_3a_5x5
+ )
+ inception_3a_5x5 = Activation("relu")(inception_3a_5x5)
+ inception_3a_5x5 = ZeroPadding2D(padding=(2, 2))(inception_3a_5x5)
+ inception_3a_5x5 = Conv2D(32, (5, 5), name="inception_3a_5x5_conv2")(inception_3a_5x5)
+ inception_3a_5x5 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_3a_5x5_bn2")(
+ inception_3a_5x5
+ )
+ inception_3a_5x5 = Activation("relu")(inception_3a_5x5)
+
+ inception_3a_pool = MaxPooling2D(pool_size=3, strides=2)(x)
+ inception_3a_pool = Conv2D(32, (1, 1), name="inception_3a_pool_conv")(inception_3a_pool)
+ inception_3a_pool = BatchNormalization(axis=3, epsilon=0.00001, name="inception_3a_pool_bn")(
+ inception_3a_pool
+ )
+ inception_3a_pool = Activation("relu")(inception_3a_pool)
+ inception_3a_pool = ZeroPadding2D(padding=((3, 4), (3, 4)))(inception_3a_pool)
+
+ inception_3a_1x1 = Conv2D(64, (1, 1), name="inception_3a_1x1_conv")(x)
+ inception_3a_1x1 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_3a_1x1_bn")(
+ inception_3a_1x1
+ )
+ inception_3a_1x1 = Activation("relu")(inception_3a_1x1)
+
+ inception_3a = concatenate(
+ [inception_3a_3x3, inception_3a_5x5, inception_3a_pool, inception_3a_1x1], axis=3
+ )
+
+ # Inception3b
+ inception_3b_3x3 = Conv2D(96, (1, 1), name="inception_3b_3x3_conv1")(inception_3a)
+ inception_3b_3x3 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_3b_3x3_bn1")(
+ inception_3b_3x3
+ )
+ inception_3b_3x3 = Activation("relu")(inception_3b_3x3)
+ inception_3b_3x3 = ZeroPadding2D(padding=(1, 1))(inception_3b_3x3)
+ inception_3b_3x3 = Conv2D(128, (3, 3), name="inception_3b_3x3_conv2")(inception_3b_3x3)
+ inception_3b_3x3 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_3b_3x3_bn2")(
+ inception_3b_3x3
+ )
+ inception_3b_3x3 = Activation("relu")(inception_3b_3x3)
+
+ inception_3b_5x5 = Conv2D(32, (1, 1), name="inception_3b_5x5_conv1")(inception_3a)
+ inception_3b_5x5 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_3b_5x5_bn1")(
+ inception_3b_5x5
+ )
+ inception_3b_5x5 = Activation("relu")(inception_3b_5x5)
+ inception_3b_5x5 = ZeroPadding2D(padding=(2, 2))(inception_3b_5x5)
+ inception_3b_5x5 = Conv2D(64, (5, 5), name="inception_3b_5x5_conv2")(inception_3b_5x5)
+ inception_3b_5x5 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_3b_5x5_bn2")(
+ inception_3b_5x5
+ )
+ inception_3b_5x5 = Activation("relu")(inception_3b_5x5)
+
+ inception_3b_pool = Lambda(lambda x: x**2, name="power2_3b")(inception_3a)
+ inception_3b_pool = AveragePooling2D(pool_size=(3, 3), strides=(3, 3))(inception_3b_pool)
+ inception_3b_pool = Lambda(lambda x: x * 9, name="mult9_3b")(inception_3b_pool)
+ inception_3b_pool = Lambda(lambda x: K.sqrt(x), name="sqrt_3b")(inception_3b_pool)
+ inception_3b_pool = Conv2D(64, (1, 1), name="inception_3b_pool_conv")(inception_3b_pool)
+ inception_3b_pool = BatchNormalization(axis=3, epsilon=0.00001, name="inception_3b_pool_bn")(
+ inception_3b_pool
+ )
+ inception_3b_pool = Activation("relu")(inception_3b_pool)
+ inception_3b_pool = ZeroPadding2D(padding=(4, 4))(inception_3b_pool)
+
+ inception_3b_1x1 = Conv2D(64, (1, 1), name="inception_3b_1x1_conv")(inception_3a)
+ inception_3b_1x1 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_3b_1x1_bn")(
+ inception_3b_1x1
+ )
+ inception_3b_1x1 = Activation("relu")(inception_3b_1x1)
+
+ inception_3b = concatenate(
+ [inception_3b_3x3, inception_3b_5x5, inception_3b_pool, inception_3b_1x1], axis=3
+ )
+
+ # Inception3c
+ inception_3c_3x3 = Conv2D(128, (1, 1), strides=(1, 1), name="inception_3c_3x3_conv1")(
+ inception_3b
+ )
+ inception_3c_3x3 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_3c_3x3_bn1")(
+ inception_3c_3x3
+ )
+ inception_3c_3x3 = Activation("relu")(inception_3c_3x3)
+ inception_3c_3x3 = ZeroPadding2D(padding=(1, 1))(inception_3c_3x3)
+ inception_3c_3x3 = Conv2D(256, (3, 3), strides=(2, 2), name="inception_3c_3x3_conv" + "2")(
+ inception_3c_3x3
+ )
+ inception_3c_3x3 = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_3c_3x3_bn" + "2"
+ )(inception_3c_3x3)
+ inception_3c_3x3 = Activation("relu")(inception_3c_3x3)
+
+ inception_3c_5x5 = Conv2D(32, (1, 1), strides=(1, 1), name="inception_3c_5x5_conv1")(
+ inception_3b
+ )
+ inception_3c_5x5 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_3c_5x5_bn1")(
+ inception_3c_5x5
+ )
+ inception_3c_5x5 = Activation("relu")(inception_3c_5x5)
+ inception_3c_5x5 = ZeroPadding2D(padding=(2, 2))(inception_3c_5x5)
+ inception_3c_5x5 = Conv2D(64, (5, 5), strides=(2, 2), name="inception_3c_5x5_conv" + "2")(
+ inception_3c_5x5
+ )
+ inception_3c_5x5 = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_3c_5x5_bn" + "2"
+ )(inception_3c_5x5)
+ inception_3c_5x5 = Activation("relu")(inception_3c_5x5)
+
+ inception_3c_pool = MaxPooling2D(pool_size=3, strides=2)(inception_3b)
+ inception_3c_pool = ZeroPadding2D(padding=((0, 1), (0, 1)))(inception_3c_pool)
+
+ inception_3c = concatenate([inception_3c_3x3, inception_3c_5x5, inception_3c_pool], axis=3)
+
+ # inception 4a
+ inception_4a_3x3 = Conv2D(96, (1, 1), strides=(1, 1), name="inception_4a_3x3_conv" + "1")(
+ inception_3c
+ )
+ inception_4a_3x3 = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_4a_3x3_bn" + "1"
+ )(inception_4a_3x3)
+ inception_4a_3x3 = Activation("relu")(inception_4a_3x3)
+ inception_4a_3x3 = ZeroPadding2D(padding=(1, 1))(inception_4a_3x3)
+ inception_4a_3x3 = Conv2D(192, (3, 3), strides=(1, 1), name="inception_4a_3x3_conv" + "2")(
+ inception_4a_3x3
+ )
+ inception_4a_3x3 = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_4a_3x3_bn" + "2"
+ )(inception_4a_3x3)
+ inception_4a_3x3 = Activation("relu")(inception_4a_3x3)
+
+ inception_4a_5x5 = Conv2D(32, (1, 1), strides=(1, 1), name="inception_4a_5x5_conv1")(
+ inception_3c
+ )
+ inception_4a_5x5 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_4a_5x5_bn1")(
+ inception_4a_5x5
+ )
+ inception_4a_5x5 = Activation("relu")(inception_4a_5x5)
+ inception_4a_5x5 = ZeroPadding2D(padding=(2, 2))(inception_4a_5x5)
+ inception_4a_5x5 = Conv2D(64, (5, 5), strides=(1, 1), name="inception_4a_5x5_conv" + "2")(
+ inception_4a_5x5
+ )
+ inception_4a_5x5 = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_4a_5x5_bn" + "2"
+ )(inception_4a_5x5)
+ inception_4a_5x5 = Activation("relu")(inception_4a_5x5)
+
+ inception_4a_pool = Lambda(lambda x: x**2, name="power2_4a")(inception_3c)
+ inception_4a_pool = AveragePooling2D(pool_size=(3, 3), strides=(3, 3))(inception_4a_pool)
+ inception_4a_pool = Lambda(lambda x: x * 9, name="mult9_4a")(inception_4a_pool)
+ inception_4a_pool = Lambda(lambda x: K.sqrt(x), name="sqrt_4a")(inception_4a_pool)
+
+ inception_4a_pool = Conv2D(128, (1, 1), strides=(1, 1), name="inception_4a_pool_conv" + "")(
+ inception_4a_pool
+ )
+ inception_4a_pool = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_4a_pool_bn" + ""
+ )(inception_4a_pool)
+ inception_4a_pool = Activation("relu")(inception_4a_pool)
+ inception_4a_pool = ZeroPadding2D(padding=(2, 2))(inception_4a_pool)
+
+ inception_4a_1x1 = Conv2D(256, (1, 1), strides=(1, 1), name="inception_4a_1x1_conv" + "")(
+ inception_3c
+ )
+ inception_4a_1x1 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_4a_1x1_bn" + "")(
+ inception_4a_1x1
+ )
+ inception_4a_1x1 = Activation("relu")(inception_4a_1x1)
+
+ inception_4a = concatenate(
+ [inception_4a_3x3, inception_4a_5x5, inception_4a_pool, inception_4a_1x1], axis=3
+ )
+
+ # inception4e
+ inception_4e_3x3 = Conv2D(160, (1, 1), strides=(1, 1), name="inception_4e_3x3_conv" + "1")(
+ inception_4a
+ )
+ inception_4e_3x3 = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_4e_3x3_bn" + "1"
+ )(inception_4e_3x3)
+ inception_4e_3x3 = Activation("relu")(inception_4e_3x3)
+ inception_4e_3x3 = ZeroPadding2D(padding=(1, 1))(inception_4e_3x3)
+ inception_4e_3x3 = Conv2D(256, (3, 3), strides=(2, 2), name="inception_4e_3x3_conv" + "2")(
+ inception_4e_3x3
+ )
+ inception_4e_3x3 = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_4e_3x3_bn" + "2"
+ )(inception_4e_3x3)
+ inception_4e_3x3 = Activation("relu")(inception_4e_3x3)
+
+ inception_4e_5x5 = Conv2D(64, (1, 1), strides=(1, 1), name="inception_4e_5x5_conv" + "1")(
+ inception_4a
+ )
+ inception_4e_5x5 = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_4e_5x5_bn" + "1"
+ )(inception_4e_5x5)
+ inception_4e_5x5 = Activation("relu")(inception_4e_5x5)
+ inception_4e_5x5 = ZeroPadding2D(padding=(2, 2))(inception_4e_5x5)
+ inception_4e_5x5 = Conv2D(128, (5, 5), strides=(2, 2), name="inception_4e_5x5_conv" + "2")(
+ inception_4e_5x5
+ )
+ inception_4e_5x5 = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_4e_5x5_bn" + "2"
+ )(inception_4e_5x5)
+ inception_4e_5x5 = Activation("relu")(inception_4e_5x5)
+
+ inception_4e_pool = MaxPooling2D(pool_size=3, strides=2)(inception_4a)
+ inception_4e_pool = ZeroPadding2D(padding=((0, 1), (0, 1)))(inception_4e_pool)
+
+ inception_4e = concatenate([inception_4e_3x3, inception_4e_5x5, inception_4e_pool], axis=3)
+
+ # inception5a
+ inception_5a_3x3 = Conv2D(96, (1, 1), strides=(1, 1), name="inception_5a_3x3_conv" + "1")(
+ inception_4e
+ )
+ inception_5a_3x3 = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_5a_3x3_bn" + "1"
+ )(inception_5a_3x3)
+ inception_5a_3x3 = Activation("relu")(inception_5a_3x3)
+ inception_5a_3x3 = ZeroPadding2D(padding=(1, 1))(inception_5a_3x3)
+ inception_5a_3x3 = Conv2D(384, (3, 3), strides=(1, 1), name="inception_5a_3x3_conv" + "2")(
+ inception_5a_3x3
+ )
+ inception_5a_3x3 = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_5a_3x3_bn" + "2"
+ )(inception_5a_3x3)
+ inception_5a_3x3 = Activation("relu")(inception_5a_3x3)
+
+ inception_5a_pool = Lambda(lambda x: x**2, name="power2_5a")(inception_4e)
+ inception_5a_pool = AveragePooling2D(pool_size=(3, 3), strides=(3, 3))(inception_5a_pool)
+ inception_5a_pool = Lambda(lambda x: x * 9, name="mult9_5a")(inception_5a_pool)
+ inception_5a_pool = Lambda(lambda x: K.sqrt(x), name="sqrt_5a")(inception_5a_pool)
+
+ inception_5a_pool = Conv2D(96, (1, 1), strides=(1, 1), name="inception_5a_pool_conv" + "")(
+ inception_5a_pool
+ )
+ inception_5a_pool = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_5a_pool_bn" + ""
+ )(inception_5a_pool)
+ inception_5a_pool = Activation("relu")(inception_5a_pool)
+ inception_5a_pool = ZeroPadding2D(padding=(1, 1))(inception_5a_pool)
+
+ inception_5a_1x1 = Conv2D(256, (1, 1), strides=(1, 1), name="inception_5a_1x1_conv" + "")(
+ inception_4e
+ )
+ inception_5a_1x1 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_5a_1x1_bn" + "")(
+ inception_5a_1x1
+ )
+ inception_5a_1x1 = Activation("relu")(inception_5a_1x1)
+
+ inception_5a = concatenate([inception_5a_3x3, inception_5a_pool, inception_5a_1x1], axis=3)
+
+ # inception_5b
+ inception_5b_3x3 = Conv2D(96, (1, 1), strides=(1, 1), name="inception_5b_3x3_conv" + "1")(
+ inception_5a
+ )
+ inception_5b_3x3 = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_5b_3x3_bn" + "1"
+ )(inception_5b_3x3)
+ inception_5b_3x3 = Activation("relu")(inception_5b_3x3)
+ inception_5b_3x3 = ZeroPadding2D(padding=(1, 1))(inception_5b_3x3)
+ inception_5b_3x3 = Conv2D(384, (3, 3), strides=(1, 1), name="inception_5b_3x3_conv" + "2")(
+ inception_5b_3x3
+ )
+ inception_5b_3x3 = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_5b_3x3_bn" + "2"
+ )(inception_5b_3x3)
+ inception_5b_3x3 = Activation("relu")(inception_5b_3x3)
+
+ inception_5b_pool = MaxPooling2D(pool_size=3, strides=2)(inception_5a)
+
+ inception_5b_pool = Conv2D(96, (1, 1), strides=(1, 1), name="inception_5b_pool_conv" + "")(
+ inception_5b_pool
+ )
+ inception_5b_pool = BatchNormalization(
+ axis=3, epsilon=0.00001, name="inception_5b_pool_bn" + ""
+ )(inception_5b_pool)
+ inception_5b_pool = Activation("relu")(inception_5b_pool)
+
+ inception_5b_pool = ZeroPadding2D(padding=(1, 1))(inception_5b_pool)
+
+ inception_5b_1x1 = Conv2D(256, (1, 1), strides=(1, 1), name="inception_5b_1x1_conv" + "")(
+ inception_5a
+ )
+ inception_5b_1x1 = BatchNormalization(axis=3, epsilon=0.00001, name="inception_5b_1x1_bn" + "")(
+ inception_5b_1x1
+ )
+ inception_5b_1x1 = Activation("relu")(inception_5b_1x1)
+
+ inception_5b = concatenate([inception_5b_3x3, inception_5b_pool, inception_5b_1x1], axis=3)
+
+ av_pool = AveragePooling2D(pool_size=(3, 3), strides=(1, 1))(inception_5b)
+ reshape_layer = Flatten()(av_pool)
+ dense_layer = Dense(128, name="dense_layer")(reshape_layer)
+ norm_layer = Lambda(lambda x: K.l2_normalize(x, axis=1), name="norm_layer")(dense_layer)
+
+ # Final Model
+ model = Model(inputs=[myInput], outputs=norm_layer)
+
+ # -----------------------------------
+
+ home = functions.get_deepface_home()
+
+ if os.path.isfile(home + "/.deepface/weights/openface_weights.h5") != True:
+ logger.info("openface_weights.h5 will be downloaded...")
+
+ output = home + "/.deepface/weights/openface_weights.h5"
+ gdown.download(url, output, quiet=False)
+
+ # -----------------------------------
+
+ model.load_weights(home + "/.deepface/weights/openface_weights.h5")
+
+ # -----------------------------------
+
+ return model
diff --git a/modules/deepface-master/deepface/basemodels/SFace.py b/modules/deepface-master/deepface/basemodels/SFace.py
new file mode 100644
index 000000000..90b305cdb
--- /dev/null
+++ b/modules/deepface-master/deepface/basemodels/SFace.py
@@ -0,0 +1,65 @@
+import os
+from typing import Any
+
+import numpy as np
+import cv2 as cv
+import gdown
+
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="basemodels.SFace")
+
+# pylint: disable=line-too-long, too-few-public-methods
+
+
+class _Layer:
+ input_shape = (None, 112, 112, 3)
+ output_shape = (None, 1, 128)
+
+
+class SFaceModel:
+ def __init__(self, model_path):
+
+ try:
+ self.model = cv.FaceRecognizerSF.create(
+ model=model_path, config="", backend_id=0, target_id=0
+ )
+ except Exception as err:
+ raise ValueError(
+ "Exception while calling opencv.FaceRecognizerSF module."
+ + "This is an optional dependency."
+ + "You can install it as pip install opencv-contrib-python."
+ ) from err
+
+ self.layers = [_Layer()]
+
+ def predict(self, image: np.ndarray) -> np.ndarray:
+ # Preprocess
+ input_blob = (image[0] * 255).astype(
+ np.uint8
+ ) # revert the image to original format and preprocess using the model
+
+ # Forward
+ embeddings = self.model.feature(input_blob)
+
+ return embeddings
+
+
+def load_model(
+ url="https://github.com/opencv/opencv_zoo/raw/main/models/face_recognition_sface/face_recognition_sface_2021dec.onnx",
+) -> Any:
+
+ home = functions.get_deepface_home()
+
+ file_name = home + "/.deepface/weights/face_recognition_sface_2021dec.onnx"
+
+ if not os.path.isfile(file_name):
+
+ logger.info("sface weights will be downloaded...")
+
+ gdown.download(url, file_name, quiet=False)
+
+ model = SFaceModel(model_path=file_name)
+
+ return model
diff --git a/modules/deepface-master/deepface/basemodels/VGGFace.py b/modules/deepface-master/deepface/basemodels/VGGFace.py
new file mode 100644
index 000000000..a14942581
--- /dev/null
+++ b/modules/deepface-master/deepface/basemodels/VGGFace.py
@@ -0,0 +1,119 @@
+import os
+import gdown
+import tensorflow as tf
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="basemodels.VGGFace")
+
+# ---------------------------------------
+
+tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
+
+if tf_version == 1:
+ from keras.models import Model, Sequential
+ from keras.layers import (
+ Convolution2D,
+ ZeroPadding2D,
+ MaxPooling2D,
+ Flatten,
+ Dropout,
+ Activation,
+ Lambda,
+ )
+ from keras import backend as K
+else:
+ from tensorflow.keras.models import Model, Sequential
+ from tensorflow.keras.layers import (
+ Convolution2D,
+ ZeroPadding2D,
+ MaxPooling2D,
+ Flatten,
+ Dropout,
+ Activation,
+ Lambda,
+ )
+ from tensorflow.keras import backend as K
+
+# ---------------------------------------
+
+
+def baseModel() -> Sequential:
+ model = Sequential()
+ model.add(ZeroPadding2D((1, 1), input_shape=(224, 224, 3)))
+ model.add(Convolution2D(64, (3, 3), activation="relu"))
+ model.add(ZeroPadding2D((1, 1)))
+ model.add(Convolution2D(64, (3, 3), activation="relu"))
+ model.add(MaxPooling2D((2, 2), strides=(2, 2)))
+
+ model.add(ZeroPadding2D((1, 1)))
+ model.add(Convolution2D(128, (3, 3), activation="relu"))
+ model.add(ZeroPadding2D((1, 1)))
+ model.add(Convolution2D(128, (3, 3), activation="relu"))
+ model.add(MaxPooling2D((2, 2), strides=(2, 2)))
+
+ model.add(ZeroPadding2D((1, 1)))
+ model.add(Convolution2D(256, (3, 3), activation="relu"))
+ model.add(ZeroPadding2D((1, 1)))
+ model.add(Convolution2D(256, (3, 3), activation="relu"))
+ model.add(ZeroPadding2D((1, 1)))
+ model.add(Convolution2D(256, (3, 3), activation="relu"))
+ model.add(MaxPooling2D((2, 2), strides=(2, 2)))
+
+ model.add(ZeroPadding2D((1, 1)))
+ model.add(Convolution2D(512, (3, 3), activation="relu"))
+ model.add(ZeroPadding2D((1, 1)))
+ model.add(Convolution2D(512, (3, 3), activation="relu"))
+ model.add(ZeroPadding2D((1, 1)))
+ model.add(Convolution2D(512, (3, 3), activation="relu"))
+ model.add(MaxPooling2D((2, 2), strides=(2, 2)))
+
+ model.add(ZeroPadding2D((1, 1)))
+ model.add(Convolution2D(512, (3, 3), activation="relu"))
+ model.add(ZeroPadding2D((1, 1)))
+ model.add(Convolution2D(512, (3, 3), activation="relu"))
+ model.add(ZeroPadding2D((1, 1)))
+ model.add(Convolution2D(512, (3, 3), activation="relu"))
+ model.add(MaxPooling2D((2, 2), strides=(2, 2)))
+
+ model.add(Convolution2D(4096, (7, 7), activation="relu"))
+ model.add(Dropout(0.5))
+ model.add(Convolution2D(4096, (1, 1), activation="relu"))
+ model.add(Dropout(0.5))
+ model.add(Convolution2D(2622, (1, 1)))
+ model.add(Flatten())
+ model.add(Activation("softmax"))
+
+ return model
+
+
+def loadModel(
+ url="https://github.com/serengil/deepface_models/releases/download/v1.0/vgg_face_weights.h5",
+) -> Model:
+
+ model = baseModel()
+
+ home = functions.get_deepface_home()
+ output = home + "/.deepface/weights/vgg_face_weights.h5"
+
+ if os.path.isfile(output) != True:
+ logger.info("vgg_face_weights.h5 will be downloaded...")
+ gdown.download(url, output, quiet=False)
+
+ model.load_weights(output)
+
+ # 2622d dimensional model
+ # vgg_face_descriptor = Model(inputs=model.layers[0].input, outputs=model.layers[-2].output)
+
+ # 4096 dimensional model offers 6% to 14% increasement on accuracy!
+ # - softmax causes underfitting
+ # - added normalization layer to avoid underfitting with euclidean
+ # as described here: https://github.com/serengil/deepface/issues/944
+ base_model_output = Sequential()
+ base_model_output = Flatten()(model.layers[-5].output)
+ base_model_output = Lambda(lambda x: K.l2_normalize(x, axis=1), name="norm_layer")(
+ base_model_output
+ )
+ vgg_face_descriptor = Model(inputs=model.input, outputs=base_model_output)
+
+ return vgg_face_descriptor
diff --git a/modules/deepface-master/deepface/basemodels/__init__.py b/modules/deepface-master/deepface/basemodels/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/modules/deepface-master/deepface/commons/__init__.py b/modules/deepface-master/deepface/commons/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/modules/deepface-master/deepface/commons/distance.py b/modules/deepface-master/deepface/commons/distance.py
new file mode 100644
index 000000000..174473686
--- /dev/null
+++ b/modules/deepface-master/deepface/commons/distance.py
@@ -0,0 +1,62 @@
+from typing import Union
+import numpy as np
+
+
+def findCosineDistance(
+ source_representation: Union[np.ndarray, list], test_representation: Union[np.ndarray, list]
+) -> np.float64:
+ if isinstance(source_representation, list):
+ source_representation = np.array(source_representation)
+
+ if isinstance(test_representation, list):
+ test_representation = np.array(test_representation)
+
+ a = np.matmul(np.transpose(source_representation), test_representation)
+ b = np.sum(np.multiply(source_representation, source_representation))
+ c = np.sum(np.multiply(test_representation, test_representation))
+ return 1 - (a / (np.sqrt(b) * np.sqrt(c)))
+
+
+def findEuclideanDistance(
+ source_representation: Union[np.ndarray, list], test_representation: Union[np.ndarray, list]
+) -> np.float64:
+ if isinstance(source_representation, list):
+ source_representation = np.array(source_representation)
+
+ if isinstance(test_representation, list):
+ test_representation = np.array(test_representation)
+
+ euclidean_distance = source_representation - test_representation
+ euclidean_distance = np.sum(np.multiply(euclidean_distance, euclidean_distance))
+ euclidean_distance = np.sqrt(euclidean_distance)
+ return euclidean_distance
+
+
+def l2_normalize(x: np.ndarray) -> np.ndarray:
+ return x / np.sqrt(np.sum(np.multiply(x, x)))
+
+
+def findThreshold(model_name: str, distance_metric: str) -> float:
+
+ base_threshold = {"cosine": 0.40, "euclidean": 0.55, "euclidean_l2": 0.75}
+
+ thresholds = {
+ # "VGG-Face": {"cosine": 0.40, "euclidean": 0.60, "euclidean_l2": 0.86}, # 2622d
+ "VGG-Face": {
+ "cosine": 0.68,
+ "euclidean": 1.17,
+ "euclidean_l2": 1.17,
+ }, # 4096d - tuned with LFW
+ "Facenet": {"cosine": 0.40, "euclidean": 10, "euclidean_l2": 0.80},
+ "Facenet512": {"cosine": 0.30, "euclidean": 23.56, "euclidean_l2": 1.04},
+ "ArcFace": {"cosine": 0.68, "euclidean": 4.15, "euclidean_l2": 1.13},
+ "Dlib": {"cosine": 0.07, "euclidean": 0.6, "euclidean_l2": 0.4},
+ "SFace": {"cosine": 0.593, "euclidean": 10.734, "euclidean_l2": 1.055},
+ "OpenFace": {"cosine": 0.10, "euclidean": 0.55, "euclidean_l2": 0.55},
+ "DeepFace": {"cosine": 0.23, "euclidean": 64, "euclidean_l2": 0.64},
+ "DeepID": {"cosine": 0.015, "euclidean": 45, "euclidean_l2": 0.17},
+ }
+
+ threshold = thresholds.get(model_name, base_threshold).get(distance_metric, 0.4)
+
+ return threshold
diff --git a/modules/deepface-master/deepface/commons/functions.py b/modules/deepface-master/deepface/commons/functions.py
new file mode 100644
index 000000000..46fb6d27c
--- /dev/null
+++ b/modules/deepface-master/deepface/commons/functions.py
@@ -0,0 +1,397 @@
+import os
+from typing import Union, Tuple
+import base64
+from pathlib import Path
+
+# 3rd party dependencies
+from PIL import Image
+import requests
+import numpy as np
+import cv2
+import tensorflow as tf
+from deprecated import deprecated
+
+# package dependencies
+from deepface.detectors import FaceDetector
+from deepface.commons.logger import Logger
+
+logger = Logger(module="commons.functions")
+
+# pylint: disable=no-else-raise
+
+# --------------------------------------------------
+# configurations of dependencies
+
+tf_version = tf.__version__
+tf_major_version = int(tf_version.split(".", maxsplit=1)[0])
+tf_minor_version = int(tf_version.split(".")[1])
+
+if tf_major_version == 1:
+ from keras.preprocessing import image
+elif tf_major_version == 2:
+ from tensorflow.keras.preprocessing import image
+
+# --------------------------------------------------
+
+
+def initialize_folder() -> None:
+ """Initialize the folder for storing weights and models.
+
+ Raises:
+ OSError: if the folder cannot be created.
+ """
+ home = get_deepface_home()
+ deepFaceHomePath = home + "/.deepface"
+ weightsPath = deepFaceHomePath + "/weights"
+
+ if not os.path.exists(deepFaceHomePath):
+ os.makedirs(deepFaceHomePath, exist_ok=True)
+ logger.info(f"Directory {home}/.deepface created")
+
+ if not os.path.exists(weightsPath):
+ os.makedirs(weightsPath, exist_ok=True)
+ logger.info(f"Directory {home}/.deepface/weights created")
+
+
+def get_deepface_home() -> str:
+ """Get the home directory for storing weights and models.
+
+ Returns:
+ str: the home directory.
+ """
+ return str(os.getenv("DEEPFACE_HOME", default=str(Path.home())))
+
+
+# --------------------------------------------------
+
+
+def loadBase64Img(uri: str) -> np.ndarray:
+ """Load image from base64 string.
+
+ Args:
+ uri: a base64 string.
+
+ Returns:
+ numpy array: the loaded image.
+ """
+ encoded_data = uri.split(",")[1]
+ nparr = np.fromstring(base64.b64decode(encoded_data), np.uint8)
+ img_bgr = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
+ # img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
+ return img_bgr
+
+
+def load_image(img: Union[str, np.ndarray]) -> Tuple[np.ndarray, str]:
+ """
+ Load image from path, url, base64 or numpy array.
+ Args:
+ img: a path, url, base64 or numpy array.
+ Returns:
+ image (numpy array): the loaded image in BGR format
+ image name (str): image name itself
+ """
+
+ # The image is already a numpy array
+ if isinstance(img, np.ndarray):
+ return img, "numpy array"
+
+ if isinstance(img, Path):
+ img = str(img)
+
+ if not isinstance(img, str):
+ raise ValueError(f"img must be numpy array or str but it is {type(img)}")
+
+ # The image is a base64 string
+ if img.startswith("data:image/"):
+ return loadBase64Img(img), "base64 encoded string"
+
+ # The image is a url
+ if img.startswith("http"):
+ return (
+ np.array(Image.open(requests.get(img, stream=True, timeout=60).raw).convert("BGR")),
+ # return url as image name
+ img,
+ )
+
+ # The image is a path
+ if os.path.isfile(img) is not True:
+ raise ValueError(f"Confirm that {img} exists")
+
+ # image must be a file on the system then
+
+ # image name must have english characters
+ if img.isascii() is False:
+ raise ValueError(f"Input image must not have non-english characters - {img}")
+
+ img_obj_bgr = cv2.imread(img)
+ # img_obj_rgb = cv2.cvtColor(img_obj_bgr, cv2.COLOR_BGR2RGB)
+ return img_obj_bgr, img
+
+
+# --------------------------------------------------
+
+
+def extract_faces(
+ img: Union[str, np.ndarray],
+ target_size: tuple = (224, 224),
+ detector_backend: str = "opencv",
+ grayscale: bool = False,
+ enforce_detection: bool = True,
+ align: bool = True,
+) -> list:
+ """Extract faces from an image.
+
+ Args:
+ img: a path, url, base64 or numpy array.
+ target_size (tuple, optional): the target size of the extracted faces.
+ Defaults to (224, 224).
+ detector_backend (str, optional): the face detector backend. Defaults to "opencv".
+ grayscale (bool, optional): whether to convert the extracted faces to grayscale.
+ Defaults to False.
+ enforce_detection (bool, optional): whether to enforce face detection. Defaults to True.
+ align (bool, optional): whether to align the extracted faces. Defaults to True.
+
+ Raises:
+ ValueError: if face could not be detected and enforce_detection is True.
+
+ Returns:
+ list: a list of extracted faces.
+ """
+
+ # this is going to store a list of img itself (numpy), it region and confidence
+ extracted_faces = []
+
+ # img might be path, base64 or numpy array. Convert it to numpy whatever it is.
+ img, img_name = load_image(img)
+ img_region = [0, 0, img.shape[1], img.shape[0]]
+
+ if detector_backend == "skip":
+ face_objs = [(img, img_region, 0)]
+ else:
+ face_detector = FaceDetector.build_model(detector_backend)
+ face_objs = FaceDetector.detect_faces(face_detector, detector_backend, img, align)
+
+ # in case of no face found
+ if len(face_objs) == 0 and enforce_detection is True:
+ if img_name is not None:
+ raise ValueError(
+ f"Face could not be detected in {img_name}."
+ "Please confirm that the picture is a face photo "
+ "or consider to set enforce_detection param to False."
+ )
+ else:
+ raise ValueError(
+ "Face could not be detected. Please confirm that the picture is a face photo "
+ "or consider to set enforce_detection param to False."
+ )
+
+ if len(face_objs) == 0 and enforce_detection is False:
+ face_objs = [(img, img_region, 0)]
+
+ for current_img, current_region, confidence in face_objs:
+ if current_img.shape[0] > 0 and current_img.shape[1] > 0:
+ if grayscale is True:
+ current_img = cv2.cvtColor(current_img, cv2.COLOR_BGR2GRAY)
+
+ # resize and padding
+ factor_0 = target_size[0] / current_img.shape[0]
+ factor_1 = target_size[1] / current_img.shape[1]
+ factor = min(factor_0, factor_1)
+
+ dsize = (
+ int(current_img.shape[1] * factor),
+ int(current_img.shape[0] * factor),
+ )
+ current_img = cv2.resize(current_img, dsize)
+
+ diff_0 = target_size[0] - current_img.shape[0]
+ diff_1 = target_size[1] - current_img.shape[1]
+ if grayscale is False:
+ # Put the base image in the middle of the padded image
+ current_img = np.pad(
+ current_img,
+ (
+ (diff_0 // 2, diff_0 - diff_0 // 2),
+ (diff_1 // 2, diff_1 - diff_1 // 2),
+ (0, 0),
+ ),
+ "constant",
+ )
+ else:
+ current_img = np.pad(
+ current_img,
+ (
+ (diff_0 // 2, diff_0 - diff_0 // 2),
+ (diff_1 // 2, diff_1 - diff_1 // 2),
+ ),
+ "constant",
+ )
+
+ # double check: if target image is not still the same size with target.
+ if current_img.shape[0:2] != target_size:
+ current_img = cv2.resize(current_img, target_size)
+
+ # normalizing the image pixels
+ # what this line doing? must?
+ img_pixels = image.img_to_array(current_img)
+ img_pixels = np.expand_dims(img_pixels, axis=0)
+ img_pixels /= 255 # normalize input in [0, 1]
+
+ # int cast is for the exception - object of type 'float32' is not JSON serializable
+ region_obj = {
+ "x": int(current_region[0]),
+ "y": int(current_region[1]),
+ "w": int(current_region[2]),
+ "h": int(current_region[3]),
+ }
+
+ extracted_face = [img_pixels, region_obj, confidence]
+ extracted_faces.append(extracted_face)
+
+ if len(extracted_faces) == 0 and enforce_detection == True:
+ raise ValueError(
+ f"Detected face shape is {img.shape}. Consider to set enforce_detection arg to False."
+ )
+
+ return extracted_faces
+
+
+def normalize_input(img: np.ndarray, normalization: str = "base") -> np.ndarray:
+ """Normalize input image.
+
+ Args:
+ img (numpy array): the input image.
+ normalization (str, optional): the normalization technique. Defaults to "base",
+ for no normalization.
+
+ Returns:
+ numpy array: the normalized image.
+ """
+
+ # issue 131 declares that some normalization techniques improves the accuracy
+
+ if normalization == "base":
+ return img
+
+ # @trevorgribble and @davedgd contributed this feature
+ # restore input in scale of [0, 255] because it was normalized in scale of
+ # [0, 1] in preprocess_face
+ img *= 255
+
+ if normalization == "raw":
+ pass # return just restored pixels
+
+ elif normalization == "Facenet":
+ mean, std = img.mean(), img.std()
+ img = (img - mean) / std
+
+ elif normalization == "Facenet2018":
+ # simply / 127.5 - 1 (similar to facenet 2018 model preprocessing step as @iamrishab posted)
+ img /= 127.5
+ img -= 1
+
+ elif normalization == "VGGFace":
+ # mean subtraction based on VGGFace1 training data
+ img[..., 0] -= 93.5940
+ img[..., 1] -= 104.7624
+ img[..., 2] -= 129.1863
+
+ elif normalization == "VGGFace2":
+ # mean subtraction based on VGGFace2 training data
+ img[..., 0] -= 91.4953
+ img[..., 1] -= 103.8827
+ img[..., 2] -= 131.0912
+
+ elif normalization == "ArcFace":
+ # Reference study: The faces are cropped and resized to 112×112,
+ # and each pixel (ranged between [0, 255]) in RGB images is normalised
+ # by subtracting 127.5 then divided by 128.
+ img -= 127.5
+ img /= 128
+ else:
+ raise ValueError(f"unimplemented normalization type - {normalization}")
+
+ return img
+
+
+def find_target_size(model_name: str) -> tuple:
+ """Find the target size of the model.
+
+ Args:
+ model_name (str): the model name.
+
+ Returns:
+ tuple: the target size.
+ """
+
+ target_sizes = {
+ "VGG-Face": (224, 224),
+ "Facenet": (160, 160),
+ "Facenet512": (160, 160),
+ "OpenFace": (96, 96),
+ "DeepFace": (152, 152),
+ "DeepID": (47, 55),
+ "Dlib": (150, 150),
+ "ArcFace": (112, 112),
+ "SFace": (112, 112),
+ }
+
+ target_size = target_sizes.get(model_name)
+
+ if target_size == None:
+ raise ValueError(f"unimplemented model name - {model_name}")
+
+ return target_size
+
+
+# ---------------------------------------------------
+# deprecated functions
+
+
+@deprecated(version="0.0.78", reason="Use extract_faces instead of preprocess_face")
+def preprocess_face(
+ img: Union[str, np.ndarray],
+ target_size=(224, 224),
+ detector_backend="opencv",
+ grayscale=False,
+ enforce_detection=True,
+ align=True,
+) -> Union[np.ndarray, None]:
+ """
+ Preprocess only one face
+
+ Args:
+ img (str or numpy): the input image.
+ target_size (tuple, optional): the target size. Defaults to (224, 224).
+ detector_backend (str, optional): the detector backend. Defaults to "opencv".
+ grayscale (bool, optional): whether to convert to grayscale. Defaults to False.
+ enforce_detection (bool, optional): whether to enforce face detection. Defaults to True.
+ align (bool, optional): whether to align the face. Defaults to True.
+
+ Returns:
+ loaded image (numpt): the preprocessed face.
+
+ Raises:
+ ValueError: if face is not detected and enforce_detection is True.
+
+ Deprecated:
+ 0.0.78: Use extract_faces instead of preprocess_face.
+ """
+ logger.warn("Function preprocess_face is deprecated. Use extract_faces instead.")
+ result = None
+ img_objs = extract_faces(
+ img=img,
+ target_size=target_size,
+ detector_backend=detector_backend,
+ grayscale=grayscale,
+ enforce_detection=enforce_detection,
+ align=align,
+ )
+
+ if len(img_objs) > 0:
+ result, _, _ = img_objs[0]
+ # discard expanded dimension
+ if len(result.shape) == 4:
+ result = result[0]
+
+ return result
diff --git a/modules/deepface-master/deepface/commons/logger.py b/modules/deepface-master/deepface/commons/logger.py
new file mode 100644
index 000000000..80a8a34c8
--- /dev/null
+++ b/modules/deepface-master/deepface/commons/logger.py
@@ -0,0 +1,41 @@
+import os
+import logging
+from datetime import datetime
+
+# pylint: disable=broad-except
+class Logger:
+ def __init__(self, module=None):
+ self.module = module
+ log_level = os.environ.get("DEEPFACE_LOG_LEVEL", str(logging.INFO))
+ try:
+ self.log_level = int(log_level)
+ except Exception as err:
+ self.dump_log(
+ f"Exception while parsing $DEEPFACE_LOG_LEVEL."
+ f"Expected int but it is {log_level} ({str(err)})."
+ "Setting app log level to info."
+ )
+ self.log_level = logging.INFO
+
+ def info(self, message):
+ if self.log_level <= logging.INFO:
+ self.dump_log(f"{message}")
+
+ def debug(self, message):
+ if self.log_level <= logging.DEBUG:
+ self.dump_log(f"🕷️ {message}")
+
+ def warn(self, message):
+ if self.log_level <= logging.WARNING:
+ self.dump_log(f"⚠️ {message}")
+
+ def error(self, message):
+ if self.log_level <= logging.ERROR:
+ self.dump_log(f"🔴 {message}")
+
+ def critical(self, message):
+ if self.log_level <= logging.CRITICAL:
+ self.dump_log(f"💥 {message}")
+
+ def dump_log(self, message):
+ print(f"{str(datetime.now())[2:-7]} - {message}")
diff --git a/modules/deepface-master/deepface/detectors/DlibWrapper.py b/modules/deepface-master/deepface/detectors/DlibWrapper.py
new file mode 100644
index 000000000..86e8f8817
--- /dev/null
+++ b/modules/deepface-master/deepface/detectors/DlibWrapper.py
@@ -0,0 +1,108 @@
+import os
+import bz2
+import gdown
+import numpy as np
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="detectors.DlibWrapper")
+
+
+def build_model() -> dict:
+ """
+ Build a dlib hog face detector model
+ Returns:
+ model (Any)
+ """
+ home = functions.get_deepface_home()
+
+ # this is not a must dependency. do not import it in the global level.
+ try:
+ import dlib
+ except ModuleNotFoundError as e:
+ raise ImportError(
+ "Dlib is an optional detector, ensure the library is installed."
+ "Please install using 'pip install dlib' "
+ ) from e
+
+ # check required file exists in the home/.deepface/weights folder
+ if os.path.isfile(home + "/.deepface/weights/shape_predictor_5_face_landmarks.dat") != True:
+
+ file_name = "shape_predictor_5_face_landmarks.dat.bz2"
+ logger.info(f"{file_name} is going to be downloaded")
+
+ url = f"http://dlib.net/files/{file_name}"
+ output = f"{home}/.deepface/weights/{file_name}"
+
+ gdown.download(url, output, quiet=False)
+
+ zipfile = bz2.BZ2File(output)
+ data = zipfile.read()
+ newfilepath = output[:-4] # discard .bz2 extension
+ with open(newfilepath, "wb") as f:
+ f.write(data)
+
+ face_detector = dlib.get_frontal_face_detector()
+ sp = dlib.shape_predictor(home + "/.deepface/weights/shape_predictor_5_face_landmarks.dat")
+
+ detector = {}
+ detector["face_detector"] = face_detector
+ detector["sp"] = sp
+ return detector
+
+
+def detect_face(detector: dict, img: np.ndarray, align: bool = True) -> list:
+ """
+ Detect and align face with dlib
+ Args:
+ face_detector (Any): dlib face detector object
+ img (np.ndarray): pre-loaded image
+ align (bool): default is true
+ Returns:
+ list of detected and aligned faces
+ """
+ # this is not a must dependency. do not import it in the global level.
+ try:
+ import dlib
+ except ModuleNotFoundError as e:
+ raise ImportError(
+ "Dlib is an optional detector, ensure the library is installed."
+ "Please install using 'pip install dlib' "
+ ) from e
+
+ resp = []
+
+ sp = detector["sp"]
+
+ detected_face = None
+
+ img_region = [0, 0, img.shape[1], img.shape[0]]
+
+ face_detector = detector["face_detector"]
+
+ # note that, by design, dlib's fhog face detector scores are >0 but not capped at 1
+ detections, scores, _ = face_detector.run(img, 1)
+
+ if len(detections) > 0:
+
+ for idx, d in enumerate(detections):
+ left = d.left()
+ right = d.right()
+ top = d.top()
+ bottom = d.bottom()
+
+ # detected_face = img[top:bottom, left:right]
+ detected_face = img[
+ max(0, top) : min(bottom, img.shape[0]), max(0, left) : min(right, img.shape[1])
+ ]
+
+ img_region = [left, top, right - left, bottom - top]
+ confidence = scores[idx]
+
+ if align:
+ img_shape = sp(img, detections[idx])
+ detected_face = dlib.get_face_chip(img, img_shape, size=detected_face.shape[0])
+
+ resp.append((detected_face, img_region, confidence))
+
+ return resp
diff --git a/modules/deepface-master/deepface/detectors/FaceDetector.py b/modules/deepface-master/deepface/detectors/FaceDetector.py
new file mode 100644
index 000000000..7dea56e3c
--- /dev/null
+++ b/modules/deepface-master/deepface/detectors/FaceDetector.py
@@ -0,0 +1,149 @@
+from typing import Any, Union
+from PIL import Image
+import numpy as np
+from deepface.detectors import (
+ OpenCvWrapper,
+ SsdWrapper,
+ DlibWrapper,
+ MtcnnWrapper,
+ RetinaFaceWrapper,
+ MediapipeWrapper,
+ YoloWrapper,
+ YunetWrapper,
+ FastMtcnnWrapper,
+)
+
+
+def build_model(detector_backend: str) -> Any:
+ """
+ Build a face detector model
+ Args:
+ detector_backend (str): backend detector name
+ Returns:
+ built detector (Any)
+ """
+ global face_detector_obj # singleton design pattern
+
+ backends = {
+ "opencv": OpenCvWrapper.build_model,
+ "ssd": SsdWrapper.build_model,
+ "dlib": DlibWrapper.build_model,
+ "mtcnn": MtcnnWrapper.build_model,
+ "retinaface": RetinaFaceWrapper.build_model,
+ "mediapipe": MediapipeWrapper.build_model,
+ "yolov8": YoloWrapper.build_model,
+ "yunet": YunetWrapper.build_model,
+ "fastmtcnn": FastMtcnnWrapper.build_model,
+ }
+
+ if not "face_detector_obj" in globals():
+ face_detector_obj = {}
+
+ built_models = list(face_detector_obj.keys())
+ if detector_backend not in built_models:
+ face_detector = backends.get(detector_backend)
+
+ if face_detector:
+ face_detector = face_detector()
+ face_detector_obj[detector_backend] = face_detector
+ else:
+ raise ValueError("invalid detector_backend passed - " + detector_backend)
+
+ return face_detector_obj[detector_backend]
+
+
+def detect_face(
+ face_detector: Any, detector_backend: str, img: np.ndarray, align: bool = True
+) -> tuple:
+ """
+ Detect a single face from a given image
+ Args:
+ face_detector (Any): pre-built face detector object
+ detector_backend (str): detector name
+ img (np.ndarray): pre-loaded image
+ alig (bool): enable or disable alignment after detection
+ Returns
+ result (tuple): tuple of face (np.ndarray), face region (list)
+ , confidence score (float)
+ """
+ obj = detect_faces(face_detector, detector_backend, img, align)
+
+ if len(obj) > 0:
+ face, region, confidence = obj[0] # discard multiple faces
+
+ # If no face is detected, set face to None,
+ # image region to full image, and confidence to 0.
+ else: # len(obj) == 0
+ face = None
+ region = [0, 0, img.shape[1], img.shape[0]]
+ confidence = 0
+
+ return face, region, confidence
+
+
+def detect_faces(
+ face_detector: Any, detector_backend: str, img: np.ndarray, align: bool = True
+) -> list:
+ """
+ Detect face(s) from a given image
+ Args:
+ face_detector (Any): pre-built face detector object
+ detector_backend (str): detector name
+ img (np.ndarray): pre-loaded image
+ alig (bool): enable or disable alignment after detection
+ Returns
+ result (list): tuple of face (np.ndarray), face region (list)
+ , confidence score (float)
+ """
+ backends = {
+ "opencv": OpenCvWrapper.detect_face,
+ "ssd": SsdWrapper.detect_face,
+ "dlib": DlibWrapper.detect_face,
+ "mtcnn": MtcnnWrapper.detect_face,
+ "retinaface": RetinaFaceWrapper.detect_face,
+ "mediapipe": MediapipeWrapper.detect_face,
+ "yolov8": YoloWrapper.detect_face,
+ "yunet": YunetWrapper.detect_face,
+ "fastmtcnn": FastMtcnnWrapper.detect_face,
+ }
+
+ detect_face_fn = backends.get(detector_backend)
+
+ if detect_face_fn: # pylint: disable=no-else-return
+ obj = detect_face_fn(face_detector, img, align)
+ # obj stores list of (detected_face, region, confidence)
+ return obj
+ else:
+ raise ValueError("invalid detector_backend passed - " + detector_backend)
+
+
+def get_alignment_angle_arctan2(
+ left_eye: Union[list, tuple], right_eye: Union[list, tuple]
+) -> float:
+ """
+ Find the angle between eyes
+ Args:
+ left_eye: coordinates of left eye with respect to the you
+ right_eye: coordinates of right eye with respect to the you
+ Returns:
+ angle (float)
+ """
+ return float(np.degrees(np.arctan2(right_eye[1] - left_eye[1], right_eye[0] - left_eye[0])))
+
+
+def alignment_procedure(
+ img: np.ndarray, left_eye: Union[list, tuple], right_eye: Union[list, tuple]
+) -> np.ndarray:
+ """
+ Rotate given image until eyes are on a horizontal line
+ Args:
+ img (np.ndarray): pre-loaded image
+ left_eye: coordinates of left eye with respect to the you
+ right_eye: coordinates of right eye with respect to the you
+ Returns:
+ result (np.ndarray): aligned face
+ """
+ angle = get_alignment_angle_arctan2(left_eye, right_eye)
+ img = Image.fromarray(img)
+ img = np.array(img.rotate(angle))
+ return img
diff --git a/modules/deepface-master/deepface/detectors/FastMtcnnWrapper.py b/modules/deepface-master/deepface/detectors/FastMtcnnWrapper.py
new file mode 100644
index 000000000..be50db9fb
--- /dev/null
+++ b/modules/deepface-master/deepface/detectors/FastMtcnnWrapper.py
@@ -0,0 +1,79 @@
+from typing import Any, Union
+import cv2
+import numpy as np
+from deepface.detectors import FaceDetector
+
+# Link -> https://github.com/timesler/facenet-pytorch
+# Examples https://www.kaggle.com/timesler/guide-to-mtcnn-in-facenet-pytorch
+
+
+def build_model() -> Any:
+ """
+ Build a fast mtcnn face detector model
+ Returns:
+ model (Any)
+ """
+ # this is not a must dependency. do not import it in the global level.
+ try:
+ from facenet_pytorch import MTCNN as fast_mtcnn
+ except ModuleNotFoundError as e:
+ raise ImportError(
+ "FastMtcnn is an optional detector, ensure the library is installed."
+ "Please install using 'pip install facenet-pytorch' "
+ ) from e
+
+ face_detector = fast_mtcnn(
+ image_size=160,
+ thresholds=[0.6, 0.7, 0.7], # MTCNN thresholds
+ post_process=True,
+ device="cpu",
+ select_largest=False, # return result in descending order
+ )
+ return face_detector
+
+
+def xyxy_to_xywh(xyxy: Union[list, tuple]) -> list:
+ """
+ Convert xyxy format to xywh format.
+ """
+ x, y = xyxy[0], xyxy[1]
+ w = xyxy[2] - x + 1
+ h = xyxy[3] - y + 1
+ return [x, y, w, h]
+
+
+def detect_face(face_detector: Any, img: np.ndarray, align: bool = True) -> list:
+ """
+ Detect and align face with mtcnn
+ Args:
+ face_detector (Any): mtcnn face detector object
+ img (np.ndarray): pre-loaded image
+ align (bool): default is true
+ Returns:
+ list of detected and aligned faces
+ """
+ resp = []
+
+ detected_face = None
+ img_region = [0, 0, img.shape[1], img.shape[0]]
+
+ img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # mtcnn expects RGB but OpenCV read BGR
+ detections = face_detector.detect(
+ img_rgb, landmarks=True
+ ) # returns boundingbox, prob, landmark
+ if len(detections[0]) > 0:
+
+ for detection in zip(*detections):
+ x, y, w, h = xyxy_to_xywh(detection[0])
+ detected_face = img[int(y) : int(y + h), int(x) : int(x + w)]
+ img_region = [x, y, w, h]
+ confidence = detection[1]
+
+ if align:
+ left_eye = detection[2][0]
+ right_eye = detection[2][1]
+ detected_face = FaceDetector.alignment_procedure(detected_face, left_eye, right_eye)
+
+ resp.append((detected_face, img_region, confidence))
+
+ return resp
diff --git a/modules/deepface-master/deepface/detectors/MediapipeWrapper.py b/modules/deepface-master/deepface/detectors/MediapipeWrapper.py
new file mode 100644
index 000000000..bf9e0d0a8
--- /dev/null
+++ b/modules/deepface-master/deepface/detectors/MediapipeWrapper.py
@@ -0,0 +1,78 @@
+from typing import Any
+import numpy as np
+from deepface.detectors import FaceDetector
+
+# Link - https://google.github.io/mediapipe/solutions/face_detection
+
+
+def build_model() -> Any:
+ """
+ Build a mediapipe face detector model
+ Returns:
+ model (Any)
+ """
+ # this is not a must dependency. do not import it in the global level.
+ try:
+ import mediapipe as mp
+ except ModuleNotFoundError as e:
+ raise ImportError(
+ "MediaPipe is an optional detector, ensure the library is installed."
+ "Please install using 'pip install mediapipe' "
+ ) from e
+
+ mp_face_detection = mp.solutions.face_detection
+ face_detection = mp_face_detection.FaceDetection(min_detection_confidence=0.7)
+ return face_detection
+
+
+def detect_face(face_detector: Any, img: np.ndarray, align: bool = True) -> list:
+ """
+ Detect and align face with mediapipe
+ Args:
+ face_detector (Any): mediapipe face detector object
+ img (np.ndarray): pre-loaded image
+ align (bool): default is true
+ Returns:
+ list of detected and aligned faces
+ """
+ resp = []
+
+ img_width = img.shape[1]
+ img_height = img.shape[0]
+
+ results = face_detector.process(img)
+
+ # If no face has been detected, return an empty list
+ if results.detections is None:
+ return resp
+
+ # Extract the bounding box, the landmarks and the confidence score
+ for detection in results.detections:
+ (confidence,) = detection.score
+
+ bounding_box = detection.location_data.relative_bounding_box
+ landmarks = detection.location_data.relative_keypoints
+
+ x = int(bounding_box.xmin * img_width)
+ w = int(bounding_box.width * img_width)
+ y = int(bounding_box.ymin * img_height)
+ h = int(bounding_box.height * img_height)
+
+ # Extract landmarks
+ left_eye = (int(landmarks[0].x * img_width), int(landmarks[0].y * img_height))
+ right_eye = (int(landmarks[1].x * img_width), int(landmarks[1].y * img_height))
+ # nose = (int(landmarks[2].x * img_width), int(landmarks[2].y * img_height))
+ # mouth = (int(landmarks[3].x * img_width), int(landmarks[3].y * img_height))
+ # right_ear = (int(landmarks[4].x * img_width), int(landmarks[4].y * img_height))
+ # left_ear = (int(landmarks[5].x * img_width), int(landmarks[5].y * img_height))
+
+ if x > 0 and y > 0:
+ detected_face = img[y : y + h, x : x + w]
+ img_region = [x, y, w, h]
+
+ if align:
+ detected_face = FaceDetector.alignment_procedure(detected_face, left_eye, right_eye)
+
+ resp.append((detected_face, img_region, confidence))
+
+ return resp
diff --git a/modules/deepface-master/deepface/detectors/MtcnnWrapper.py b/modules/deepface-master/deepface/detectors/MtcnnWrapper.py
new file mode 100644
index 000000000..f74654156
--- /dev/null
+++ b/modules/deepface-master/deepface/detectors/MtcnnWrapper.py
@@ -0,0 +1,54 @@
+from typing import Any
+import cv2
+import numpy as np
+from deepface.detectors import FaceDetector
+
+
+def build_model() -> Any:
+ """
+ Build a mtcnn face detector model
+ Returns:
+ model (Any)
+ """
+ from mtcnn import MTCNN
+
+ face_detector = MTCNN()
+ return face_detector
+
+
+def detect_face(face_detector: Any, img: np.ndarray, align: bool = True) -> list:
+ """
+ Detect and align face with mtcnn
+ Args:
+ face_detector (mtcnn.MTCNN): mtcnn face detector object
+ img (np.ndarray): pre-loaded image
+ align (bool): default is true
+ Returns:
+ list of detected and aligned faces
+ """
+
+ resp = []
+
+ detected_face = None
+ img_region = [0, 0, img.shape[1], img.shape[0]]
+
+ img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # mtcnn expects RGB but OpenCV read BGR
+ detections = face_detector.detect_faces(img_rgb)
+
+ if len(detections) > 0:
+
+ for detection in detections:
+ x, y, w, h = detection["box"]
+ detected_face = img[int(y) : int(y + h), int(x) : int(x + w)]
+ img_region = [x, y, w, h]
+ confidence = detection["confidence"]
+
+ if align:
+ keypoints = detection["keypoints"]
+ left_eye = keypoints["left_eye"]
+ right_eye = keypoints["right_eye"]
+ detected_face = FaceDetector.alignment_procedure(detected_face, left_eye, right_eye)
+
+ resp.append((detected_face, img_region, confidence))
+
+ return resp
diff --git a/modules/deepface-master/deepface/detectors/OpenCvWrapper.py b/modules/deepface-master/deepface/detectors/OpenCvWrapper.py
new file mode 100644
index 000000000..6316c3346
--- /dev/null
+++ b/modules/deepface-master/deepface/detectors/OpenCvWrapper.py
@@ -0,0 +1,158 @@
+import os
+from typing import Any
+import cv2
+import numpy as np
+from deepface.detectors import FaceDetector
+
+
+def build_model() -> dict:
+ """
+ Build a opencv face&eye detector models
+ Returns:
+ model (Any)
+ """
+ detector = {}
+ detector["face_detector"] = build_cascade("haarcascade")
+ detector["eye_detector"] = build_cascade("haarcascade_eye")
+ return detector
+
+
+def build_cascade(model_name="haarcascade") -> Any:
+ """
+ Build a opencv face&eye detector models
+ Returns:
+ model (Any)
+ """
+ opencv_path = get_opencv_path()
+ if model_name == "haarcascade":
+ face_detector_path = opencv_path + "haarcascade_frontalface_default.xml"
+ if os.path.isfile(face_detector_path) != True:
+ raise ValueError(
+ "Confirm that opencv is installed on your environment! Expected path ",
+ face_detector_path,
+ " violated.",
+ )
+ detector = cv2.CascadeClassifier(face_detector_path)
+
+ elif model_name == "haarcascade_eye":
+ eye_detector_path = opencv_path + "haarcascade_eye.xml"
+ if os.path.isfile(eye_detector_path) != True:
+ raise ValueError(
+ "Confirm that opencv is installed on your environment! Expected path ",
+ eye_detector_path,
+ " violated.",
+ )
+ detector = cv2.CascadeClassifier(eye_detector_path)
+
+ else:
+ raise ValueError(f"unimplemented model_name for build_cascade - {model_name}")
+
+ return detector
+
+
+def detect_face(detector: dict, img: np.ndarray, align: bool = True) -> list:
+ """
+ Detect and align face with opencv
+ Args:
+ face_detector (Any): opencv face detector object
+ img (np.ndarray): pre-loaded image
+ align (bool): default is true
+ Returns:
+ list of detected and aligned faces
+ """
+ resp = []
+
+ detected_face = None
+ img_region = [0, 0, img.shape[1], img.shape[0]]
+
+ faces = []
+ try:
+ # faces = detector["face_detector"].detectMultiScale(img, 1.3, 5)
+
+ # note that, by design, opencv's haarcascade scores are >0 but not capped at 1
+ faces, _, scores = detector["face_detector"].detectMultiScale3(
+ img, 1.1, 10, outputRejectLevels=True
+ )
+ except:
+ pass
+
+ if len(faces) > 0:
+ for (x, y, w, h), confidence in zip(faces, scores):
+ detected_face = img[int(y) : int(y + h), int(x) : int(x + w)]
+
+ if align:
+ detected_face = align_face(detector["eye_detector"], detected_face)
+
+ img_region = [x, y, w, h]
+
+ resp.append((detected_face, img_region, confidence))
+
+ return resp
+
+
+def align_face(eye_detector: Any, img: np.ndarray) -> np.ndarray:
+ """
+ Align a given image with the pre-built eye_detector
+ Args:
+ eye_detector (Any): cascade classifier object
+ img (np.ndarray): given image
+ Returns:
+ aligned_img (np.ndarray)
+ """
+ # if image has unexpectedly 0 dimension then skip alignment
+ if img.shape[0] == 0 or img.shape[1] == 0:
+ return img
+
+ detected_face_gray = cv2.cvtColor(
+ img, cv2.COLOR_BGR2GRAY
+ ) # eye detector expects gray scale image
+
+ # eyes = eye_detector.detectMultiScale(detected_face_gray, 1.3, 5)
+ eyes = eye_detector.detectMultiScale(detected_face_gray, 1.1, 10)
+
+ # ----------------------------------------------------------------
+
+ # opencv eye detectin module is not strong. it might find more than 2 eyes!
+ # besides, it returns eyes with different order in each call (issue 435)
+ # this is an important issue because opencv is the default detector and ssd also uses this
+ # find the largest 2 eye. Thanks to @thelostpeace
+
+ eyes = sorted(eyes, key=lambda v: abs(v[2] * v[3]), reverse=True)
+
+ # ----------------------------------------------------------------
+
+ if len(eyes) >= 2:
+ # decide left and right eye
+
+ eye_1 = eyes[0]
+ eye_2 = eyes[1]
+
+ if eye_1[0] < eye_2[0]:
+ left_eye = eye_1
+ right_eye = eye_2
+ else:
+ left_eye = eye_2
+ right_eye = eye_1
+
+ # -----------------------
+ # find center of eyes
+ left_eye = (int(left_eye[0] + (left_eye[2] / 2)), int(left_eye[1] + (left_eye[3] / 2)))
+ right_eye = (int(right_eye[0] + (right_eye[2] / 2)), int(right_eye[1] + (right_eye[3] / 2)))
+ img = FaceDetector.alignment_procedure(img, left_eye, right_eye)
+ return img # return img anyway
+
+
+def get_opencv_path() -> str:
+ """
+ Returns where opencv installed
+ Returns:
+ installation_path (str)
+ """
+ opencv_home = cv2.__file__
+ folders = opencv_home.split(os.path.sep)[0:-1]
+
+ path = folders[0]
+ for folder in folders[1:]:
+ path = path + "/" + folder
+
+ return path + "/data/"
diff --git a/modules/deepface-master/deepface/detectors/RetinaFaceWrapper.py b/modules/deepface-master/deepface/detectors/RetinaFaceWrapper.py
new file mode 100644
index 000000000..dc470264b
--- /dev/null
+++ b/modules/deepface-master/deepface/detectors/RetinaFaceWrapper.py
@@ -0,0 +1,60 @@
+from typing import Any
+import numpy as np
+from retinaface import RetinaFace
+from retinaface.commons import postprocess
+
+
+def build_model() -> Any:
+ """
+ Build a retinaface detector model
+ Returns:
+ model (Any)
+ """
+ face_detector = RetinaFace.build_model()
+ return face_detector
+
+
+def detect_face(face_detector: Any, img: np.ndarray, align: bool = True) -> list:
+ """
+ Detect and align face with retinaface
+ Args:
+ face_detector (Any): retinaface face detector object
+ img (np.ndarray): pre-loaded image
+ align (bool): default is true
+ Returns:
+ list of detected and aligned faces
+ """
+ resp = []
+
+ obj = RetinaFace.detect_faces(img, model=face_detector, threshold=0.9)
+
+ if isinstance(obj, dict):
+ for face_idx in obj.keys():
+ identity = obj[face_idx]
+ facial_area = identity["facial_area"]
+
+ y = facial_area[1]
+ h = facial_area[3] - y
+ x = facial_area[0]
+ w = facial_area[2] - x
+ img_region = [x, y, w, h]
+ confidence = identity["score"]
+
+ # detected_face = img[int(y):int(y+h), int(x):int(x+w)] #opencv
+ detected_face = img[facial_area[1] : facial_area[3], facial_area[0] : facial_area[2]]
+
+ if align:
+ landmarks = identity["landmarks"]
+ left_eye = landmarks["left_eye"]
+ right_eye = landmarks["right_eye"]
+ nose = landmarks["nose"]
+ # mouth_right = landmarks["mouth_right"]
+ # mouth_left = landmarks["mouth_left"]
+
+ detected_face = postprocess.alignment_procedure(
+ detected_face, right_eye, left_eye, nose
+ )
+
+ resp.append((detected_face, img_region, confidence))
+
+ return resp
diff --git a/modules/deepface-master/deepface/detectors/SsdWrapper.py b/modules/deepface-master/deepface/detectors/SsdWrapper.py
new file mode 100644
index 000000000..9f8c51716
--- /dev/null
+++ b/modules/deepface-master/deepface/detectors/SsdWrapper.py
@@ -0,0 +1,137 @@
+import os
+import gdown
+import cv2
+import pandas as pd
+import numpy as np
+from deepface.detectors import OpenCvWrapper
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="detectors.SsdWrapper")
+
+# pylint: disable=line-too-long
+
+
+def build_model() -> dict:
+ """
+ Build a ssd detector model
+ Returns:
+ model (Any)
+ """
+
+ home = functions.get_deepface_home()
+
+ # model structure
+ if os.path.isfile(home + "/.deepface/weights/deploy.prototxt") != True:
+
+ logger.info("deploy.prototxt will be downloaded...")
+
+ url = "https://github.com/opencv/opencv/raw/3.4.0/samples/dnn/face_detector/deploy.prototxt"
+
+ output = home + "/.deepface/weights/deploy.prototxt"
+
+ gdown.download(url, output, quiet=False)
+
+ # pre-trained weights
+ if os.path.isfile(home + "/.deepface/weights/res10_300x300_ssd_iter_140000.caffemodel") != True:
+
+ logger.info("res10_300x300_ssd_iter_140000.caffemodel will be downloaded...")
+
+ url = "https://github.com/opencv/opencv_3rdparty/raw/dnn_samples_face_detector_20170830/res10_300x300_ssd_iter_140000.caffemodel"
+
+ output = home + "/.deepface/weights/res10_300x300_ssd_iter_140000.caffemodel"
+
+ gdown.download(url, output, quiet=False)
+
+ try:
+ face_detector = cv2.dnn.readNetFromCaffe(
+ home + "/.deepface/weights/deploy.prototxt",
+ home + "/.deepface/weights/res10_300x300_ssd_iter_140000.caffemodel",
+ )
+ except Exception as err:
+ raise ValueError(
+ "Exception while calling opencv.dnn module."
+ + "This is an optional dependency."
+ + "You can install it as pip install opencv-contrib-python."
+ ) from err
+
+ eye_detector = OpenCvWrapper.build_cascade("haarcascade_eye")
+
+ detector = {}
+ detector["face_detector"] = face_detector
+ detector["eye_detector"] = eye_detector
+
+ return detector
+
+
+def detect_face(detector: dict, img: np.ndarray, align: bool = True) -> list:
+ """
+ Detect and align face with ssd
+ Args:
+ face_detector (Any): ssd face detector object
+ img (np.ndarray): pre-loaded image
+ align (bool): default is true
+ Returns:
+ list of detected and aligned faces
+ """
+ resp = []
+
+ detected_face = None
+ img_region = [0, 0, img.shape[1], img.shape[0]]
+
+ ssd_labels = ["img_id", "is_face", "confidence", "left", "top", "right", "bottom"]
+
+ target_size = (300, 300)
+
+ base_img = img.copy() # we will restore base_img to img later
+
+ original_size = img.shape
+
+ img = cv2.resize(img, target_size)
+
+ aspect_ratio_x = original_size[1] / target_size[1]
+ aspect_ratio_y = original_size[0] / target_size[0]
+
+ imageBlob = cv2.dnn.blobFromImage(image=img)
+
+ face_detector = detector["face_detector"]
+ face_detector.setInput(imageBlob)
+ detections = face_detector.forward()
+
+ detections_df = pd.DataFrame(detections[0][0], columns=ssd_labels)
+
+ detections_df = detections_df[detections_df["is_face"] == 1] # 0: background, 1: face
+ detections_df = detections_df[detections_df["confidence"] >= 0.90]
+
+ detections_df["left"] = (detections_df["left"] * 300).astype(int)
+ detections_df["bottom"] = (detections_df["bottom"] * 300).astype(int)
+ detections_df["right"] = (detections_df["right"] * 300).astype(int)
+ detections_df["top"] = (detections_df["top"] * 300).astype(int)
+
+ if detections_df.shape[0] > 0:
+
+ for _, instance in detections_df.iterrows():
+
+ left = instance["left"]
+ right = instance["right"]
+ bottom = instance["bottom"]
+ top = instance["top"]
+
+ detected_face = base_img[
+ int(top * aspect_ratio_y) : int(bottom * aspect_ratio_y),
+ int(left * aspect_ratio_x) : int(right * aspect_ratio_x),
+ ]
+ img_region = [
+ int(left * aspect_ratio_x),
+ int(top * aspect_ratio_y),
+ int(right * aspect_ratio_x) - int(left * aspect_ratio_x),
+ int(bottom * aspect_ratio_y) - int(top * aspect_ratio_y),
+ ]
+ confidence = instance["confidence"]
+
+ if align:
+ detected_face = OpenCvWrapper.align_face(detector["eye_detector"], detected_face)
+
+ resp.append((detected_face, img_region, confidence))
+
+ return resp
diff --git a/modules/deepface-master/deepface/detectors/YoloWrapper.py b/modules/deepface-master/deepface/detectors/YoloWrapper.py
new file mode 100644
index 000000000..0786cc15d
--- /dev/null
+++ b/modules/deepface-master/deepface/detectors/YoloWrapper.py
@@ -0,0 +1,90 @@
+from typing import Any
+import numpy as np
+from deepface.detectors import FaceDetector
+from deepface.commons.logger import Logger
+
+logger = Logger()
+
+# Model's weights paths
+PATH = "/.deepface/weights/yolov8n-face.pt"
+
+# Google Drive URL
+WEIGHT_URL = "https://drive.google.com/uc?id=1qcr9DbgsX3ryrz2uU8w4Xm3cOrRywXqb"
+
+# Confidence thresholds for landmarks detection
+# used in alignment_procedure function
+LANDMARKS_CONFIDENCE_THRESHOLD = 0.5
+
+
+def build_model() -> Any:
+ """
+ Build a yolo detector model
+ Returns:
+ model (Any)
+ """
+ import gdown
+ import os
+
+ # Import the Ultralytics YOLO model
+ try:
+ from ultralytics import YOLO
+ except ModuleNotFoundError as e:
+ raise ImportError(
+ "Yolo is an optional detector, ensure the library is installed. \
+ Please install using 'pip install ultralytics' "
+ ) from e
+
+ from deepface.commons.functions import get_deepface_home
+
+ weight_path = f"{get_deepface_home()}{PATH}"
+
+ # Download the model's weights if they don't exist
+ if not os.path.isfile(weight_path):
+ gdown.download(WEIGHT_URL, weight_path, quiet=False)
+ logger.info(f"Downloaded YOLO model {os.path.basename(weight_path)}")
+
+ # Return face_detector
+ return YOLO(weight_path)
+
+
+def detect_face(face_detector: Any, img: np.ndarray, align: bool = False) -> list:
+ """
+ Detect and align face with yolo
+ Args:
+ face_detector (Any): yolo face detector object
+ img (np.ndarray): pre-loaded image
+ align (bool): default is true
+ Returns:
+ list of detected and aligned faces
+ """
+ resp = []
+
+ # Detect faces
+ results = face_detector.predict(img, verbose=False, show=False, conf=0.25)[0]
+
+ # For each face, extract the bounding box, the landmarks and confidence
+ for result in results:
+ # Extract the bounding box and the confidence
+ x, y, w, h = result.boxes.xywh.tolist()[0]
+ confidence = result.boxes.conf.tolist()[0]
+
+ x, y, w, h = int(x - w / 2), int(y - h / 2), int(w), int(h)
+ detected_face = img[y : y + h, x : x + w].copy()
+
+ if align:
+ # Tuple of x,y and confidence for left eye
+ left_eye = result.keypoints.xy[0][0], result.keypoints.conf[0][0]
+ # Tuple of x,y and confidence for right eye
+ right_eye = result.keypoints.xy[0][1], result.keypoints.conf[0][1]
+
+ # Check the landmarks confidence before alignment
+ if (
+ left_eye[1] > LANDMARKS_CONFIDENCE_THRESHOLD
+ and right_eye[1] > LANDMARKS_CONFIDENCE_THRESHOLD
+ ):
+ detected_face = FaceDetector.alignment_procedure(
+ detected_face, left_eye[0].cpu(), right_eye[0].cpu()
+ )
+ resp.append((detected_face, [x, y, w, h], confidence))
+
+ return resp
diff --git a/modules/deepface-master/deepface/detectors/YunetWrapper.py b/modules/deepface-master/deepface/detectors/YunetWrapper.py
new file mode 100644
index 000000000..005fa6dc3
--- /dev/null
+++ b/modules/deepface-master/deepface/detectors/YunetWrapper.py
@@ -0,0 +1,114 @@
+import os
+from typing import Any
+import cv2
+import numpy as np
+import gdown
+from deepface.detectors import FaceDetector
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="detectors.YunetWrapper")
+
+
+def build_model() -> Any:
+ """
+ Build a yunet detector model
+ Returns:
+ model (Any)
+ """
+ # pylint: disable=C0301
+ url = "https://github.com/opencv/opencv_zoo/raw/main/models/face_detection_yunet/face_detection_yunet_2023mar.onnx"
+ file_name = "face_detection_yunet_2023mar.onnx"
+ home = functions.get_deepface_home()
+ if os.path.isfile(home + f"/.deepface/weights/{file_name}") is False:
+ logger.info(f"{file_name} will be downloaded...")
+ output = home + f"/.deepface/weights/{file_name}"
+ gdown.download(url, output, quiet=False)
+
+ try:
+ face_detector = cv2.FaceDetectorYN_create(
+ home + f"/.deepface/weights/{file_name}", "", (0, 0)
+ )
+ except Exception as err:
+ raise ValueError(
+ "Exception while calling opencv.FaceDetectorYN_create module."
+ + "This is an optional dependency."
+ + "You can install it as pip install opencv-contrib-python."
+ ) from err
+ return face_detector
+
+
+def detect_face(
+ detector: Any, image: np.ndarray, align: bool = True, score_threshold: float = 0.9
+) -> list:
+ """
+ Detect and align face with yunet
+ Args:
+ face_detector (Any): yunet face detector object
+ img (np.ndarray): pre-loaded image
+ align (bool): default is true
+ Returns:
+ list of detected and aligned faces
+ """
+ # FaceDetector.detect_faces does not support score_threshold parameter.
+ # We can set it via environment variable.
+ score_threshold = os.environ.get("yunet_score_threshold", score_threshold)
+ resp = []
+ detected_face = None
+ img_region = [0, 0, image.shape[1], image.shape[0]]
+ faces = []
+ height, width = image.shape[0], image.shape[1]
+ # resize image if it is too large (Yunet fails to detect faces on large input sometimes)
+ # I picked 640 as a threshold because it is the default value of max_size in Yunet.
+ resized = False
+ if height > 640 or width > 640:
+ r = 640.0 / max(height, width)
+ original_image = image.copy()
+ image = cv2.resize(image, (int(width * r), int(height * r)))
+ height, width = image.shape[0], image.shape[1]
+ resized = True
+ detector.setInputSize((width, height))
+ detector.setScoreThreshold(score_threshold)
+ _, faces = detector.detect(image)
+ if faces is None:
+ return resp
+ for face in faces:
+ # pylint: disable=W0105
+ """
+ The detection output faces is a two-dimension array of type CV_32F,
+ whose rows are the detected face instances, columns are the location
+ of a face and 5 facial landmarks.
+ The format of each row is as follows:
+ x1, y1, w, h, x_re, y_re, x_le, y_le, x_nt, y_nt,
+ x_rcm, y_rcm, x_lcm, y_lcm,
+ where x1, y1, w, h are the top-left coordinates, width and height of
+ the face bounding box,
+ {x, y}_{re, le, nt, rcm, lcm} stands for the coordinates of right eye,
+ left eye, nose tip, the right corner and left corner of the mouth respectively.
+ """
+ (x, y, w, h, x_re, y_re, x_le, y_le) = list(map(int, face[:8]))
+
+ # Yunet returns negative coordinates if it thinks part of
+ # the detected face is outside the frame.
+ # We set the coordinate to 0 if they are negative.
+ x = max(x, 0)
+ y = max(y, 0)
+ if resized:
+ image = original_image
+ x, y, w, h = int(x / r), int(y / r), int(w / r), int(h / r)
+ x_re, y_re, x_le, y_le = (
+ int(x_re / r),
+ int(y_re / r),
+ int(x_le / r),
+ int(y_le / r),
+ )
+ confidence = face[-1]
+ confidence = f"{confidence:.2f}"
+ detected_face = image[int(y) : int(y + h), int(x) : int(x + w)]
+ img_region = [x, y, w, h]
+ if align:
+ detected_face = FaceDetector.alignment_procedure(
+ detected_face, (x_re, y_re), (x_le, y_le)
+ )
+ resp.append((detected_face, img_region, confidence))
+ return resp
diff --git a/modules/deepface-master/deepface/detectors/__init__.py b/modules/deepface-master/deepface/detectors/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/modules/deepface-master/deepface/extendedmodels/Age.py b/modules/deepface-master/deepface/extendedmodels/Age.py
new file mode 100644
index 000000000..73ca6cc24
--- /dev/null
+++ b/modules/deepface-master/deepface/extendedmodels/Age.py
@@ -0,0 +1,66 @@
+import os
+import gdown
+import numpy as np
+import tensorflow as tf
+from deepface.basemodels import VGGFace
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="extendedmodels.Age")
+
+# ----------------------------------------
+# dependency configurations
+
+tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
+
+if tf_version == 1:
+ from keras.models import Model, Sequential
+ from keras.layers import Convolution2D, Flatten, Activation
+else:
+ from tensorflow.keras.models import Model, Sequential
+ from tensorflow.keras.layers import Convolution2D, Flatten, Activation
+
+# ----------------------------------------
+
+
+def loadModel(
+ url="https://github.com/serengil/deepface_models/releases/download/v1.0/age_model_weights.h5",
+) -> Model:
+
+ model = VGGFace.baseModel()
+
+ # --------------------------
+
+ classes = 101
+ base_model_output = Sequential()
+ base_model_output = Convolution2D(classes, (1, 1), name="predictions")(model.layers[-4].output)
+ base_model_output = Flatten()(base_model_output)
+ base_model_output = Activation("softmax")(base_model_output)
+
+ # --------------------------
+
+ age_model = Model(inputs=model.input, outputs=base_model_output)
+
+ # --------------------------
+
+ # load weights
+
+ home = functions.get_deepface_home()
+
+ if os.path.isfile(home + "/.deepface/weights/age_model_weights.h5") != True:
+ logger.info("age_model_weights.h5 will be downloaded...")
+
+ output = home + "/.deepface/weights/age_model_weights.h5"
+ gdown.download(url, output, quiet=False)
+
+ age_model.load_weights(home + "/.deepface/weights/age_model_weights.h5")
+
+ return age_model
+
+ # --------------------------
+
+
+def findApparentAge(age_predictions) -> np.float64:
+ output_indexes = np.array(list(range(0, 101)))
+ apparent_age = np.sum(age_predictions * output_indexes)
+ return apparent_age
diff --git a/modules/deepface-master/deepface/extendedmodels/Emotion.py b/modules/deepface-master/deepface/extendedmodels/Emotion.py
new file mode 100644
index 000000000..41214a182
--- /dev/null
+++ b/modules/deepface-master/deepface/extendedmodels/Emotion.py
@@ -0,0 +1,78 @@
+import os
+import gdown
+import tensorflow as tf
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="extendedmodels.Emotion")
+
+# -------------------------------------------
+# pylint: disable=line-too-long
+# -------------------------------------------
+# dependency configuration
+tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
+
+if tf_version == 1:
+ from keras.models import Sequential
+ from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D, Flatten, Dense, Dropout
+else:
+ from tensorflow.keras.models import Sequential
+ from tensorflow.keras.layers import (
+ Conv2D,
+ MaxPooling2D,
+ AveragePooling2D,
+ Flatten,
+ Dense,
+ Dropout,
+ )
+# -------------------------------------------
+
+# Labels for the emotions that can be detected by the model.
+labels = ["angry", "disgust", "fear", "happy", "sad", "surprise", "neutral"]
+
+
+def loadModel(
+ url="https://github.com/serengil/deepface_models/releases/download/v1.0/facial_expression_model_weights.h5",
+) -> Sequential:
+
+ num_classes = 7
+
+ model = Sequential()
+
+ # 1st convolution layer
+ model.add(Conv2D(64, (5, 5), activation="relu", input_shape=(48, 48, 1)))
+ model.add(MaxPooling2D(pool_size=(5, 5), strides=(2, 2)))
+
+ # 2nd convolution layer
+ model.add(Conv2D(64, (3, 3), activation="relu"))
+ model.add(Conv2D(64, (3, 3), activation="relu"))
+ model.add(AveragePooling2D(pool_size=(3, 3), strides=(2, 2)))
+
+ # 3rd convolution layer
+ model.add(Conv2D(128, (3, 3), activation="relu"))
+ model.add(Conv2D(128, (3, 3), activation="relu"))
+ model.add(AveragePooling2D(pool_size=(3, 3), strides=(2, 2)))
+
+ model.add(Flatten())
+
+ # fully connected neural networks
+ model.add(Dense(1024, activation="relu"))
+ model.add(Dropout(0.2))
+ model.add(Dense(1024, activation="relu"))
+ model.add(Dropout(0.2))
+
+ model.add(Dense(num_classes, activation="softmax"))
+
+ # ----------------------------
+
+ home = functions.get_deepface_home()
+
+ if os.path.isfile(home + "/.deepface/weights/facial_expression_model_weights.h5") != True:
+ logger.info("facial_expression_model_weights.h5 will be downloaded...")
+
+ output = home + "/.deepface/weights/facial_expression_model_weights.h5"
+ gdown.download(url, output, quiet=False)
+
+ model.load_weights(home + "/.deepface/weights/facial_expression_model_weights.h5")
+
+ return model
diff --git a/modules/deepface-master/deepface/extendedmodels/Gender.py b/modules/deepface-master/deepface/extendedmodels/Gender.py
new file mode 100644
index 000000000..d53f6f257
--- /dev/null
+++ b/modules/deepface-master/deepface/extendedmodels/Gender.py
@@ -0,0 +1,61 @@
+import os
+import gdown
+import tensorflow as tf
+from deepface.basemodels import VGGFace
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="extendedmodels.Gender")
+
+# -------------------------------------
+# pylint: disable=line-too-long
+# -------------------------------------
+# dependency configurations
+
+tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
+
+if tf_version == 1:
+ from keras.models import Model, Sequential
+ from keras.layers import Convolution2D, Flatten, Activation
+else:
+ from tensorflow.keras.models import Model, Sequential
+ from tensorflow.keras.layers import Convolution2D, Flatten, Activation
+# -------------------------------------
+
+# Labels for the genders that can be detected by the model.
+labels = ["Woman", "Man"]
+
+
+def loadModel(
+ url="https://github.com/serengil/deepface_models/releases/download/v1.0/gender_model_weights.h5",
+) -> Model:
+
+ model = VGGFace.baseModel()
+
+ # --------------------------
+
+ classes = 2
+ base_model_output = Sequential()
+ base_model_output = Convolution2D(classes, (1, 1), name="predictions")(model.layers[-4].output)
+ base_model_output = Flatten()(base_model_output)
+ base_model_output = Activation("softmax")(base_model_output)
+
+ # --------------------------
+
+ gender_model = Model(inputs=model.input, outputs=base_model_output)
+
+ # --------------------------
+
+ # load weights
+
+ home = functions.get_deepface_home()
+
+ if os.path.isfile(home + "/.deepface/weights/gender_model_weights.h5") != True:
+ logger.info("gender_model_weights.h5 will be downloaded...")
+
+ output = home + "/.deepface/weights/gender_model_weights.h5"
+ gdown.download(url, output, quiet=False)
+
+ gender_model.load_weights(home + "/.deepface/weights/gender_model_weights.h5")
+
+ return gender_model
diff --git a/modules/deepface-master/deepface/extendedmodels/Race.py b/modules/deepface-master/deepface/extendedmodels/Race.py
new file mode 100644
index 000000000..50087c10b
--- /dev/null
+++ b/modules/deepface-master/deepface/extendedmodels/Race.py
@@ -0,0 +1,59 @@
+import os
+import gdown
+import tensorflow as tf
+from deepface.basemodels import VGGFace
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="extendedmodels.Race")
+
+# --------------------------
+# pylint: disable=line-too-long
+# --------------------------
+# dependency configurations
+tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
+
+if tf_version == 1:
+ from keras.models import Model, Sequential
+ from keras.layers import Convolution2D, Flatten, Activation
+else:
+ from tensorflow.keras.models import Model, Sequential
+ from tensorflow.keras.layers import Convolution2D, Flatten, Activation
+# --------------------------
+# Labels for the ethnic phenotypes that can be detected by the model.
+labels = ["asian", "indian", "black", "white", "middle eastern", "latino hispanic"]
+
+
+def loadModel(
+ url="https://github.com/serengil/deepface_models/releases/download/v1.0/race_model_single_batch.h5",
+) -> Model:
+
+ model = VGGFace.baseModel()
+
+ # --------------------------
+
+ classes = 6
+ base_model_output = Sequential()
+ base_model_output = Convolution2D(classes, (1, 1), name="predictions")(model.layers[-4].output)
+ base_model_output = Flatten()(base_model_output)
+ base_model_output = Activation("softmax")(base_model_output)
+
+ # --------------------------
+
+ race_model = Model(inputs=model.input, outputs=base_model_output)
+
+ # --------------------------
+
+ # load weights
+
+ home = functions.get_deepface_home()
+
+ if os.path.isfile(home + "/.deepface/weights/race_model_single_batch.h5") != True:
+ logger.info("race_model_single_batch.h5 will be downloaded...")
+
+ output = home + "/.deepface/weights/race_model_single_batch.h5"
+ gdown.download(url, output, quiet=False)
+
+ race_model.load_weights(home + "/.deepface/weights/race_model_single_batch.h5")
+
+ return race_model
diff --git a/modules/deepface-master/deepface/extendedmodels/__init__.py b/modules/deepface-master/deepface/extendedmodels/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/modules/deepface-master/deepface/models/__init__.py b/modules/deepface-master/deepface/models/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/modules/deepface-master/deepface/modules/__init__.py b/modules/deepface-master/deepface/modules/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/modules/deepface-master/deepface/modules/demography.py b/modules/deepface-master/deepface/modules/demography.py
new file mode 100644
index 000000000..664b85ab6
--- /dev/null
+++ b/modules/deepface-master/deepface/modules/demography.py
@@ -0,0 +1,184 @@
+# built-in dependencies
+from typing import Any, Dict, List, Union
+
+# 3rd party dependencies
+import numpy as np
+from tqdm import tqdm
+import cv2
+
+# project dependencies
+from deepface.modules import modeling
+from deepface.commons import functions
+from deepface.extendedmodels import Age, Gender, Race, Emotion
+
+
+def analyze(
+ img_path: Union[str, np.ndarray],
+ actions: Union[tuple, list] = ("emotion", "age", "gender", "race"),
+ enforce_detection: bool = True,
+ detector_backend: str = "opencv",
+ align: bool = True,
+ silent: bool = False,
+) -> List[Dict[str, Any]]:
+ """
+ This function analyzes facial attributes including age, gender, emotion and race.
+ In the background, analysis function builds convolutional neural network models to
+ classify age, gender, emotion and race of the input image.
+
+ Parameters:
+ img_path: exact image path, numpy array (BGR) or base64 encoded image could be passed.
+ If source image has more than one face, then result will be size of number of faces
+ appearing in the image.
+
+ actions (tuple): The default is ('age', 'gender', 'emotion', 'race'). You can drop
+ some of those attributes.
+
+ enforce_detection (bool): The function throws exception if no face detected by default.
+ Set this to False if you don't want to get exception. This might be convenient for low
+ resolution images.
+
+ detector_backend (string): set face detector backend to opencv, retinaface, mtcnn, ssd,
+ dlib, mediapipe or yolov8.
+
+ align (boolean): alignment according to the eye positions.
+
+ silent (boolean): disable (some) log messages
+
+ Returns:
+ The function returns a list of dictionaries for each face appearing in the image.
+
+ [
+ {
+ "region": {'x': 230, 'y': 120, 'w': 36, 'h': 45},
+ "age": 28.66,
+ 'face_confidence': 0.9993908405303955,
+ "dominant_gender": "Woman",
+ "gender": {
+ 'Woman': 99.99407529830933,
+ 'Man': 0.005928758764639497,
+ }
+ "dominant_emotion": "neutral",
+ "emotion": {
+ 'sad': 37.65260875225067,
+ 'angry': 0.15512987738475204,
+ 'surprise': 0.0022171278033056296,
+ 'fear': 1.2489334680140018,
+ 'happy': 4.609785228967667,
+ 'disgust': 9.698561953541684e-07,
+ 'neutral': 56.33133053779602
+ }
+ "dominant_race": "white",
+ "race": {
+ 'indian': 0.5480832420289516,
+ 'asian': 0.7830780930817127,
+ 'latino hispanic': 2.0677512511610985,
+ 'black': 0.06337375962175429,
+ 'middle eastern': 3.088453598320484,
+ 'white': 93.44925880432129
+ }
+ }
+ ]
+ """
+ # ---------------------------------
+ # validate actions
+ if isinstance(actions, str):
+ actions = (actions,)
+
+ # check if actions is not an iterable or empty.
+ if not hasattr(actions, "__getitem__") or not actions:
+ raise ValueError("`actions` must be a list of strings.")
+
+ actions = list(actions)
+
+ # For each action, check if it is valid
+ for action in actions:
+ if action not in ("emotion", "age", "gender", "race"):
+ raise ValueError(
+ f"Invalid action passed ({repr(action)})). "
+ "Valid actions are `emotion`, `age`, `gender`, `race`."
+ )
+ # ---------------------------------
+ resp_objects = []
+
+ img_objs = functions.extract_faces(
+ img=img_path,
+ target_size=(224, 224),
+ detector_backend=detector_backend,
+ grayscale=False,
+ enforce_detection=enforce_detection,
+ align=align,
+ )
+
+ for img_content, img_region, img_confidence in img_objs:
+ if img_content.shape[0] > 0 and img_content.shape[1] > 0:
+ obj = {}
+ # facial attribute analysis
+ pbar = tqdm(
+ range(0, len(actions)),
+ desc="Finding actions",
+ disable=silent if len(actions) > 1 else True,
+ )
+ for index in pbar:
+ action = actions[index]
+ pbar.set_description(f"Action: {action}")
+
+ if action == "emotion":
+ img_gray = cv2.cvtColor(img_content[0], cv2.COLOR_BGR2GRAY)
+ img_gray = cv2.resize(img_gray, (48, 48))
+ img_gray = np.expand_dims(img_gray, axis=0)
+
+ emotion_predictions = modeling.build_model("Emotion").predict(
+ img_gray, verbose=0
+ )[0, :]
+
+ sum_of_predictions = emotion_predictions.sum()
+
+ obj["emotion"] = {}
+
+ for i, emotion_label in enumerate(Emotion.labels):
+ emotion_prediction = 100 * emotion_predictions[i] / sum_of_predictions
+ obj["emotion"][emotion_label] = emotion_prediction
+
+ obj["dominant_emotion"] = Emotion.labels[np.argmax(emotion_predictions)]
+
+ elif action == "age":
+ age_predictions = modeling.build_model("Age").predict(img_content, verbose=0)[
+ 0, :
+ ]
+ apparent_age = Age.findApparentAge(age_predictions)
+ # int cast is for exception - object of type 'float32' is not JSON serializable
+ obj["age"] = int(apparent_age)
+
+ elif action == "gender":
+ gender_predictions = modeling.build_model("Gender").predict(
+ img_content, verbose=0
+ )[0, :]
+ obj["gender"] = {}
+ for i, gender_label in enumerate(Gender.labels):
+ gender_prediction = 100 * gender_predictions[i]
+ obj["gender"][gender_label] = gender_prediction
+
+ obj["dominant_gender"] = Gender.labels[np.argmax(gender_predictions)]
+
+ elif action == "race":
+ race_predictions = modeling.build_model("Race").predict(img_content, verbose=0)[
+ 0, :
+ ]
+ sum_of_predictions = race_predictions.sum()
+
+ obj["race"] = {}
+ for i, race_label in enumerate(Race.labels):
+ race_prediction = 100 * race_predictions[i] / sum_of_predictions
+ obj["race"][race_label] = race_prediction
+
+ obj["dominant_race"] = Race.labels[np.argmax(race_predictions)]
+
+ # -----------------------------
+ # mention facial areas
+ obj["region"] = img_region
+ # include image confidence
+ obj["face_confidence"] = img_confidence
+
+ resp_objects.append(obj)
+
+ return resp_objects
diff --git a/modules/deepface-master/deepface/modules/detection.py b/modules/deepface-master/deepface/modules/detection.py
new file mode 100644
index 000000000..ae92aaaa3
--- /dev/null
+++ b/modules/deepface-master/deepface/modules/detection.py
@@ -0,0 +1,72 @@
+# built-in dependencies
+from typing import Any, Dict, List, Tuple, Union
+
+# 3rd part dependencies
+import numpy as np
+
+# project dependencies
+from deepface.commons import functions
+
+
+def extract_faces(
+ img_path: Union[str, np.ndarray],
+ target_size: Tuple[int, int] = (224, 224),
+ detector_backend: str = "opencv",
+ enforce_detection: bool = True,
+ align: bool = True,
+ grayscale: bool = False,
+) -> List[Dict[str, Any]]:
+ """
+ This function applies pre-processing stages of a face recognition pipeline
+ including detection and alignment
+
+ Parameters:
+ img_path: exact image path, numpy array (BGR) or base64 encoded image.
+ Source image can have many face. Then, result will be the size of number
+ of faces appearing in that source image.
+
+ target_size (tuple): final shape of facial image. black pixels will be
+ added to resize the image.
+
+ detector_backend (string): face detection backends are retinaface, mtcnn,
+ opencv, ssd or dlib
+
+ enforce_detection (boolean): function throws exception if face cannot be
+ detected in the fed image. Set this to False if you do not want to get
+ an exception and run the function anyway.
+
+ align (boolean): alignment according to the eye positions.
+
+ grayscale (boolean): extracting faces in rgb or gray scale
+
+ Returns:
+ list of dictionaries. Each dictionary will have facial image itself (RGB),
+ extracted area from the original image and confidence score.
+
+ """
+
+ resp_objs = []
+
+ img_objs = functions.extract_faces(
+ img=img_path,
+ target_size=target_size,
+ detector_backend=detector_backend,
+ grayscale=grayscale,
+ enforce_detection=enforce_detection,
+ align=align,
+ )
+
+ for img, region, confidence in img_objs:
+ resp_obj = {}
+
+ # discard expanded dimension
+ if len(img.shape) == 4:
+ img = img[0]
+
+ # bgr to rgb
+ resp_obj["face"] = img[:, :, ::-1]
+ resp_obj["facial_area"] = region
+ resp_obj["confidence"] = confidence
+ resp_objs.append(resp_obj)
+
+ return resp_objs
diff --git a/modules/deepface-master/deepface/modules/modeling.py b/modules/deepface-master/deepface/modules/modeling.py
new file mode 100644
index 000000000..8936dabc3
--- /dev/null
+++ b/modules/deepface-master/deepface/modules/modeling.py
@@ -0,0 +1,71 @@
+# built-in dependencies
+from typing import Any, Union
+
+# 3rd party dependencies
+import tensorflow as tf
+
+# project dependencies
+from deepface.basemodels import (
+ VGGFace,
+ OpenFace,
+ Facenet,
+ Facenet512,
+ FbDeepFace,
+ DeepID,
+ DlibWrapper,
+ ArcFace,
+ SFace,
+)
+from deepface.extendedmodels import Age, Gender, Race, Emotion
+
+# conditional dependencies
+tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
+if tf_version == 2:
+ from tensorflow.keras.models import Model
+else:
+ from keras.models import Model
+
+
+def build_model(model_name: str) -> Union[Model, Any]:
+ """
+ This function builds a deepface model
+ Parameters:
+ model_name (string): face recognition or facial attribute model
+ VGG-Face, Facenet, OpenFace, DeepFace, DeepID for face recognition
+ Age, Gender, Emotion, Race for facial attributes
+
+ Returns:
+ built deepface model ( (tf.)keras.models.Model )
+ """
+
+ # singleton design pattern
+ global model_obj
+
+ models = {
+ "VGG-Face": VGGFace.loadModel,
+ "OpenFace": OpenFace.loadModel,
+ "Facenet": Facenet.loadModel,
+ "Facenet512": Facenet512.loadModel,
+ "DeepFace": FbDeepFace.loadModel,
+ "DeepID": DeepID.loadModel,
+ "Dlib": DlibWrapper.loadModel,
+ "ArcFace": ArcFace.loadModel,
+ "SFace": SFace.load_model,
+ "Emotion": Emotion.loadModel,
+ "Age": Age.loadModel,
+ "Gender": Gender.loadModel,
+ "Race": Race.loadModel,
+ }
+
+ if not "model_obj" in globals():
+ model_obj = {}
+
+ if not model_name in model_obj:
+ model = models.get(model_name)
+ if model:
+ model = model()
+ model_obj[model_name] = model
+ else:
+ raise ValueError(f"Invalid model_name passed - {model_name}")
+
+ return model_obj[model_name]
diff --git a/modules/deepface-master/deepface/modules/realtime.py b/modules/deepface-master/deepface/modules/realtime.py
new file mode 100644
index 000000000..3edd5d86a
--- /dev/null
+++ b/modules/deepface-master/deepface/modules/realtime.py
@@ -0,0 +1,717 @@
+import os
+import time
+import numpy as np
+import pandas as pd
+import cv2
+from deepface import DeepFace
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger(module="commons.realtime")
+
+# dependency configuration
+os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
+
+# pylint: disable=too-many-nested-blocks
+
+
+def analysis(
+ db_path,
+ model_name="VGG-Face",
+ detector_backend="opencv",
+ distance_metric="cosine",
+ enable_face_analysis=True,
+ source=0,
+ time_threshold=5,
+ frame_threshold=5,
+):
+ # global variables
+ text_color = (255, 255, 255)
+ pivot_img_size = 112 # face recognition result image
+
+ enable_emotion = True
+ enable_age_gender = True
+ # ------------------------
+ # find custom values for this input set
+ target_size = functions.find_target_size(model_name=model_name)
+ # ------------------------
+ # build models once to store them in the memory
+ # otherwise, they will be built after cam started and this will cause delays
+ DeepFace.build_model(model_name=model_name)
+ logger.info(f"facial recognition model {model_name} is just built")
+
+ if enable_face_analysis:
+ DeepFace.build_model(model_name="Age")
+ logger.info("Age model is just built")
+ DeepFace.build_model(model_name="Gender")
+ logger.info("Gender model is just built")
+ DeepFace.build_model(model_name="Emotion")
+ logger.info("Emotion model is just built")
+ # -----------------------
+ # call a dummy find function for db_path once to create embeddings in the initialization
+ DeepFace.find(
+ img_path=np.zeros([224, 224, 3]),
+ db_path=db_path,
+ model_name=model_name,
+ detector_backend=detector_backend,
+ distance_metric=distance_metric,
+ enforce_detection=False,
+ )
+ # -----------------------
+ # visualization
+ freeze = False
+ face_detected = False
+ face_included_frames = 0 # freeze screen if face detected sequantially 5 frames
+ freezed_frame = 0
+ tic = time.time()
+
+ cap = cv2.VideoCapture(source) # webcam
+ while True:
+ _, img = cap.read()
+
+ if img is None:
+ break
+
+ # cv2.namedWindow('img', cv2.WINDOW_FREERATIO)
+ # cv2.setWindowProperty('img', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
+
+ raw_img = img.copy()
+ resolution_x = img.shape[1]
+ resolution_y = img.shape[0]
+
+ if freeze == False:
+ try:
+ # just extract the regions to highlight in webcam
+ face_objs = DeepFace.extract_faces(
+ img_path=img,
+ target_size=target_size,
+ detector_backend=detector_backend,
+ enforce_detection=False,
+ )
+ faces = []
+ for face_obj in face_objs:
+ facial_area = face_obj["facial_area"]
+ faces.append(
+ (
+ facial_area["x"],
+ facial_area["y"],
+ facial_area["w"],
+ facial_area["h"],
+ )
+ )
+ except: # to avoid exception if no face detected
+ faces = []
+
+ if len(faces) == 0:
+ face_included_frames = 0
+ else:
+ faces = []
+
+ detected_faces = []
+ face_index = 0
+ for x, y, w, h in faces:
+ if w > 130: # discard small detected faces
+
+ face_detected = True
+ if face_index == 0:
+ face_included_frames = (
+ face_included_frames + 1
+ ) # increase frame for a single face
+
+ cv2.rectangle(
+ img, (x, y), (x + w, y + h), (67, 67, 67), 1
+ ) # draw rectangle to main image
+
+ cv2.putText(
+ img,
+ str(frame_threshold - face_included_frames),
+ (int(x + w / 4), int(y + h / 1.5)),
+ cv2.FONT_HERSHEY_SIMPLEX,
+ 4,
+ (255, 255, 255),
+ 2,
+ )
+
+ detected_face = img[int(y) : int(y + h), int(x) : int(x + w)] # crop detected face
+
+ # -------------------------------------
+
+ detected_faces.append((x, y, w, h))
+ face_index = face_index + 1
+
+ # -------------------------------------
+
+ if face_detected == True and face_included_frames == frame_threshold and freeze == False:
+ freeze = True
+ # base_img = img.copy()
+ base_img = raw_img.copy()
+ detected_faces_final = detected_faces.copy()
+ tic = time.time()
+
+ if freeze == True:
+
+ toc = time.time()
+ if (toc - tic) < time_threshold:
+
+ if freezed_frame == 0:
+ freeze_img = base_img.copy()
+ # here, np.uint8 handles showing white area issue
+ # freeze_img = np.zeros(resolution, np.uint8)
+
+ for detected_face in detected_faces_final:
+ x = detected_face[0]
+ y = detected_face[1]
+ w = detected_face[2]
+ h = detected_face[3]
+
+ cv2.rectangle(
+ freeze_img, (x, y), (x + w, y + h), (67, 67, 67), 1
+ ) # draw rectangle to main image
+
+ # -------------------------------
+ # extract detected face
+ custom_face = base_img[y : y + h, x : x + w]
+ # -------------------------------
+ # facial attribute analysis
+
+ if enable_face_analysis == True:
+
+ demographies = DeepFace.analyze(
+ img_path=custom_face,
+ detector_backend=detector_backend,
+ enforce_detection=False,
+ silent=True,
+ )
+
+ if len(demographies) > 0:
+ # directly access 1st face cos img is extracted already
+ demography = demographies[0]
+
+ if enable_emotion:
+ emotion = demography["emotion"]
+ emotion_df = pd.DataFrame(
+ emotion.items(), columns=["emotion", "score"]
+ )
+ emotion_df = emotion_df.sort_values(
+ by=["score"], ascending=False
+ ).reset_index(drop=True)
+
+ # background of mood box
+
+ # transparency
+ overlay = freeze_img.copy()
+ opacity = 0.4
+
+ if x + w + pivot_img_size < resolution_x:
+ # right
+ cv2.rectangle(
+ freeze_img
+ # , (x+w,y+20)
+ ,
+ (x + w, y),
+ (x + w + pivot_img_size, y + h),
+ (64, 64, 64),
+ cv2.FILLED,
+ )
+
+ cv2.addWeighted(
+ overlay, opacity, freeze_img, 1 - opacity, 0, freeze_img
+ )
+
+ elif x - pivot_img_size > 0:
+ # left
+ cv2.rectangle(
+ freeze_img
+ # , (x-pivot_img_size,y+20)
+ ,
+ (x - pivot_img_size, y),
+ (x, y + h),
+ (64, 64, 64),
+ cv2.FILLED,
+ )
+
+ cv2.addWeighted(
+ overlay, opacity, freeze_img, 1 - opacity, 0, freeze_img
+ )
+
+ for index, instance in emotion_df.iterrows():
+ current_emotion = instance["emotion"]
+ emotion_label = f"{current_emotion} "
+ emotion_score = instance["score"] / 100
+
+ bar_x = 35 # this is the size if an emotion is 100%
+ bar_x = int(bar_x * emotion_score)
+
+ if x + w + pivot_img_size < resolution_x:
+
+ text_location_y = y + 20 + (index + 1) * 20
+ text_location_x = x + w
+
+ if text_location_y < y + h:
+ cv2.putText(
+ freeze_img,
+ emotion_label,
+ (text_location_x, text_location_y),
+ cv2.FONT_HERSHEY_SIMPLEX,
+ 0.5,
+ (255, 255, 255),
+ 1,
+ )
+
+ cv2.rectangle(
+ freeze_img,
+ (x + w + 70, y + 13 + (index + 1) * 20),
+ (
+ x + w + 70 + bar_x,
+ y + 13 + (index + 1) * 20 + 5,
+ ),
+ (255, 255, 255),
+ cv2.FILLED,
+ )
+
+ elif x - pivot_img_size > 0:
+
+ text_location_y = y + 20 + (index + 1) * 20
+ text_location_x = x - pivot_img_size
+
+ if text_location_y <= y + h:
+ cv2.putText(
+ freeze_img,
+ emotion_label,
+ (text_location_x, text_location_y),
+ cv2.FONT_HERSHEY_SIMPLEX,
+ 0.5,
+ (255, 255, 255),
+ 1,
+ )
+
+ cv2.rectangle(
+ freeze_img,
+ (
+ x - pivot_img_size + 70,
+ y + 13 + (index + 1) * 20,
+ ),
+ (
+ x - pivot_img_size + 70 + bar_x,
+ y + 13 + (index + 1) * 20 + 5,
+ ),
+ (255, 255, 255),
+ cv2.FILLED,
+ )
+
+ if enable_age_gender:
+ apparent_age = demography["age"]
+ dominant_gender = demography["dominant_gender"]
+ gender = "M" if dominant_gender == "Man" else "W"
+ logger.debug(f"{apparent_age} years old {dominant_gender}")
+ analysis_report = str(int(apparent_age)) + " " + gender
+
+ # -------------------------------
+
+ info_box_color = (46, 200, 255)
+
+ # top
+ if y - pivot_img_size + int(pivot_img_size / 5) > 0:
+
+ triangle_coordinates = np.array(
+ [
+ (x + int(w / 2), y),
+ (
+ x + int(w / 2) - int(w / 10),
+ y - int(pivot_img_size / 3),
+ ),
+ (
+ x + int(w / 2) + int(w / 10),
+ y - int(pivot_img_size / 3),
+ ),
+ ]
+ )
+
+ cv2.drawContours(
+ freeze_img,
+ [triangle_coordinates],
+ 0,
+ info_box_color,
+ -1,
+ )
+
+ cv2.rectangle(
+ freeze_img,
+ (
+ x + int(w / 5),
+ y - pivot_img_size + int(pivot_img_size / 5),
+ ),
+ (x + w - int(w / 5), y - int(pivot_img_size / 3)),
+ info_box_color,
+ cv2.FILLED,
+ )
+
+ cv2.putText(
+ freeze_img,
+ analysis_report,
+ (x + int(w / 3.5), y - int(pivot_img_size / 2.1)),
+ cv2.FONT_HERSHEY_SIMPLEX,
+ 1,
+ (0, 111, 255),
+ 2,
+ )
+
+ # bottom
+ elif (
+ y + h + pivot_img_size - int(pivot_img_size / 5)
+ < resolution_y
+ ):
+
+ triangle_coordinates = np.array(
+ [
+ (x + int(w / 2), y + h),
+ (
+ x + int(w / 2) - int(w / 10),
+ y + h + int(pivot_img_size / 3),
+ ),
+ (
+ x + int(w / 2) + int(w / 10),
+ y + h + int(pivot_img_size / 3),
+ ),
+ ]
+ )
+
+ cv2.drawContours(
+ freeze_img,
+ [triangle_coordinates],
+ 0,
+ info_box_color,
+ -1,
+ )
+
+ cv2.rectangle(
+ freeze_img,
+ (x + int(w / 5), y + h + int(pivot_img_size / 3)),
+ (
+ x + w - int(w / 5),
+ y + h + pivot_img_size - int(pivot_img_size / 5),
+ ),
+ info_box_color,
+ cv2.FILLED,
+ )
+
+ cv2.putText(
+ freeze_img,
+ analysis_report,
+ (x + int(w / 3.5), y + h + int(pivot_img_size / 1.5)),
+ cv2.FONT_HERSHEY_SIMPLEX,
+ 1,
+ (0, 111, 255),
+ 2,
+ )
+
+ # --------------------------------
+ # face recognition
+ # call find function for custom_face
+
+ dfs = DeepFace.find(
+ img_path=custom_face,
+ db_path=db_path,
+ model_name=model_name,
+ detector_backend=detector_backend,
+ distance_metric=distance_metric,
+ enforce_detection=False,
+ silent=True,
+ )
+
+ if len(dfs) > 0:
+ # directly access 1st item because custom face is extracted already
+ df = dfs[0]
+
+ if df.shape[0] > 0:
+ candidate = df.iloc[0]
+ label = candidate["identity"]
+
+ # to use this source image as is
+ display_img = cv2.imread(label)
+ # to use extracted face
+ source_objs = DeepFace.extract_faces(
+ img_path=label,
+ target_size=(pivot_img_size, pivot_img_size),
+ detector_backend=detector_backend,
+ enforce_detection=False,
+ align=False,
+ )
+
+ if len(source_objs) > 0:
+ # extract 1st item directly
+ source_obj = source_objs[0]
+ display_img = source_obj["face"]
+ display_img *= 255
+ display_img = display_img[:, :, ::-1]
+ # --------------------
+ label = label.split("/")[-1]
+
+ try:
+ if (
+ y - pivot_img_size > 0
+ and x + w + pivot_img_size < resolution_x
+ ):
+ # top right
+ freeze_img[
+ y - pivot_img_size : y,
+ x + w : x + w + pivot_img_size,
+ ] = display_img
+
+ overlay = freeze_img.copy()
+ opacity = 0.4
+ cv2.rectangle(
+ freeze_img,
+ (x + w, y),
+ (x + w + pivot_img_size, y + 20),
+ (46, 200, 255),
+ cv2.FILLED,
+ )
+ cv2.addWeighted(
+ overlay,
+ opacity,
+ freeze_img,
+ 1 - opacity,
+ 0,
+ freeze_img,
+ )
+
+ cv2.putText(
+ freeze_img,
+ label,
+ (x + w, y + 10),
+ cv2.FONT_HERSHEY_SIMPLEX,
+ 0.5,
+ text_color,
+ 1,
+ )
+
+ # connect face and text
+ cv2.line(
+ freeze_img,
+ (x + int(w / 2), y),
+ (x + 3 * int(w / 4), y - int(pivot_img_size / 2)),
+ (67, 67, 67),
+ 1,
+ )
+ cv2.line(
+ freeze_img,
+ (x + 3 * int(w / 4), y - int(pivot_img_size / 2)),
+ (x + w, y - int(pivot_img_size / 2)),
+ (67, 67, 67),
+ 1,
+ )
+
+ elif (
+ y + h + pivot_img_size < resolution_y
+ and x - pivot_img_size > 0
+ ):
+ # bottom left
+ freeze_img[
+ y + h : y + h + pivot_img_size,
+ x - pivot_img_size : x,
+ ] = display_img
+
+ overlay = freeze_img.copy()
+ opacity = 0.4
+ cv2.rectangle(
+ freeze_img,
+ (x - pivot_img_size, y + h - 20),
+ (x, y + h),
+ (46, 200, 255),
+ cv2.FILLED,
+ )
+ cv2.addWeighted(
+ overlay,
+ opacity,
+ freeze_img,
+ 1 - opacity,
+ 0,
+ freeze_img,
+ )
+
+ cv2.putText(
+ freeze_img,
+ label,
+ (x - pivot_img_size, y + h - 10),
+ cv2.FONT_HERSHEY_SIMPLEX,
+ 0.5,
+ text_color,
+ 1,
+ )
+
+ # connect face and text
+ cv2.line(
+ freeze_img,
+ (x + int(w / 2), y + h),
+ (
+ x + int(w / 2) - int(w / 4),
+ y + h + int(pivot_img_size / 2),
+ ),
+ (67, 67, 67),
+ 1,
+ )
+ cv2.line(
+ freeze_img,
+ (
+ x + int(w / 2) - int(w / 4),
+ y + h + int(pivot_img_size / 2),
+ ),
+ (x, y + h + int(pivot_img_size / 2)),
+ (67, 67, 67),
+ 1,
+ )
+
+ elif y - pivot_img_size > 0 and x - pivot_img_size > 0:
+ # top left
+ freeze_img[
+ y - pivot_img_size : y, x - pivot_img_size : x
+ ] = display_img
+
+ overlay = freeze_img.copy()
+ opacity = 0.4
+ cv2.rectangle(
+ freeze_img,
+ (x - pivot_img_size, y),
+ (x, y + 20),
+ (46, 200, 255),
+ cv2.FILLED,
+ )
+ cv2.addWeighted(
+ overlay,
+ opacity,
+ freeze_img,
+ 1 - opacity,
+ 0,
+ freeze_img,
+ )
+
+ cv2.putText(
+ freeze_img,
+ label,
+ (x - pivot_img_size, y + 10),
+ cv2.FONT_HERSHEY_SIMPLEX,
+ 0.5,
+ text_color,
+ 1,
+ )
+
+ # connect face and text
+ cv2.line(
+ freeze_img,
+ (x + int(w / 2), y),
+ (
+ x + int(w / 2) - int(w / 4),
+ y - int(pivot_img_size / 2),
+ ),
+ (67, 67, 67),
+ 1,
+ )
+ cv2.line(
+ freeze_img,
+ (
+ x + int(w / 2) - int(w / 4),
+ y - int(pivot_img_size / 2),
+ ),
+ (x, y - int(pivot_img_size / 2)),
+ (67, 67, 67),
+ 1,
+ )
+
+ elif (
+ x + w + pivot_img_size < resolution_x
+ and y + h + pivot_img_size < resolution_y
+ ):
+ # bottom righ
+ freeze_img[
+ y + h : y + h + pivot_img_size,
+ x + w : x + w + pivot_img_size,
+ ] = display_img
+
+ overlay = freeze_img.copy()
+ opacity = 0.4
+ cv2.rectangle(
+ freeze_img,
+ (x + w, y + h - 20),
+ (x + w + pivot_img_size, y + h),
+ (46, 200, 255),
+ cv2.FILLED,
+ )
+ cv2.addWeighted(
+ overlay,
+ opacity,
+ freeze_img,
+ 1 - opacity,
+ 0,
+ freeze_img,
+ )
+
+ cv2.putText(
+ freeze_img,
+ label,
+ (x + w, y + h - 10),
+ cv2.FONT_HERSHEY_SIMPLEX,
+ 0.5,
+ text_color,
+ 1,
+ )
+
+ # connect face and text
+ cv2.line(
+ freeze_img,
+ (x + int(w / 2), y + h),
+ (
+ x + int(w / 2) + int(w / 4),
+ y + h + int(pivot_img_size / 2),
+ ),
+ (67, 67, 67),
+ 1,
+ )
+ cv2.line(
+ freeze_img,
+ (
+ x + int(w / 2) + int(w / 4),
+ y + h + int(pivot_img_size / 2),
+ ),
+ (x + w, y + h + int(pivot_img_size / 2)),
+ (67, 67, 67),
+ 1,
+ )
+ except Exception as err: # pylint: disable=broad-except
+ logger.error(str(err))
+
+ tic = time.time() # in this way, freezed image can show 5 seconds
+
+ # -------------------------------
+
+ time_left = int(time_threshold - (toc - tic) + 1)
+
+ cv2.rectangle(freeze_img, (10, 10), (90, 50), (67, 67, 67), -10)
+ cv2.putText(
+ freeze_img,
+ str(time_left),
+ (40, 40),
+ cv2.FONT_HERSHEY_SIMPLEX,
+ 1,
+ (255, 255, 255),
+ 1,
+ )
+
+ cv2.imshow("img", freeze_img)
+
+ freezed_frame = freezed_frame + 1
+ else:
+ face_detected = False
+ face_included_frames = 0
+ freeze = False
+ freezed_frame = 0
+
+ else:
+ cv2.imshow("img", img)
+
+ if cv2.waitKey(1) & 0xFF == ord("q"): # press q to quit
+ break
+
+ # kill open cv things
+ cap.release()
+ cv2.destroyAllWindows()
diff --git a/modules/deepface-master/deepface/modules/recognition.py b/modules/deepface-master/deepface/modules/recognition.py
new file mode 100644
index 000000000..00d58493b
--- /dev/null
+++ b/modules/deepface-master/deepface/modules/recognition.py
@@ -0,0 +1,346 @@
+# built-in dependencies
+import os
+import pickle
+from typing import List, Union
+import time
+
+# 3rd party dependencies
+import numpy as np
+import pandas as pd
+from tqdm import tqdm
+
+# project dependencies
+from deepface.commons import functions, distance as dst
+from deepface.commons.logger import Logger
+from deepface.modules import representation
+
+logger = Logger(module="deepface/modules/recognition.py")
+
+
+def find(
+ img_path: Union[str, np.ndarray],
+ db_path: str,
+ model_name: str = "VGG-Face",
+ distance_metric: str = "cosine",
+ enforce_detection: bool = True,
+ detector_backend: str = "opencv",
+ align: bool = True,
+ normalization: str = "base",
+ silent: bool = False,
+) -> List[pd.DataFrame]:
+ """
+ This function applies verification several times and find the identities in a database
+
+ Parameters:
+ img_path: exact image path, numpy array (BGR) or based64 encoded image.
+ Source image can have many faces. Then, result will be the size of number of
+ faces in the source image.
+
+ db_path (string): You should store some image files in a folder and pass the
+ exact folder path to this. A database image can also have many faces.
+ Then, all detected faces in db side will be considered in the decision.
+
+ model_name (string): VGG-Face, Facenet, Facenet512, OpenFace, DeepFace, DeepID,
+ Dlib, ArcFace, SFace or Ensemble
+
+ distance_metric (string): cosine, euclidean, euclidean_l2
+
+ enforce_detection (bool): The function throws exception if a face could not be detected.
+ Set this to False if you don't want to get exception. This might be convenient for low
+ resolution images.
+
+ detector_backend (string): set face detector backend to opencv, retinaface, mtcnn, ssd,
+ dlib, mediapipe or yolov8.
+
+ align (boolean): alignment according to the eye positions.
+
+ normalization (string): normalize the input image before feeding to model
+
+ silent (boolean): disable some logging and progress bars
+
+ Returns:
+ This function returns list of pandas data frame. Each item of the list corresponding to
+ an identity in the img_path.
+ """
+
+ tic = time.time()
+
+ # -------------------------------
+ if os.path.isdir(db_path) is not True:
+ raise ValueError("Passed db_path does not exist!")
+
+ target_size = functions.find_target_size(model_name=model_name)
+
+ # ---------------------------------------
+
+ file_name = f"representations_{model_name}.pkl"
+ file_name = file_name.replace("-", "_").lower()
+ datastore_path = f"{db_path}/{file_name}"
+
+ df_cols = [
+ "identity",
+ f"{model_name}_representation",
+ "target_x",
+ "target_y",
+ "target_w",
+ "target_h",
+ ]
+
+ if os.path.exists(datastore_path):
+ with open(datastore_path, "rb") as f:
+ representations = pickle.load(f)
+
+ if len(representations) > 0 and len(representations[0]) != len(df_cols):
+ raise ValueError(
+ f"Seems existing {datastore_path} is out-of-the-date."
+ "Please delete it and re-run."
+ )
+
+ alpha_employees = __list_images(path=db_path)
+ beta_employees = [representation[0] for representation in representations]
+
+ newbies = list(set(alpha_employees) - set(beta_employees))
+ oldies = list(set(beta_employees) - set(alpha_employees))
+
+ if newbies:
+ logger.warn(
+ f"Items {newbies} were added into {db_path}"
+ f" just after data source {datastore_path} created!"
+ )
+ newbies_representations = __find_bulk_embeddings(
+ employees=newbies,
+ model_name=model_name,
+ target_size=target_size,
+ detector_backend=detector_backend,
+ enforce_detection=enforce_detection,
+ align=align,
+ normalization=normalization,
+ silent=silent,
+ )
+ representations = representations + newbies_representations
+
+ if oldies:
+ logger.warn(
+ f"Items {oldies} were dropped from {db_path}"
+ f" just after data source {datastore_path} created!"
+ )
+ representations = [rep for rep in representations if rep[0] not in oldies]
+
+ if newbies or oldies:
+ if len(representations) == 0:
+ raise ValueError(f"There is no image in {db_path} anymore!")
+
+ # save new representations
+ with open(datastore_path, "wb") as f:
+ pickle.dump(representations, f)
+
+ if not silent:
+ logger.info(
+ f"{len(newbies)} new representations are just added"
+ f" whereas {len(oldies)} represented one(s) are just dropped"
+ f" in {db_path}/{file_name} file."
+ )
+
+ if not silent:
+ logger.info(f"There are {len(representations)} representations found in {file_name}")
+
+ else: # create representation.pkl from scratch
+ employees = __list_images(path=db_path)
+
+ if len(employees) == 0:
+ raise ValueError(
+ f"There is no image in {db_path} folder!"
+ "Validate .jpg, .jpeg or .png files exist in this path.",
+ )
+
+ # ------------------------
+ # find representations for db images
+ representations = __find_bulk_embeddings(
+ employees=employees,
+ model_name=model_name,
+ target_size=target_size,
+ detector_backend=detector_backend,
+ enforce_detection=enforce_detection,
+ align=align,
+ normalization=normalization,
+ silent=silent,
+ )
+
+ # -------------------------------
+
+ with open(datastore_path, "wb") as f:
+ pickle.dump(representations, f)
+
+ if not silent:
+ logger.info(f"Representations stored in {db_path}/{file_name} file.")
+
+ # ----------------------------
+ # now, we got representations for facial database
+ df = pd.DataFrame(
+ representations,
+ columns=df_cols,
+ )
+
+ # img path might have more than once face
+ source_objs = functions.extract_faces(
+ img=img_path,
+ target_size=target_size,
+ detector_backend=detector_backend,
+ grayscale=False,
+ enforce_detection=enforce_detection,
+ align=align,
+ )
+
+ resp_obj = []
+
+ for source_img, source_region, _ in source_objs:
+ target_embedding_obj = representation.represent(
+ img_path=source_img,
+ model_name=model_name,
+ enforce_detection=enforce_detection,
+ detector_backend="skip",
+ align=align,
+ normalization=normalization,
+ )
+
+ target_representation = target_embedding_obj[0]["embedding"]
+
+ result_df = df.copy() # df will be filtered in each img
+ result_df["source_x"] = source_region["x"]
+ result_df["source_y"] = source_region["y"]
+ result_df["source_w"] = source_region["w"]
+ result_df["source_h"] = source_region["h"]
+
+ distances = []
+ for _, instance in df.iterrows():
+ source_representation = instance[f"{model_name}_representation"]
+
+ target_dims = len(list(target_representation))
+ source_dims = len(list(source_representation))
+ if target_dims != source_dims:
+ raise ValueError(
+ "Source and target embeddings must have same dimensions but "
+ + f"{target_dims}:{source_dims}. Model structure may change"
+ + " after pickle created. Delete the {file_name} and re-run."
+ )
+
+ if distance_metric == "cosine":
+ distance = dst.findCosineDistance(source_representation, target_representation)
+ elif distance_metric == "euclidean":
+ distance = dst.findEuclideanDistance(source_representation, target_representation)
+ elif distance_metric == "euclidean_l2":
+ distance = dst.findEuclideanDistance(
+ dst.l2_normalize(source_representation),
+ dst.l2_normalize(target_representation),
+ )
+ else:
+ raise ValueError(f"invalid distance metric passes - {distance_metric}")
+
+ distances.append(distance)
+
+ # ---------------------------
+
+ result_df[f"{model_name}_{distance_metric}"] = distances
+
+ threshold = dst.findThreshold(model_name, distance_metric)
+ result_df = result_df.drop(columns=[f"{model_name}_representation"])
+ # pylint: disable=unsubscriptable-object
+ result_df = result_df[result_df[f"{model_name}_{distance_metric}"] <= threshold]
+ result_df = result_df.sort_values(
+ by=[f"{model_name}_{distance_metric}"], ascending=True
+ ).reset_index(drop=True)
+
+ resp_obj.append(result_df)
+
+ # -----------------------------------
+
+ toc = time.time()
+
+ if not silent:
+ logger.info(f"find function lasts {toc - tic} seconds")
+
+ return resp_obj
+
+
+def __list_images(path: str) -> list:
+ """
+ List images in a given path
+ Args:
+ path (str): path's location
+ Returns:
+ images (list): list of exact image paths
+ """
+ images = []
+ for r, _, f in os.walk(path):
+ for file in f:
+ if file.lower().endswith((".jpg", ".jpeg", ".png")):
+ exact_path = f"{r}/{file}"
+ images.append(exact_path)
+ return images
+
+
+def __find_bulk_embeddings(
+ employees: List[str],
+ model_name: str = "VGG-Face",
+ target_size: tuple = (224, 224),
+ detector_backend: str = "opencv",
+ enforce_detection: bool = True,
+ align: bool = True,
+ normalization: str = "base",
+ silent: bool = False,
+):
+ """
+ Find embeddings of a list of images
+
+ Args:
+ employees (list): list of exact image paths
+ model_name (str): facial recognition model name
+ target_size (tuple): expected input shape of facial
+ recognition model
+ detector_backend (str): face detector model name
+ enforce_detection (bool): set this to False if you
+ want to proceed when you cannot detect any face
+ align (bool): enable or disable alignment of image
+ before feeding to facial recognition model
+ normalization (bool): normalization technique
+ silent (bool): enable or disable informative logging
+ Returns:
+ representations (list): pivot list of embeddings with
+ image name and detected face area's coordinates
+ """
+ representations = []
+ for employee in tqdm(
+ employees,
+ desc="Finding representations",
+ disable=silent,
+ ):
+ img_objs = functions.extract_faces(
+ img=employee,
+ target_size=target_size,
+ detector_backend=detector_backend,
+ grayscale=False,
+ enforce_detection=enforce_detection,
+ align=align,
+ )
+
+ for img_content, img_region, _ in img_objs:
+ embedding_obj = representation.represent(
+ img_path=img_content,
+ model_name=model_name,
+ enforce_detection=enforce_detection,
+ detector_backend="skip",
+ align=align,
+ normalization=normalization,
+ )
+
+ img_representation = embedding_obj[0]["embedding"]
+
+ instance = []
+ instance.append(employee)
+ instance.append(img_representation)
+ instance.append(img_region["x"])
+ instance.append(img_region["y"])
+ instance.append(img_region["w"])
+ instance.append(img_region["h"])
+ representations.append(instance)
+ return representations
diff --git a/modules/deepface-master/deepface/modules/representation.py b/modules/deepface-master/deepface/modules/representation.py
new file mode 100644
index 000000000..ab2e01db2
--- /dev/null
+++ b/modules/deepface-master/deepface/modules/representation.py
@@ -0,0 +1,129 @@
+# built-in dependencies
+from typing import Any, Dict, List, Union
+
+# 3rd party dependencies
+import numpy as np
+import cv2
+import tensorflow as tf
+
+# project dependencies
+from deepface.modules import modeling
+from deepface.commons import functions
+
+# conditional dependencies
+tf_version = int(tf.__version__.split(".", maxsplit=1)[0])
+if tf_version == 2:
+ from tensorflow.keras.models import Model
+else:
+ from keras.models import Model
+
+
+def represent(
+ img_path: Union[str, np.ndarray],
+ model_name: str = "VGG-Face",
+ enforce_detection: bool = True,
+ detector_backend: str = "opencv",
+ align: bool = True,
+ normalization: str = "base",
+) -> List[Dict[str, Any]]:
+ """
+ This function represents facial images as vectors. The function uses convolutional neural
+ networks models to generate vector embeddings.
+
+ Parameters:
+ img_path (string): exact image path. Alternatively, numpy array (BGR) or based64
+ encoded images could be passed. Source image can have many faces. Then, result will
+ be the size of number of faces appearing in the source image.
+
+ model_name (string): VGG-Face, Facenet, Facenet512, OpenFace, DeepFace, DeepID, Dlib,
+ ArcFace, SFace
+
+ enforce_detection (boolean): If no face could not be detected in an image, then this
+ function will return exception by default. Set this to False not to have this exception.
+ This might be convenient for low resolution images.
+
+ detector_backend (string): set face detector backend to opencv, retinaface, mtcnn, ssd,
+ dlib, mediapipe or yolov8. A special value `skip` could be used to skip face-detection
+ and only encode the given image.
+
+ align (boolean): alignment according to the eye positions.
+
+ normalization (string): normalize the input image before feeding to model
+
+ Returns:
+ Represent function returns a list of object, each object has fields as follows:
+ {
+ // Multidimensional vector
+ // The number of dimensions is changing based on the reference model.
+ // E.g. FaceNet returns 128 dimensional vector;
+ // VGG-Face returns 2622 dimensional vector.
+ "embedding": np.array,
+
+ // Detected Facial-Area by Face detection in dict format.
+ // (x, y) is left-corner point, and (w, h) is the width and height
+ // If `detector_backend` == `skip`, it is the full image area and nonsense.
+ "facial_area": dict{"x": int, "y": int, "w": int, "h": int},
+
+ // Face detection confidence.
+ // If `detector_backend` == `skip`, will be 0 and nonsense.
+ "face_confidence": float
+ }
+ """
+ resp_objs = []
+
+ model = modeling.build_model(model_name)
+
+ # ---------------------------------
+ # we have run pre-process in verification. so, this can be skipped if it is coming from verify.
+ target_size = functions.find_target_size(model_name=model_name)
+ if detector_backend != "skip":
+ img_objs = functions.extract_faces(
+ img=img_path,
+ target_size=target_size,
+ detector_backend=detector_backend,
+ grayscale=False,
+ enforce_detection=enforce_detection,
+ align=align,
+ )
+ else: # skip
+ # Try load. If load error, will raise exception internal
+ img, _ = functions.load_image(img_path)
+ # --------------------------------
+ if len(img.shape) == 4:
+ img = img[0] # e.g. (1, 224, 224, 3) to (224, 224, 3)
+ if len(img.shape) == 3:
+ img = cv2.resize(img, target_size)
+ img = np.expand_dims(img, axis=0)
+ # when called from verify, this is already normalized. But needed when user given.
+ if img.max() > 1:
+ img = (img.astype(np.float32) / 255.0).astype(np.float32)
+ # --------------------------------
+ # make dummy region and confidence to keep compatibility with `extract_faces`
+ img_region = {"x": 0, "y": 0, "w": img.shape[1], "h": img.shape[2]}
+ img_objs = [(img, img_region, 0)]
+ # ---------------------------------
+
+ for img, region, confidence in img_objs:
+ # custom normalization
+ img = functions.normalize_input(img=img, normalization=normalization)
+
+ # represent
+ # if "keras" in str(type(model)):
+ if isinstance(model, Model):
+ # model.predict causes memory issue when it is called in a for loop
+ # embedding = model.predict(img, verbose=0)[0].tolist()
+ embedding = model(img, training=False).numpy()[0].tolist()
+ # if you still get verbose logging. try call
+ # - `tf.keras.utils.disable_interactive_logging()`
+ # in your main program
+ else:
+ # SFace and Dlib are not keras models and no verbose arguments
+ embedding = model.predict(img)[0].tolist()
+
+ resp_obj = {}
+ resp_obj["embedding"] = embedding
+ resp_obj["facial_area"] = region
+ resp_obj["face_confidence"] = confidence
+ resp_objs.append(resp_obj)
+
+ return resp_objs
diff --git a/modules/deepface-master/deepface/modules/verification.py b/modules/deepface-master/deepface/modules/verification.py
new file mode 100644
index 000000000..b5dc8fa82
--- /dev/null
+++ b/modules/deepface-master/deepface/modules/verification.py
@@ -0,0 +1,151 @@
+# built-in dependencies
+import time
+from typing import Any, Dict, Union
+
+# 3rd party dependencies
+import numpy as np
+
+# project dependencies
+from deepface.commons import functions, distance as dst
+from deepface.modules import representation
+
+
+def verify(
+ img1_path: Union[str, np.ndarray],
+ img2_path: Union[str, np.ndarray],
+ model_name: str = "VGG-Face",
+ detector_backend: str = "opencv",
+ distance_metric: str = "cosine",
+ enforce_detection: bool = True,
+ align: bool = True,
+ normalization: str = "base",
+) -> Dict[str, Any]:
+ """
+ This function verifies an image pair is same person or different persons. In the background,
+ verification function represents facial images as vectors and then calculates the similarity
+ between those vectors. Vectors of same person images should have more similarity (or less
+ distance) than vectors of different persons.
+
+ Parameters:
+ img1_path, img2_path: exact image path as string. numpy array (BGR) or based64 encoded
+ images are also welcome. If one of pair has more than one face, then we will compare the
+ face pair with max similarity.
+
+ model_name (str): VGG-Face, Facenet, Facenet512, OpenFace, DeepFace, DeepID, Dlib
+ , ArcFace and SFace
+
+ distance_metric (string): cosine, euclidean, euclidean_l2
+
+ enforce_detection (boolean): If no face could not be detected in an image, then this
+ function will return exception by default. Set this to False not to have this exception.
+ This might be convenient for low resolution images.
+
+ detector_backend (string): set face detector backend to opencv, retinaface, mtcnn, ssd,
+ dlib, mediapipe or yolov8.
+
+ align (boolean): alignment according to the eye positions.
+
+ normalization (string): normalize the input image before feeding to model
+
+ Returns:
+ Verify function returns a dictionary.
+
+ {
+ "verified": True
+ , "distance": 0.2563
+ , "max_threshold_to_verify": 0.40
+ , "model": "VGG-Face"
+ , "similarity_metric": "cosine"
+ , 'facial_areas': {
+ 'img1': {'x': 345, 'y': 211, 'w': 769, 'h': 769},
+ 'img2': {'x': 318, 'y': 534, 'w': 779, 'h': 779}
+ }
+ , "time": 2
+ }
+
+ """
+
+ tic = time.time()
+
+ # --------------------------------
+ target_size = functions.find_target_size(model_name=model_name)
+
+ # img pairs might have many faces
+ img1_objs = functions.extract_faces(
+ img=img1_path,
+ target_size=target_size,
+ detector_backend=detector_backend,
+ grayscale=False,
+ enforce_detection=enforce_detection,
+ align=align,
+ )
+
+ img2_objs = functions.extract_faces(
+ img=img2_path,
+ target_size=target_size,
+ detector_backend=detector_backend,
+ grayscale=False,
+ enforce_detection=enforce_detection,
+ align=align,
+ )
+ # --------------------------------
+ distances = []
+ regions = []
+ # now we will find the face pair with minimum distance
+ for img1_content, img1_region, _ in img1_objs:
+ for img2_content, img2_region, _ in img2_objs:
+ img1_embedding_obj = representation.represent(
+ img_path=img1_content,
+ model_name=model_name,
+ enforce_detection=enforce_detection,
+ detector_backend="skip",
+ align=align,
+ normalization=normalization,
+ )
+
+ img2_embedding_obj = representation.represent(
+ img_path=img2_content,
+ model_name=model_name,
+ enforce_detection=enforce_detection,
+ detector_backend="skip",
+ align=align,
+ normalization=normalization,
+ )
+
+ img1_representation = img1_embedding_obj[0]["embedding"]
+ img2_representation = img2_embedding_obj[0]["embedding"]
+
+ if distance_metric == "cosine":
+ distance = dst.findCosineDistance(img1_representation, img2_representation)
+ elif distance_metric == "euclidean":
+ distance = dst.findEuclideanDistance(img1_representation, img2_representation)
+ elif distance_metric == "euclidean_l2":
+ distance = dst.findEuclideanDistance(
+ dst.l2_normalize(img1_representation), dst.l2_normalize(img2_representation)
+ )
+ else:
+ raise ValueError("Invalid distance_metric passed - ", distance_metric)
+
+ distances.append(distance)
+ regions.append((img1_region, img2_region))
+
+ # -------------------------------
+ threshold = dst.findThreshold(model_name, distance_metric)
+ distance = min(distances) # best distance
+ facial_areas = regions[np.argmin(distances)]
+
+ toc = time.time()
+
+ # pylint: disable=simplifiable-if-expression
+ resp_obj = {
+ "verified": True if distance <= threshold else False,
+ "distance": distance,
+ "threshold": threshold,
+ "model": model_name,
+ "detector_backend": detector_backend,
+ "similarity_metric": distance_metric,
+ "facial_areas": {"img1": facial_areas[0], "img2": facial_areas[1]},
+ "time": round(toc - tic, 2),
+ }
+
+ return resp_obj
diff --git a/modules/deepface-master/icon/deepface-api.jpg b/modules/deepface-master/icon/deepface-api.jpg
new file mode 100644
index 000000000..8ca3fec14
Binary files /dev/null and b/modules/deepface-master/icon/deepface-api.jpg differ
diff --git a/modules/deepface-master/icon/deepface-detectors-v3.jpg b/modules/deepface-master/icon/deepface-detectors-v3.jpg
new file mode 100644
index 000000000..0e9a62078
Binary files /dev/null and b/modules/deepface-master/icon/deepface-detectors-v3.jpg differ
diff --git a/modules/deepface-master/icon/deepface-dockerized-v2.jpg b/modules/deepface-master/icon/deepface-dockerized-v2.jpg
new file mode 100644
index 000000000..db79929b1
Binary files /dev/null and b/modules/deepface-master/icon/deepface-dockerized-v2.jpg differ
diff --git a/modules/deepface-master/icon/deepface-icon-labeled.png b/modules/deepface-master/icon/deepface-icon-labeled.png
new file mode 100644
index 000000000..520887c9d
Binary files /dev/null and b/modules/deepface-master/icon/deepface-icon-labeled.png differ
diff --git a/modules/deepface-master/icon/deepface-icon.png b/modules/deepface-master/icon/deepface-icon.png
new file mode 100644
index 000000000..d0a3b9b9a
Binary files /dev/null and b/modules/deepface-master/icon/deepface-icon.png differ
diff --git a/modules/deepface-master/icon/detector-portfolio-v3.jpg b/modules/deepface-master/icon/detector-portfolio-v3.jpg
new file mode 100644
index 000000000..d67642ae9
Binary files /dev/null and b/modules/deepface-master/icon/detector-portfolio-v3.jpg differ
diff --git a/modules/deepface-master/icon/detector-portfolio-v5.jpg b/modules/deepface-master/icon/detector-portfolio-v5.jpg
new file mode 100644
index 000000000..e35cef157
Binary files /dev/null and b/modules/deepface-master/icon/detector-portfolio-v5.jpg differ
diff --git a/modules/deepface-master/icon/embedding.jpg b/modules/deepface-master/icon/embedding.jpg
new file mode 100644
index 000000000..855591328
Binary files /dev/null and b/modules/deepface-master/icon/embedding.jpg differ
diff --git a/modules/deepface-master/icon/look-alike-v3.jpg b/modules/deepface-master/icon/look-alike-v3.jpg
new file mode 100644
index 000000000..19d439c62
Binary files /dev/null and b/modules/deepface-master/icon/look-alike-v3.jpg differ
diff --git a/modules/deepface-master/icon/model-portfolio-v8.jpg b/modules/deepface-master/icon/model-portfolio-v8.jpg
new file mode 100644
index 000000000..b359f00ed
Binary files /dev/null and b/modules/deepface-master/icon/model-portfolio-v8.jpg differ
diff --git a/modules/deepface-master/icon/parental-look-alike-v2.jpg b/modules/deepface-master/icon/parental-look-alike-v2.jpg
new file mode 100644
index 000000000..bd08ddfe5
Binary files /dev/null and b/modules/deepface-master/icon/parental-look-alike-v2.jpg differ
diff --git a/modules/deepface-master/icon/patreon.png b/modules/deepface-master/icon/patreon.png
new file mode 100644
index 000000000..21cbfd96a
Binary files /dev/null and b/modules/deepface-master/icon/patreon.png differ
diff --git a/modules/deepface-master/icon/retinaface-results.jpeg b/modules/deepface-master/icon/retinaface-results.jpeg
new file mode 100644
index 000000000..11e5db900
Binary files /dev/null and b/modules/deepface-master/icon/retinaface-results.jpeg differ
diff --git a/modules/deepface-master/icon/stock-1.jpg b/modules/deepface-master/icon/stock-1.jpg
new file mode 100644
index 000000000..b786042db
Binary files /dev/null and b/modules/deepface-master/icon/stock-1.jpg differ
diff --git a/modules/deepface-master/icon/stock-2.jpg b/modules/deepface-master/icon/stock-2.jpg
new file mode 100644
index 000000000..4e542ea76
Binary files /dev/null and b/modules/deepface-master/icon/stock-2.jpg differ
diff --git a/modules/deepface-master/icon/stock-3.jpg b/modules/deepface-master/icon/stock-3.jpg
new file mode 100644
index 000000000..68254cb71
Binary files /dev/null and b/modules/deepface-master/icon/stock-3.jpg differ
diff --git a/modules/deepface-master/icon/stock-6-v2.jpg b/modules/deepface-master/icon/stock-6-v2.jpg
new file mode 100644
index 000000000..a7fe5ac09
Binary files /dev/null and b/modules/deepface-master/icon/stock-6-v2.jpg differ
diff --git a/modules/deepface-master/icon/tech-stack-v2.jpg b/modules/deepface-master/icon/tech-stack-v2.jpg
new file mode 100644
index 000000000..32a69f71a
Binary files /dev/null and b/modules/deepface-master/icon/tech-stack-v2.jpg differ
diff --git a/modules/deepface-master/icon/verify-many-faces.jpg b/modules/deepface-master/icon/verify-many-faces.jpg
new file mode 100644
index 000000000..66fc890b8
Binary files /dev/null and b/modules/deepface-master/icon/verify-many-faces.jpg differ
diff --git a/modules/deepface-master/requirements.txt b/modules/deepface-master/requirements.txt
new file mode 100644
index 000000000..0f1dabab1
--- /dev/null
+++ b/modules/deepface-master/requirements.txt
@@ -0,0 +1,14 @@
+numpy>=1.14.0
+pandas>=0.23.4
+gdown>=3.10.1
+tqdm>=4.30.0
+Pillow>=5.2.0
+opencv-python>=4.5.5.64
+tensorflow>=1.9.0
+keras>=2.2.0
+Flask>=1.1.2
+mtcnn>=0.1.0
+retina-face>=0.0.1
+fire>=0.4.0
+gunicorn>=20.1.0
+Deprecated>=1.2.13
\ No newline at end of file
diff --git a/modules/deepface-master/requirements_additional.txt b/modules/deepface-master/requirements_additional.txt
new file mode 100644
index 000000000..0344661d6
--- /dev/null
+++ b/modules/deepface-master/requirements_additional.txt
@@ -0,0 +1,5 @@
+opencv-contrib-python>=4.3.0.36
+mediapipe>=0.8.7.3
+dlib>=19.20.0
+ultralytics>=8.0.122
+facenet-pytorch>=2.5.3
\ No newline at end of file
diff --git a/modules/deepface-master/scripts/dockerize.sh b/modules/deepface-master/scripts/dockerize.sh
new file mode 100644
index 000000000..0d5ac6e00
--- /dev/null
+++ b/modules/deepface-master/scripts/dockerize.sh
@@ -0,0 +1,27 @@
+# Dockerfile is in the root
+cd ..
+
+# start docker
+# sudo service docker start
+
+# list current docker packages
+# docker container ls -a
+
+# delete existing deepface packages
+# docker rm -f $(docker ps -a -q --filter "ancestor=deepface")
+
+# build deepface image
+docker build -t deepface .
+
+# copy weights from your local
+# docker cp ~/.deepface/weights/. :/root/.deepface/weights/
+
+# run image
+docker run --net="host" deepface
+
+# to access the inside of docker image when it is in running status
+# docker exec -it /bin/sh
+
+# healthcheck
+# sleep 3s
+# curl localhost:5000
\ No newline at end of file
diff --git a/modules/deepface-master/scripts/push-release.sh b/modules/deepface-master/scripts/push-release.sh
new file mode 100644
index 000000000..5b3e6fac5
--- /dev/null
+++ b/modules/deepface-master/scripts/push-release.sh
@@ -0,0 +1,11 @@
+cd ..
+
+echo "deleting existing release related files"
+rm -rf dist/*
+rm -rf build/*
+
+echo "creating a package for current release - pypi compatible"
+python setup.py sdist bdist_wheel
+
+echo "pushing the release to pypi"
+python -m twine upload dist/*
\ No newline at end of file
diff --git a/modules/deepface-master/scripts/service.sh b/modules/deepface-master/scripts/service.sh
new file mode 100644
index 000000000..c1444f5e3
--- /dev/null
+++ b/modules/deepface-master/scripts/service.sh
@@ -0,0 +1,3 @@
+#!/usr/bin/env bash
+cd ../api
+gunicorn --workers=1 --timeout=3600 --bind=0.0.0.0:5000 "app:create_app()"
\ No newline at end of file
diff --git a/modules/deepface-master/setup.py b/modules/deepface-master/setup.py
new file mode 100644
index 000000000..b34c34b89
--- /dev/null
+++ b/modules/deepface-master/setup.py
@@ -0,0 +1,30 @@
+import setuptools
+
+with open("README.md", "r", encoding="utf-8") as fh:
+ long_description = fh.read()
+
+with open("requirements.txt", "r", encoding="utf-8") as f:
+ requirements = f.read().split("\n")
+
+setuptools.setup(
+ name="deepface",
+ version="0.0.82",
+ author="Sefik Ilkin Serengil",
+ author_email="serengil@gmail.com",
+ description="A Lightweight Face Recognition and Facial Attribute Analysis Framework (Age, Gender, Emotion, Race) for Python",
+ data_files=[("", ["README.md", "requirements.txt"])],
+ long_description=long_description,
+ long_description_content_type="text/markdown",
+ url="https://github.com/serengil/deepface",
+ packages=setuptools.find_packages(),
+ classifiers=[
+ "Programming Language :: Python :: 3",
+ "License :: OSI Approved :: MIT License",
+ "Operating System :: OS Independent",
+ ],
+ entry_points={
+ "console_scripts": ["deepface = deepface.DeepFace:cli"],
+ },
+ python_requires=">=3.5.5",
+ install_requires=requirements,
+)
diff --git a/modules/deepface-master/tests/dataset/couple.jpg b/modules/deepface-master/tests/dataset/couple.jpg
new file mode 100644
index 000000000..1a07d7663
Binary files /dev/null and b/modules/deepface-master/tests/dataset/couple.jpg differ
diff --git a/modules/deepface-master/tests/dataset/face-recognition-pivot.csv b/modules/deepface-master/tests/dataset/face-recognition-pivot.csv
new file mode 100644
index 000000000..7c3f68be0
--- /dev/null
+++ b/modules/deepface-master/tests/dataset/face-recognition-pivot.csv
@@ -0,0 +1,281 @@
+file_x,file_y,decision,VGG-Face_cosine,VGG-Face_euclidean,VGG-Face_euclidean_l2,Facenet_cosine,Facenet_euclidean,Facenet_euclidean_l2,OpenFace_cosine,OpenFace_euclidean_l2,DeepFace_cosine,DeepFace_euclidean,DeepFace_euclidean_l2
+deepface/tests/dataset/img38.jpg,deepface/tests/dataset/img39.jpg,Yes,0.2057,0.389,0.6414,0.1601,6.8679,0.5658,0.5925,1.0886,0.2554,61.3336,0.7147
+deepface/tests/dataset/img38.jpg,deepface/tests/dataset/img40.jpg,Yes,0.2117,0.3179,0.6508,0.2739,8.9049,0.7402,0.396,0.8899,0.2685,63.3747,0.7328
+deepface/tests/dataset/img38.jpg,deepface/tests/dataset/img41.jpg,Yes,0.1073,0.2482,0.4632,0.1257,6.1593,0.5014,0.7157,1.1964,0.2452,60.3454,0.7002
+deepface/tests/dataset/img39.jpg,deepface/tests/dataset/img40.jpg,Yes,0.2991,0.4567,0.7734,0.3134,9.3798,0.7917,0.4941,0.9941,0.1703,45.1688,0.5836
+deepface/tests/dataset/img39.jpg,deepface/tests/dataset/img41.jpg,Yes,0.1666,0.3542,0.5772,0.1502,6.6491,0.5481,0.2381,0.6901,0.2194,50.4356,0.6624
+deepface/tests/dataset/img40.jpg,deepface/tests/dataset/img41.jpg,Yes,0.1706,0.3066,0.5841,0.2017,7.6423,0.6352,0.567,1.0649,0.2423,54.2499,0.6961
+deepface/tests/dataset/img3.jpg,deepface/tests/dataset/img12.jpg,Yes,0.2533,0.5199,0.7118,0.4062,11.2632,0.9014,0.1908,0.6178,0.2337,58.8794,0.6837
+deepface/tests/dataset/img3.jpg,deepface/tests/dataset/img53.jpg,Yes,0.1655,0.3567,0.5754,0.184,7.5388,0.6066,0.1465,0.5412,0.243,55.2642,0.6971
+deepface/tests/dataset/img3.jpg,deepface/tests/dataset/img54.jpg,Yes,0.1982,0.4739,0.6297,0.406,11.0618,0.9011,0.1132,0.4758,0.1824,49.7875,0.6041
+deepface/tests/dataset/img3.jpg,deepface/tests/dataset/img55.jpg,Yes,0.1835,0.3742,0.6057,0.1366,6.4168,0.5227,0.1755,0.5924,0.1697,55.179,0.5825
+deepface/tests/dataset/img3.jpg,deepface/tests/dataset/img56.jpg,Yes,0.1652,0.4005,0.5748,0.1833,7.3432,0.6054,0.1803,0.6005,0.2061,59.007,0.642
+deepface/tests/dataset/img12.jpg,deepface/tests/dataset/img53.jpg,Yes,0.372,0.6049,0.8626,0.3933,11.1382,0.8869,0.1068,0.4621,0.1633,48.5516,0.5715
+deepface/tests/dataset/img12.jpg,deepface/tests/dataset/img54.jpg,Yes,0.2153,0.5145,0.6561,0.2694,9.1155,0.734,0.1943,0.6234,0.1881,52.7146,0.6133
+deepface/tests/dataset/img12.jpg,deepface/tests/dataset/img55.jpg,Yes,0.3551,0.5941,0.8428,0.4726,12.0647,0.9722,0.1054,0.4591,0.1265,48.2432,0.5029
+deepface/tests/dataset/img12.jpg,deepface/tests/dataset/img56.jpg,Yes,0.2826,0.565,0.7518,0.4761,11.9569,0.9758,0.1364,0.5224,0.1908,57.6735,0.6177
+deepface/tests/dataset/img53.jpg,deepface/tests/dataset/img54.jpg,Yes,0.3363,0.593,0.8202,0.4627,11.8744,0.962,0.1964,0.6267,0.174,46.6212,0.5898
+deepface/tests/dataset/img53.jpg,deepface/tests/dataset/img55.jpg,Yes,0.187,0.3313,0.6116,0.1625,7.0394,0.5701,0.1312,0.5123,0.1439,52.3132,0.5365
+deepface/tests/dataset/img53.jpg,deepface/tests/dataset/img56.jpg,Yes,0.1385,0.3776,0.5263,0.141,6.4913,0.5311,0.1285,0.507,0.2005,58.0586,0.6332
+deepface/tests/dataset/img54.jpg,deepface/tests/dataset/img55.jpg,Yes,0.3124,0.5756,0.7905,0.4033,10.944,0.8981,0.1738,0.5896,0.1351,49.8255,0.5198
+deepface/tests/dataset/img54.jpg,deepface/tests/dataset/img56.jpg,Yes,0.2571,0.5473,0.717,0.3912,10.6329,0.8846,0.1802,0.6002,0.1648,53.0881,0.574
+deepface/tests/dataset/img55.jpg,deepface/tests/dataset/img56.jpg,Yes,0.2217,0.4543,0.6658,0.1433,6.4387,0.5353,0.1677,0.5792,0.1505,53.6812,0.5486
+deepface/tests/dataset/img1.jpg,deepface/tests/dataset/img2.jpg,Yes,0.2342,0.5033,0.6844,0.2508,8.2369,0.7082,0.0844,0.4109,0.2417,64.2748,0.6952
+deepface/tests/dataset/img1.jpg,deepface/tests/dataset/img4.jpg,Yes,0.2051,0.3916,0.6405,0.2766,8.7946,0.7437,0.1662,0.5766,0.2292,64.7785,0.6771
+deepface/tests/dataset/img1.jpg,deepface/tests/dataset/img5.jpg,Yes,0.2963,0.3948,0.7699,0.2696,8.4689,0.7343,0.0965,0.4393,0.2306,71.6647,0.679
+deepface/tests/dataset/img1.jpg,deepface/tests/dataset/img6.jpg,Yes,0.254,0.4464,0.7128,0.2164,7.7171,0.6579,0.0691,0.3718,0.2365,64.7594,0.6877
+deepface/tests/dataset/img1.jpg,deepface/tests/dataset/img7.jpg,Yes,0.3104,0.4764,0.7879,0.2112,7.5718,0.65,0.1027,0.4531,0.2385,61.371,0.6906
+deepface/tests/dataset/img1.jpg,deepface/tests/dataset/img10.jpg,Yes,0.3363,0.5448,0.8202,0.2129,7.6484,0.6525,0.0661,0.3635,0.2472,65.0668,0.7031
+deepface/tests/dataset/img1.jpg,deepface/tests/dataset/img11.jpg,Yes,0.3083,0.5416,0.7852,0.2042,7.6195,0.639,0.1626,0.5703,0.2001,61.3824,0.6326
+deepface/tests/dataset/img2.jpg,deepface/tests/dataset/img4.jpg,Yes,0.1397,0.3961,0.5285,0.1957,7.351,0.6256,0.2497,0.7066,0.1349,51.5853,0.5194
+deepface/tests/dataset/img2.jpg,deepface/tests/dataset/img5.jpg,Yes,0.1995,0.482,0.6317,0.1574,6.4195,0.561,0.1333,0.5164,0.1583,60.6365,0.5627
+deepface/tests/dataset/img2.jpg,deepface/tests/dataset/img6.jpg,Yes,0.0908,0.3251,0.4261,0.0787,4.625,0.3969,0.0632,0.3556,0.0756,38.218,0.3888
+deepface/tests/dataset/img2.jpg,deepface/tests/dataset/img7.jpg,Yes,0.2,0.4664,0.6325,0.1642,6.6261,0.5731,0.1049,0.4581,0.098,42.1113,0.4428
+deepface/tests/dataset/img2.jpg,deepface/tests/dataset/img10.jpg,Yes,0.2077,0.4862,0.6444,0.1593,6.5693,0.5644,0.0589,0.3431,0.1118,45.9168,0.4729
+deepface/tests/dataset/img2.jpg,deepface/tests/dataset/img11.jpg,Yes,0.2349,0.5235,0.6854,0.1869,7.2485,0.6114,0.1029,0.4536,0.1548,55.617,0.5564
+deepface/tests/dataset/img4.jpg,deepface/tests/dataset/img5.jpg,Yes,0.1991,0.3869,0.6311,0.1199,5.7256,0.4898,0.2891,0.7604,0.1797,64.7925,0.5995
+deepface/tests/dataset/img4.jpg,deepface/tests/dataset/img6.jpg,Yes,0.1937,0.4095,0.6224,0.1772,7.0495,0.5954,0.2199,0.6632,0.1788,59.9202,0.598
+deepface/tests/dataset/img4.jpg,deepface/tests/dataset/img7.jpg,Yes,0.245,0.4526,0.7,0.1663,6.7868,0.5767,0.3435,0.8289,0.1971,61.177,0.6279
+deepface/tests/dataset/img4.jpg,deepface/tests/dataset/img10.jpg,Yes,0.1882,0.4274,0.6136,0.1304,6.0445,0.5107,0.2052,0.6406,0.1239,49.4937,0.4979
+deepface/tests/dataset/img4.jpg,deepface/tests/dataset/img11.jpg,Yes,0.2569,0.5093,0.7168,0.1909,7.4277,0.618,0.2874,0.7582,0.1737,59.8839,0.5894
+deepface/tests/dataset/img5.jpg,deepface/tests/dataset/img6.jpg,Yes,0.1858,0.3915,0.6095,0.1818,6.967,0.6029,0.13,0.5099,0.1742,63.6179,0.5903
+deepface/tests/dataset/img5.jpg,deepface/tests/dataset/img7.jpg,Yes,0.2639,0.4391,0.7264,0.1754,6.7894,0.5923,0.1174,0.4846,0.1523,59.6056,0.5519
+deepface/tests/dataset/img5.jpg,deepface/tests/dataset/img10.jpg,Yes,0.2013,0.4449,0.6344,0.1143,5.525,0.478,0.1228,0.4957,0.1942,66.7805,0.6232
+deepface/tests/dataset/img5.jpg,deepface/tests/dataset/img11.jpg,Yes,0.3348,0.5599,0.8183,0.1975,7.4008,0.6285,0.2071,0.6436,0.1692,63.0817,0.5818
+deepface/tests/dataset/img6.jpg,deepface/tests/dataset/img7.jpg,Yes,0.192,0.4085,0.6196,0.1275,5.892,0.505,0.1004,0.4482,0.094,42.0465,0.4335
+deepface/tests/dataset/img6.jpg,deepface/tests/dataset/img10.jpg,Yes,0.214,0.4593,0.6542,0.1237,5.8374,0.4974,0.0517,0.3216,0.11,46.1197,0.4691
+deepface/tests/dataset/img6.jpg,deepface/tests/dataset/img11.jpg,Yes,0.2755,0.5319,0.7423,0.1772,7.1072,0.5953,0.1383,0.526,0.1771,59.9849,0.5951
+deepface/tests/dataset/img7.jpg,deepface/tests/dataset/img10.jpg,Yes,0.3425,0.5729,0.8276,0.1708,6.8133,0.5845,0.0956,0.4374,0.1552,52.8909,0.5571
+deepface/tests/dataset/img7.jpg,deepface/tests/dataset/img11.jpg,Yes,0.2912,0.5417,0.7632,0.2449,8.3025,0.6998,0.148,0.544,0.1894,60.469,0.6154
+deepface/tests/dataset/img10.jpg,deepface/tests/dataset/img11.jpg,Yes,0.2535,0.5258,0.712,0.1371,6.2509,0.5237,0.0609,0.349,0.1851,60.8244,0.6085
+deepface/tests/dataset/img18.jpg,deepface/tests/dataset/img19.jpg,Yes,0.1043,0.3254,0.4567,0.1248,6.2382,0.4996,0.2563,0.7159,0.1712,60.1675,0.5851
+deepface/tests/dataset/img18.jpg,deepface/tests/dataset/img67.jpg,Yes,0.2197,0.4691,0.6629,0.2387,8.7124,0.6909,0.3072,0.7838,0.1839,58.9528,0.6065
+deepface/tests/dataset/img19.jpg,deepface/tests/dataset/img67.jpg,Yes,0.1466,0.3965,0.5416,0.1321,6.5557,0.514,0.1504,0.5485,0.1517,55.8044,0.5508
+deepface/tests/dataset/img20.jpg,deepface/tests/dataset/img21.jpg,Yes,0.0641,0.2068,0.3581,0.1052,5.4253,0.4586,0.1118,0.4729,0.2209,58.7235,0.6646
+deepface/tests/dataset/img34.jpg,deepface/tests/dataset/img35.jpg,Yes,0.0959,0.2628,0.4381,0.2538,8.7003,0.7124,0.3727,0.8634,0.3244,78.4397,0.8055
+deepface/tests/dataset/img34.jpg,deepface/tests/dataset/img36.jpg,Yes,0.1553,0.2918,0.5573,0.1861,7.5793,0.6101,0.399,0.8933,0.2923,61.625,0.7646
+deepface/tests/dataset/img34.jpg,deepface/tests/dataset/img37.jpg,Yes,0.104,0.2651,0.4562,0.1192,6.0818,0.4882,0.4158,0.912,0.2853,62.1217,0.7554
+deepface/tests/dataset/img35.jpg,deepface/tests/dataset/img36.jpg,Yes,0.2322,0.3945,0.6814,0.2049,7.6366,0.6401,0.38,0.8717,0.2991,74.4219,0.7735
+deepface/tests/dataset/img35.jpg,deepface/tests/dataset/img37.jpg,Yes,0.1684,0.3516,0.5804,0.186,7.2991,0.6099,0.1662,0.5766,0.164,58.1125,0.5727
+deepface/tests/dataset/img36.jpg,deepface/tests/dataset/img37.jpg,Yes,0.1084,0.2715,0.4655,0.1338,6.3075,0.5173,0.2909,0.7627,0.2687,54.7311,0.7331
+deepface/tests/dataset/img22.jpg,deepface/tests/dataset/img23.jpg,Yes,0.3637,0.4569,0.8528,0.3501,9.9752,0.8368,0.1651,0.5746,0.1649,42.2178,0.5742
+deepface/tests/dataset/img13.jpg,deepface/tests/dataset/img14.jpg,Yes,0.086,0.3384,0.4148,0.1104,5.3711,0.47,0.0952,0.4363,0.2043,61.8532,0.6392
+deepface/tests/dataset/img13.jpg,deepface/tests/dataset/img15.jpg,Yes,0.1879,0.5589,0.6131,0.2317,7.9283,0.6808,0.3202,0.8003,0.3665,81.975,0.8562
+deepface/tests/dataset/img13.jpg,deepface/tests/dataset/img57.jpg,Yes,0.1204,0.3952,0.4907,0.1897,7.1445,0.616,0.4599,0.9591,0.3266,82.6217,0.8082
+deepface/tests/dataset/img13.jpg,deepface/tests/dataset/img58.jpg,Yes,0.1748,0.524,0.5913,0.2264,7.7484,0.6729,0.5006,1.0006,0.3476,75.6494,0.8338
+deepface/tests/dataset/img14.jpg,deepface/tests/dataset/img15.jpg,Yes,0.1969,0.571,0.6275,0.2322,7.8197,0.6815,0.3409,0.8257,0.4076,89.3521,0.9029
+deepface/tests/dataset/img14.jpg,deepface/tests/dataset/img57.jpg,Yes,0.1815,0.4206,0.6025,0.128,5.7838,0.5059,0.4251,0.9221,0.3284,84.7328,0.8105
+deepface/tests/dataset/img14.jpg,deepface/tests/dataset/img58.jpg,Yes,0.2071,0.5609,0.6436,0.2125,7.384,0.6519,0.4993,0.9993,0.3848,83.0627,0.8772
+deepface/tests/dataset/img15.jpg,deepface/tests/dataset/img57.jpg,Yes,0.198,0.5753,0.6293,0.2073,7.5025,0.6439,0.3957,0.8896,0.3881,91.551,0.881
+deepface/tests/dataset/img15.jpg,deepface/tests/dataset/img58.jpg,Yes,0.1109,0.4424,0.4709,0.1106,5.4445,0.4702,0.2815,0.7503,0.4153,85.5012,0.9114
+deepface/tests/dataset/img57.jpg,deepface/tests/dataset/img58.jpg,Yes,0.1581,0.5045,0.5624,0.1452,6.2094,0.5389,0.213,0.6528,0.2184,67.7741,0.6609
+deepface/tests/dataset/img29.jpg,deepface/tests/dataset/img30.jpg,Yes,0.142,0.28,0.5329,0.1759,7.1649,0.5931,0.3237,0.8046,0.272,59.7856,0.7375
+deepface/tests/dataset/img29.jpg,deepface/tests/dataset/img31.jpg,Yes,0.1525,0.2777,0.5523,0.1588,6.8613,0.5636,0.5027,1.0027,0.2,49.2171,0.6324
+deepface/tests/dataset/img29.jpg,deepface/tests/dataset/img32.jpg,Yes,0.1807,0.481,0.6011,0.1997,7.8571,0.632,0.4602,0.9594,0.3084,60.7837,0.7854
+deepface/tests/dataset/img29.jpg,deepface/tests/dataset/img33.jpg,Yes,0.1757,0.3177,0.5927,0.2406,8.3798,0.6937,0.3446,0.8302,0.1679,47.9061,0.5795
+deepface/tests/dataset/img30.jpg,deepface/tests/dataset/img31.jpg,Yes,0.1141,0.2453,0.4776,0.1654,6.8805,0.5751,0.3189,0.7986,0.1897,51.344,0.6159
+deepface/tests/dataset/img30.jpg,deepface/tests/dataset/img32.jpg,Yes,0.1567,0.4575,0.5597,0.1757,7.2731,0.5929,0.1712,0.5851,0.242,57.849,0.6957
+deepface/tests/dataset/img30.jpg,deepface/tests/dataset/img33.jpg,Yes,0.1548,0.2997,0.5565,0.2074,7.6356,0.644,0.1744,0.5906,0.2601,61.9643,0.7213
+deepface/tests/dataset/img31.jpg,deepface/tests/dataset/img32.jpg,Yes,0.1402,0.4725,0.5295,0.1009,5.5583,0.4493,0.2098,0.6478,0.2023,51.0814,0.6361
+deepface/tests/dataset/img31.jpg,deepface/tests/dataset/img33.jpg,Yes,0.0895,0.2296,0.4232,0.1873,7.3261,0.6121,0.1871,0.6118,0.229,56.6939,0.6768
+deepface/tests/dataset/img32.jpg,deepface/tests/dataset/img33.jpg,Yes,0.2035,0.4953,0.638,0.2415,8.5176,0.6949,0.2426,0.6965,0.2768,62.1742,0.744
+deepface/tests/dataset/img8.jpg,deepface/tests/dataset/img9.jpg,Yes,0.3147,0.45,0.7933,0.1976,7.3714,0.6287,0.0997,0.4466,0.1695,48.8942,0.5822
+deepface/tests/dataset/img8.jpg,deepface/tests/dataset/img47.jpg,Yes,0.3638,0.4564,0.853,0.1976,7.2952,0.6287,0.0931,0.4314,0.1869,54.8324,0.6114
+deepface/tests/dataset/img8.jpg,deepface/tests/dataset/img48.jpg,Yes,0.3068,0.442,0.7834,0.2593,8.2334,0.7201,0.1319,0.5136,0.2194,55.6994,0.6624
+deepface/tests/dataset/img8.jpg,deepface/tests/dataset/img49.jpg,Yes,0.2353,0.4246,0.686,0.1797,6.8592,0.5996,0.1472,0.5426,0.1904,57.1813,0.617
+deepface/tests/dataset/img8.jpg,deepface/tests/dataset/img50.jpg,Yes,0.3583,0.5144,0.8465,0.24,8.2435,0.6928,0.132,0.5138,0.138,40.4616,0.5253
+deepface/tests/dataset/img8.jpg,deepface/tests/dataset/img51.jpg,Yes,0.3446,0.4498,0.8301,0.1666,6.7177,0.5772,0.1413,0.5317,0.1656,46.6621,0.5756
+deepface/tests/dataset/img9.jpg,deepface/tests/dataset/img47.jpg,Yes,0.3153,0.4374,0.7941,0.1772,6.9625,0.5953,0.1591,0.5641,0.1795,54.801,0.5992
+deepface/tests/dataset/img9.jpg,deepface/tests/dataset/img48.jpg,Yes,0.3537,0.4845,0.8411,0.1723,6.7796,0.5871,0.1234,0.4969,0.1795,52.6507,0.5992
+deepface/tests/dataset/img9.jpg,deepface/tests/dataset/img49.jpg,Yes,0.2072,0.4029,0.6437,0.1954,7.2154,0.6251,0.1529,0.553,0.1311,48.2847,0.5121
+deepface/tests/dataset/img9.jpg,deepface/tests/dataset/img50.jpg,Yes,0.2662,0.4509,0.7296,0.2576,8.5935,0.7177,0.1531,0.5533,0.1205,41.6412,0.491
+deepface/tests/dataset/img9.jpg,deepface/tests/dataset/img51.jpg,Yes,0.3282,0.4507,0.8102,0.2371,8.0755,0.6887,0.1873,0.612,0.1817,51.7388,0.6029
+deepface/tests/dataset/img47.jpg,deepface/tests/dataset/img48.jpg,Yes,0.345,0.4542,0.8307,0.1613,6.4777,0.5679,0.1419,0.5328,0.1649,52.6864,0.5742
+deepface/tests/dataset/img47.jpg,deepface/tests/dataset/img49.jpg,Yes,0.257,0.4382,0.717,0.1944,7.1101,0.6236,0.1089,0.4667,0.2415,66.6307,0.695
+deepface/tests/dataset/img47.jpg,deepface/tests/dataset/img50.jpg,Yes,0.1844,0.3737,0.6073,0.215,7.7872,0.6558,0.1817,0.6029,0.2052,57.2133,0.6406
+deepface/tests/dataset/img47.jpg,deepface/tests/dataset/img51.jpg,Yes,0.1979,0.3274,0.6291,0.1303,5.926,0.5106,0.0939,0.4334,0.1209,44.911,0.4918
+deepface/tests/dataset/img48.jpg,deepface/tests/dataset/img49.jpg,Yes,0.2917,0.4744,0.7639,0.232,7.6321,0.6812,0.1067,0.462,0.2183,61.9241,0.6608
+deepface/tests/dataset/img48.jpg,deepface/tests/dataset/img50.jpg,Yes,0.3985,0.5478,0.8927,0.2745,8.6847,0.7409,0.2245,0.6701,0.2181,55.6337,0.6605
+deepface/tests/dataset/img48.jpg,deepface/tests/dataset/img51.jpg,Yes,0.3408,0.4563,0.8255,0.1586,6.4477,0.5633,0.1734,0.5888,0.2082,55.6445,0.6452
+deepface/tests/dataset/img49.jpg,deepface/tests/dataset/img50.jpg,Yes,0.2073,0.4183,0.6439,0.2437,8.1889,0.6982,0.1738,0.5896,0.1949,57.7545,0.6243
+deepface/tests/dataset/img49.jpg,deepface/tests/dataset/img51.jpg,Yes,0.2694,0.4491,0.7341,0.2076,7.3716,0.6444,0.1414,0.5318,0.2283,62.518,0.6758
+deepface/tests/dataset/img50.jpg,deepface/tests/dataset/img51.jpg,Yes,0.2505,0.4295,0.7079,0.2299,8.07,0.6781,0.1894,0.6155,0.1715,47.5665,0.5857
+deepface/tests/dataset/img16.jpg,deepface/tests/dataset/img17.jpg,Yes,0.2545,0.3759,0.7135,0.1493,6.5661,0.5465,0.2749,0.7414,0.1528,47.8128,0.5528
+deepface/tests/dataset/img16.jpg,deepface/tests/dataset/img59.jpg,Yes,0.1796,0.4352,0.5993,0.3095,9.6361,0.7868,0.4173,0.9136,0.247,61.4867,0.7028
+deepface/tests/dataset/img16.jpg,deepface/tests/dataset/img61.jpg,Yes,0.1779,0.3234,0.5965,0.1863,7.2985,0.6105,0.1407,0.5305,0.1643,53.2032,0.5732
+deepface/tests/dataset/img16.jpg,deepface/tests/dataset/img62.jpg,Yes,0.106,0.2509,0.4604,0.2243,8.1191,0.6698,0.3857,0.8783,0.1953,57.434,0.6249
+deepface/tests/dataset/img17.jpg,deepface/tests/dataset/img59.jpg,Yes,0.2519,0.5106,0.7099,0.2846,9.3099,0.7544,0.3877,0.8806,0.2994,62.5416,0.7739
+deepface/tests/dataset/img17.jpg,deepface/tests/dataset/img61.jpg,Yes,0.2507,0.3495,0.708,0.1992,7.6132,0.6313,0.1867,0.6111,0.2101,58.2095,0.6482
+deepface/tests/dataset/img17.jpg,deepface/tests/dataset/img62.jpg,Yes,0.2533,0.3415,0.7118,0.2672,8.9292,0.731,0.3356,0.8193,0.252,62.3621,0.7099
+deepface/tests/dataset/img59.jpg,deepface/tests/dataset/img61.jpg,Yes,0.192,0.4543,0.6196,0.4417,11.5466,0.9399,0.3558,0.8435,0.1808,54.8373,0.6014
+deepface/tests/dataset/img59.jpg,deepface/tests/dataset/img62.jpg,Yes,0.1123,0.3893,0.4738,0.2974,9.5874,0.7713,0.5393,1.0386,0.1934,55.9836,0.6219
+deepface/tests/dataset/img61.jpg,deepface/tests/dataset/img62.jpg,Yes,0.1251,0.253,0.5002,0.2245,8.1525,0.6701,0.4072,0.9024,0.1757,55.867,0.5928
+deepface/tests/dataset/img26.jpg,deepface/tests/dataset/img27.jpg,Yes,0.3059,0.5758,0.7822,0.3444,9.7537,0.8299,0.1815,0.6026,0.2396,69.4496,0.6922
+deepface/tests/dataset/img26.jpg,deepface/tests/dataset/img28.jpg,Yes,0.343,0.5503,0.8282,0.3556,10.2896,0.8433,0.1662,0.5766,0.205,60.0105,0.6403
+deepface/tests/dataset/img26.jpg,deepface/tests/dataset/img42.jpg,Yes,0.3852,0.542,0.8778,0.3278,9.7855,0.8097,0.2831,0.7524,0.2523,66.2702,0.7104
+deepface/tests/dataset/img26.jpg,deepface/tests/dataset/img43.jpg,Yes,0.3254,0.5271,0.8067,0.2825,8.887,0.7517,0.2876,0.7585,0.3443,79.1342,0.8299
+deepface/tests/dataset/img26.jpg,deepface/tests/dataset/img44.jpg,Yes,0.3645,0.5029,0.8539,0.2248,7.9975,0.6706,0.2646,0.7274,0.2572,68.2216,0.7173
+deepface/tests/dataset/img26.jpg,deepface/tests/dataset/img45.jpg,Yes,0.283,0.4775,0.7523,0.2537,8.5109,0.7124,0.3277,0.8096,0.2726,70.5843,0.7384
+deepface/tests/dataset/img26.jpg,deepface/tests/dataset/img46.jpg,Yes,0.447,0.5967,0.9456,0.4372,11.0907,0.9351,0.3544,0.8419,0.3079,73.7249,0.7848
+deepface/tests/dataset/img27.jpg,deepface/tests/dataset/img28.jpg,Yes,0.2847,0.5707,0.7546,0.2178,7.8688,0.6601,0.1205,0.491,0.232,66.1474,0.6811
+deepface/tests/dataset/img27.jpg,deepface/tests/dataset/img42.jpg,Yes,0.328,0.5946,0.8099,0.2829,8.8485,0.7523,0.3721,0.8627,0.2376,66.8304,0.6893
+deepface/tests/dataset/img27.jpg,deepface/tests/dataset/img43.jpg,Yes,0.3781,0.65,0.8696,0.2827,8.6093,0.7519,0.2004,0.633,0.2924,75.1537,0.7647
+deepface/tests/dataset/img27.jpg,deepface/tests/dataset/img44.jpg,Yes,0.3385,0.5968,0.8229,0.2597,8.3408,0.7207,0.2941,0.7669,0.2314,66.8603,0.6803
+deepface/tests/dataset/img27.jpg,deepface/tests/dataset/img45.jpg,Yes,0.2302,0.5087,0.6785,0.147,6.2958,0.5422,0.2088,0.6463,0.2035,63.0117,0.6379
+deepface/tests/dataset/img27.jpg,deepface/tests/dataset/img46.jpg,Yes,0.3461,0.6141,0.832,0.388,10.1318,0.881,0.264,0.7266,0.2241,65.3424,0.6694
+deepface/tests/dataset/img28.jpg,deepface/tests/dataset/img42.jpg,Yes,0.2442,0.4668,0.6988,0.1991,7.7026,0.631,0.2848,0.7547,0.2583,62.2885,0.7187
+deepface/tests/dataset/img28.jpg,deepface/tests/dataset/img43.jpg,Yes,0.2159,0.4542,0.657,0.2239,8.0122,0.6692,0.2194,0.6624,0.2833,67.7766,0.7527
+deepface/tests/dataset/img28.jpg,deepface/tests/dataset/img44.jpg,Yes,0.2802,0.4883,0.7486,0.1697,7.0317,0.5826,0.2753,0.742,0.2378,61.8227,0.6897
+deepface/tests/dataset/img28.jpg,deepface/tests/dataset/img45.jpg,Yes,0.3044,0.5286,0.7803,0.1768,7.1867,0.5946,0.267,0.7307,0.2683,66.1764,0.7326
+deepface/tests/dataset/img28.jpg,deepface/tests/dataset/img46.jpg,Yes,0.426,0.6222,0.923,0.3338,9.8004,0.817,0.2481,0.7044,0.3072,68.9752,0.7838
+deepface/tests/dataset/img42.jpg,deepface/tests/dataset/img43.jpg,Yes,0.2018,0.4174,0.6353,0.2418,8.227,0.6954,0.1678,0.5794,0.1483,49.1175,0.5446
+deepface/tests/dataset/img42.jpg,deepface/tests/dataset/img44.jpg,Yes,0.1685,0.3458,0.5805,0.119,5.8252,0.4879,0.2432,0.6975,0.0957,39.352,0.4375
+deepface/tests/dataset/img42.jpg,deepface/tests/dataset/img45.jpg,Yes,0.2004,0.4027,0.6331,0.1378,6.2772,0.5251,0.1982,0.6296,0.1742,53.3531,0.5903
+deepface/tests/dataset/img42.jpg,deepface/tests/dataset/img46.jpg,Yes,0.2253,0.4245,0.6713,0.1946,7.4093,0.6239,0.1761,0.5934,0.1568,49.1856,0.5601
+deepface/tests/dataset/img43.jpg,deepface/tests/dataset/img44.jpg,Yes,0.2049,0.4137,0.6402,0.2238,7.7899,0.6691,0.1748,0.5912,0.1553,51.4113,0.5573
+deepface/tests/dataset/img43.jpg,deepface/tests/dataset/img45.jpg,Yes,0.2298,0.4524,0.6779,0.2281,7.8811,0.6754,0.0531,0.3257,0.1801,55.7173,0.6001
+deepface/tests/dataset/img43.jpg,deepface/tests/dataset/img46.jpg,Yes,0.3731,0.5738,0.8638,0.3741,10.0121,0.865,0.1394,0.5281,0.2184,60.1165,0.6609
+deepface/tests/dataset/img44.jpg,deepface/tests/dataset/img45.jpg,Yes,0.1743,0.3671,0.5903,0.1052,5.4022,0.4587,0.1636,0.572,0.1275,46.7067,0.505
+deepface/tests/dataset/img44.jpg,deepface/tests/dataset/img46.jpg,Yes,0.2682,0.4468,0.7324,0.2225,7.7975,0.667,0.1984,0.6299,0.1569,50.7309,0.5602
+deepface/tests/dataset/img45.jpg,deepface/tests/dataset/img46.jpg,Yes,0.2818,0.486,0.7507,0.2239,7.8397,0.6692,0.1379,0.5252,0.193,56.6925,0.6213
+deepface/tests/dataset/img24.jpg,deepface/tests/dataset/img25.jpg,Yes,0.1197,0.2833,0.4893,0.1419,6.4307,0.5327,0.1666,0.5773,0.2083,60.7717,0.6454
+deepface/tests/dataset/img21.jpg,deepface/tests/dataset/img17.jpg,No,0.4907,0.531,0.9907,0.6285,13.4397,1.1212,0.807,1.2704,0.3363,67.5896,0.8201
+deepface/tests/dataset/img23.jpg,deepface/tests/dataset/img47.jpg,No,0.5671,0.563,1.065,0.6961,13.8325,1.1799,0.1334,0.5166,0.2008,56.6182,0.6337
+deepface/tests/dataset/img16.jpg,deepface/tests/dataset/img24.jpg,No,0.6046,0.5757,1.0997,0.9105,16.3487,1.3494,0.2078,0.6447,0.2218,57.4046,0.666
+deepface/tests/dataset/img50.jpg,deepface/tests/dataset/img16.jpg,No,0.7308,0.7317,1.2089,1.0868,17.7134,1.4743,0.3578,0.846,0.2254,57.4293,0.6715
+deepface/tests/dataset/img41.jpg,deepface/tests/dataset/img18.jpg,No,0.4197,0.569,0.9162,0.8173,13.1177,1.2786,0.6457,1.1364,0.3401,75.8425,0.8247
+deepface/tests/dataset/img12.jpg,deepface/tests/dataset/img32.jpg,No,0.7555,0.9708,1.2293,1.0896,18.6004,1.4762,0.4448,0.9432,0.2547,60.7653,0.7138
+deepface/tests/dataset/img51.jpg,deepface/tests/dataset/img26.jpg,No,0.506,0.5807,1.006,0.7329,14.3648,1.2107,0.2928,0.7652,0.2226,61.9764,0.6672
+deepface/tests/dataset/img13.jpg,deepface/tests/dataset/img27.jpg,No,0.688,0.9511,1.1731,0.9559,15.8763,1.3827,0.3366,0.8205,0.2086,63.7428,0.6459
+deepface/tests/dataset/img35.jpg,deepface/tests/dataset/img33.jpg,No,0.2131,0.3838,0.6528,0.5762,12.621,1.0735,0.3323,0.8153,0.2895,74.4074,0.7609
+deepface/tests/dataset/img34.jpg,deepface/tests/dataset/img44.jpg,No,0.7964,0.6879,1.262,0.9531,16.8504,1.3806,0.4968,0.9968,0.2565,63.8992,0.7162
+deepface/tests/dataset/img8.jpg,deepface/tests/dataset/img61.jpg,No,0.8548,0.6996,1.3075,0.9485,16.2825,1.3773,0.6479,1.1383,0.259,64.0582,0.7198
+deepface/tests/dataset/img53.jpg,deepface/tests/dataset/img4.jpg,No,0.5862,0.6454,1.0828,0.8624,16.0416,1.3133,0.3185,0.7982,0.2397,65.712,0.6924
+deepface/tests/dataset/img54.jpg,deepface/tests/dataset/img2.jpg,No,0.6948,0.9246,1.1788,0.9568,16.4217,1.3833,0.3481,0.8344,0.2497,64.7938,0.7067
+deepface/tests/dataset/img43.jpg,deepface/tests/dataset/img24.jpg,No,0.7757,0.7407,1.2456,1.0007,16.8769,1.4147,0.4194,0.9159,0.3961,77.6798,0.8901
+deepface/tests/dataset/img6.jpg,deepface/tests/dataset/img20.jpg,No,0.6784,0.7154,1.1648,0.9864,16.5342,1.4045,0.2043,0.6392,0.2499,67.3658,0.707
+deepface/tests/dataset/img40.jpg,deepface/tests/dataset/img20.jpg,No,0.474,0.4904,0.9736,0.7949,14.8341,1.2609,0.4776,0.9773,0.2192,56.6904,0.6621
+deepface/tests/dataset/img29.jpg,deepface/tests/dataset/img49.jpg,No,0.725,0.7156,1.2041,1.2676,18.7008,1.5922,0.3254,0.8068,0.1968,58.1537,0.6274
+deepface/tests/dataset/img38.jpg,deepface/tests/dataset/img29.jpg,No,0.5496,0.5428,1.0484,1.1766,18.8394,1.534,0.2956,0.769,0.323,68.2188,0.8037
+deepface/tests/dataset/img7.jpg,deepface/tests/dataset/img20.jpg,No,0.7791,0.7506,1.2482,0.945,16.0728,1.3748,0.2922,0.7645,0.2063,58.285,0.6424
+deepface/tests/dataset/img54.jpg,deepface/tests/dataset/img10.jpg,No,0.6852,0.8904,1.1707,0.9223,16.2459,1.3582,0.3508,0.8377,0.2699,67.3228,0.7347
+deepface/tests/dataset/img17.jpg,deepface/tests/dataset/img43.jpg,No,0.7785,0.7344,1.2478,0.8234,15.1735,1.2833,0.8461,1.3009,0.3715,74.2351,0.862
+deepface/tests/dataset/img56.jpg,deepface/tests/dataset/img47.jpg,No,0.5798,0.6885,1.0769,0.9515,16.1507,1.3795,0.2527,0.7109,0.1453,51.4537,0.5391
+deepface/tests/dataset/img10.jpg,deepface/tests/dataset/img15.jpg,No,0.7144,1.0202,1.1953,1.1267,17.5833,1.5012,0.7384,1.2152,0.404,87.858,0.8989
+deepface/tests/dataset/img21.jpg,deepface/tests/dataset/img61.jpg,No,0.5642,0.5883,1.0623,0.7305,14.4227,1.2088,0.5523,1.051,0.3206,73.1845,0.8008
+deepface/tests/dataset/img34.jpg,deepface/tests/dataset/img47.jpg,No,0.6442,0.5952,1.1351,1.0884,17.8754,1.4754,0.6225,1.1158,0.2549,64.7586,0.714
+deepface/tests/dataset/img11.jpg,deepface/tests/dataset/img51.jpg,No,0.5459,0.6938,1.0448,0.7452,14.4984,1.2208,0.1807,0.6012,0.179,58.3078,0.5983
+deepface/tests/dataset/img4.jpg,deepface/tests/dataset/img14.jpg,No,0.7235,0.8162,1.2029,1.0599,16.8526,1.4559,0.4242,0.9211,0.26,72.3704,0.7211
+deepface/tests/dataset/img38.jpg,deepface/tests/dataset/img14.jpg,No,0.5044,0.637,1.0044,0.9856,16.5161,1.404,0.2733,0.7393,0.354,80.6472,0.8415
+deepface/tests/dataset/img19.jpg,deepface/tests/dataset/img47.jpg,No,0.5752,0.6917,1.0726,1.0042,17.1669,1.4172,0.354,0.8414,0.1709,59.1711,0.5846
+deepface/tests/dataset/img55.jpg,deepface/tests/dataset/img14.jpg,No,0.6473,0.7275,1.1378,0.9052,15.7543,1.3455,0.2127,0.6523,0.2293,67.2542,0.6771
+deepface/tests/dataset/img20.jpg,deepface/tests/dataset/img33.jpg,No,0.4886,0.541,0.9885,0.9202,16.051,1.3566,0.6114,1.1058,0.253,62.6318,0.7113
+deepface/tests/dataset/img39.jpg,deepface/tests/dataset/img62.jpg,No,0.4634,0.5606,0.9627,0.8783,16.0858,1.3254,0.7776,1.2471,0.329,70.4788,0.8112
+deepface/tests/dataset/img54.jpg,deepface/tests/dataset/img58.jpg,No,0.6048,0.9477,1.0998,0.8084,15.0301,1.2716,0.6403,1.1316,0.3272,69.1393,0.809
+deepface/tests/dataset/img11.jpg,deepface/tests/dataset/img9.jpg,No,0.6643,0.7784,1.1527,0.899,16.0335,1.3409,0.2452,0.7002,0.1639,56.0631,0.5725
+deepface/tests/dataset/img6.jpg,deepface/tests/dataset/img46.jpg,No,0.5766,0.7054,1.0738,0.9264,15.9036,1.3611,0.1341,0.5179,0.2298,64.5324,0.6779
+deepface/tests/dataset/img7.jpg,deepface/tests/dataset/img59.jpg,No,0.7679,0.8729,1.2393,1.0242,17.2778,1.4312,0.7789,1.2481,0.3103,69.694,0.7878
+deepface/tests/dataset/img7.jpg,deepface/tests/dataset/img35.jpg,No,0.8227,0.8096,1.2827,1.0357,16.7157,1.4392,0.4864,0.9863,0.2401,68.9468,0.693
+deepface/tests/dataset/img5.jpg,deepface/tests/dataset/img19.jpg,No,0.7052,0.752,1.1876,0.9084,16.1781,1.3479,0.2462,0.7016,0.1449,58.8831,0.5384
+deepface/tests/dataset/img55.jpg,deepface/tests/dataset/img8.jpg,No,0.4891,0.5451,0.989,0.7908,14.9832,1.2576,0.2408,0.6939,0.2341,63.666,0.6843
+deepface/tests/dataset/img22.jpg,deepface/tests/dataset/img51.jpg,No,0.5201,0.5378,1.0199,0.6262,13.2133,1.1191,0.1456,0.5397,0.2985,60.8239,0.7726
+deepface/tests/dataset/img4.jpg,deepface/tests/dataset/img15.jpg,No,0.7147,0.9872,1.1956,1.0641,17.2349,1.4588,0.6229,1.1162,0.4049,89.7221,0.8998
+deepface/tests/dataset/img19.jpg,deepface/tests/dataset/img29.jpg,No,0.3605,0.5646,0.8492,0.6901,14.6314,1.1748,0.1803,0.6005,0.2709,71.9655,0.7361
+deepface/tests/dataset/img20.jpg,deepface/tests/dataset/img28.jpg,No,0.5807,0.6843,1.0777,0.8133,15.3844,1.2754,0.1274,0.5048,0.1841,53.6094,0.6067
+deepface/tests/dataset/img55.jpg,deepface/tests/dataset/img13.jpg,No,0.6366,0.8086,1.1283,0.8832,15.8044,1.3291,0.3343,0.8177,0.177,57.373,0.5949
+deepface/tests/dataset/img34.jpg,deepface/tests/dataset/img22.jpg,No,0.7842,0.6655,1.2523,1.137,18.5595,1.508,0.4797,0.9795,0.2457,56.695,0.7011
+deepface/tests/dataset/img67.jpg,deepface/tests/dataset/img58.jpg,No,0.5051,0.8463,1.0051,0.8713,16.0723,1.3201,0.5281,1.0277,0.276,67.6933,0.743
+deepface/tests/dataset/img18.jpg,deepface/tests/dataset/img9.jpg,No,0.7493,0.7683,1.2242,1.0774,17.7057,1.4679,0.5343,1.0337,0.2113,62.0197,0.65
+deepface/tests/dataset/img11.jpg,deepface/tests/dataset/img58.jpg,No,0.7495,1.0309,1.2243,1.0359,16.9461,1.4394,0.6411,1.1324,0.2259,65.3131,0.6721
+deepface/tests/dataset/img18.jpg,deepface/tests/dataset/img42.jpg,No,0.8335,0.8332,1.2911,1.0838,17.9617,1.4723,0.4051,0.9001,0.2449,66.4075,0.6999
+deepface/tests/dataset/img18.jpg,deepface/tests/dataset/img13.jpg,No,0.476,0.7428,0.9757,1.1589,18.2018,1.5224,0.306,0.7823,0.1879,59.4531,0.6129
+deepface/tests/dataset/img4.jpg,deepface/tests/dataset/img32.jpg,No,0.7116,0.8739,1.193,1.0402,17.6777,1.4424,0.6456,1.1363,0.2896,71.6141,0.761
+deepface/tests/dataset/img67.jpg,deepface/tests/dataset/img37.jpg,No,0.4644,0.652,0.9638,0.6683,14.5099,1.1561,0.2355,0.6862,0.2475,61.9234,0.7036
+deepface/tests/dataset/img41.jpg,deepface/tests/dataset/img7.jpg,No,0.8444,0.7812,1.2666,0.9357,16.3278,1.368,0.4702,1.459,0.4919,67.9214,0.7892
+deepface/tests/dataset/img11.jpg,deepface/tests/dataset/img27.jpg,No,0.6496,0.8811,1.1398,0.9364,16.0727,1.3685,0.2416,0.6951,0.2127,66.7336,0.6523
+deepface/tests/dataset/img20.jpg,deepface/tests/dataset/img47.jpg,No,0.6418,0.6011,1.1329,1.0579,16.9991,1.4546,0.31,0.7874,0.1754,54.6104,0.5924
+deepface/tests/dataset/img2.jpg,deepface/tests/dataset/img44.jpg,No,0.4815,0.6806,0.9814,0.7396,14.1679,1.2162,0.2009,0.6338,0.1836,57.4368,0.606
+deepface/tests/dataset/img28.jpg,deepface/tests/dataset/img24.jpg,No,0.7851,0.7588,1.2531,0.9406,16.8964,1.3715,0.5353,1.0347,0.2609,60.6589,0.7224
+deepface/tests/dataset/img67.jpg,deepface/tests/dataset/img43.jpg,No,0.691,0.8328,1.1756,0.9621,16.9417,1.3872,0.3176,0.797,0.3072,72.9213,0.7838
+deepface/tests/dataset/img18.jpg,deepface/tests/dataset/img51.jpg,No,0.668,0.7024,1.1558,1.1051,17.8105,1.4867,0.2508,0.7083,0.1882,58.3932,0.6135
+deepface/tests/dataset/img11.jpg,deepface/tests/dataset/img24.jpg,No,0.79,0.801,1.257,1.1173,18.2579,1.4949,0.3437,0.829,0.3096,74.5014,0.7869
+deepface/tests/dataset/img67.jpg,deepface/tests/dataset/img29.jpg,No,0.5389,0.6762,1.0382,0.8354,16.2507,1.2926,0.1501,0.5479,0.2668,63.7773,0.7305
+deepface/tests/dataset/img29.jpg,deepface/tests/dataset/img59.jpg,No,0.4237,0.6225,0.9205,0.5002,12.4131,1.0002,0.6375,1.1292,0.2637,58.2849,0.7262
+deepface/tests/dataset/img41.jpg,deepface/tests/dataset/img24.jpg,No,0.5431,0.5391,1.0422,1.1194,18.4041,1.4962,0.8286,1.2873,0.4458,74.1332,0.9442
+deepface/tests/dataset/img35.jpg,deepface/tests/dataset/img27.jpg,No,0.821,0.9129,1.2814,0.964,15.9831,1.3885,0.4812,0.9811,0.3061,80.9221,0.7824
+deepface/tests/dataset/img39.jpg,deepface/tests/dataset/img67.jpg,No,0.5513,0.7255,1.0501,0.9839,17.4219,1.4028,0.8181,1.2792,0.2914,66.5717,0.7634
+deepface/tests/dataset/img39.jpg,deepface/tests/dataset/img12.jpg,No,0.6435,0.8102,1.1344,0.7661,15.2245,1.2378,0.7472,1.2224,0.2716,61.7006,0.737
+deepface/tests/dataset/img41.jpg,deepface/tests/dataset/img46.jpg,No,0.8116,0.7634,1.2028,1.1264,17.9427,1.5009,0.9219,1.3578,0.3511,70.3501,0.838
+deepface/tests/dataset/img32.jpg,deepface/tests/dataset/img27.jpg,No,0.7197,0.9593,1.1997,0.7295,14.4944,1.2079,0.5619,1.0601,0.2725,70.5338,0.7382
+deepface/tests/dataset/img40.jpg,deepface/tests/dataset/img11.jpg,No,0.7205,0.7563,1.2004,0.9367,16.3131,1.3687,0.5427,1.0418,0.186,59.4748,0.61
+deepface/tests/dataset/img41.jpg,deepface/tests/dataset/img22.jpg,No,0.5579,0.6466,1.2024,1.0076,17.2122,1.4196,0.7998,1.2648,0.392,65.4579,0.8854
+deepface/tests/dataset/img2.jpg,deepface/tests/dataset/img35.jpg,No,0.8303,0.9037,1.2887,1.0988,17.1897,1.4824,0.498,0.998,0.2992,78.1653,0.7736
+deepface/tests/dataset/img5.jpg,deepface/tests/dataset/img45.jpg,No,0.5247,0.6013,1.0244,0.8827,15.3713,1.3287,0.218,0.6603,0.2322,72.2019,0.6814
+deepface/tests/dataset/img58.jpg,deepface/tests/dataset/img59.jpg,No,0.5937,0.9226,1.0896,0.9931,16.9142,1.4093,0.3525,0.8396,0.3095,68.0277,0.7868
+deepface/tests/dataset/img40.jpg,deepface/tests/dataset/img45.jpg,No,0.772,0.6976,1.2426,1.0516,17.0626,1.4503,0.5487,1.0475,0.2628,63.7285,0.725
+deepface/tests/dataset/img41.jpg,deepface/tests/dataset/img3.jpg,No,0.6417,0.6822,1.1329,0.832,15.8921,1.29,1.0374,1.4404,0.2312,54.5718,0.68
+deepface/tests/dataset/img40.jpg,deepface/tests/dataset/img67.jpg,No,0.4138,0.5942,0.9098,0.948,16.9509,1.3769,0.5121,1.012,0.2455,61.9071,0.7008
+deepface/tests/dataset/img4.jpg,deepface/tests/dataset/img50.jpg,No,0.5776,0.6934,1.0748,0.816,15.3649,1.2775,0.3515,0.8385,0.2072,61.657,0.6437
+deepface/tests/dataset/img67.jpg,deepface/tests/dataset/img47.jpg,No,0.5726,0.692,1.0701,0.9987,17.2907,1.4133,0.4099,0.9054,0.1723,55.0701,0.587
+deepface/tests/dataset/img55.jpg,deepface/tests/dataset/img20.jpg,No,0.684,0.6408,1.1696,0.924,16.3035,1.3594,0.2156,0.6566,0.2111,61.919,0.6498
+deepface/tests/dataset/img13.jpg,deepface/tests/dataset/img33.jpg,No,0.4625,0.7042,0.9617,0.8709,15.4791,1.3198,0.5609,1.0591,0.3643,76.6864,0.8536
+deepface/tests/dataset/img41.jpg,deepface/tests/dataset/img58.jpg,No,0.5732,0.8464,1.0707,0.7511,16.6216,1.4011,0.5091,1.009,0.3653,71.3439,0.8548
+deepface/tests/dataset/img19.jpg,deepface/tests/dataset/img48.jpg,No,0.8186,0.8431,1.2795,1.1082,17.769,1.4888,0.3914,0.8848,0.2363,68.307,0.6875
+deepface/tests/dataset/img18.jpg,deepface/tests/dataset/img49.jpg,No,0.6614,0.7617,1.1501,0.9935,16.5922,1.4096,0.427,0.9241,0.28,73.8384,0.7483
+deepface/tests/dataset/img10.jpg,deepface/tests/dataset/img19.jpg,No,0.603,0.7998,1.0982,0.9508,16.8085,1.379,0.3546,0.8422,0.2352,69.7597,0.6859
+deepface/tests/dataset/img48.jpg,deepface/tests/dataset/img17.jpg,No,0.8174,0.6679,1.2786,0.922,15.8462,1.3579,0.7438,1.2196,0.2545,59.7077,0.7134
+deepface/tests/dataset/img55.jpg,deepface/tests/dataset/img2.jpg,No,0.6454,0.7751,1.1362,1.0674,17.3381,1.4611,0.1279,0.5058,0.1983,61.7554,0.6298
+deepface/tests/dataset/img41.jpg,deepface/tests/dataset/img48.jpg,No,0.7325,0.7072,1.2605,0.8198,15.0575,1.2805,0.9352,1.3676,0.3504,69.8577,0.8371
+deepface/tests/dataset/img30.jpg,deepface/tests/dataset/img44.jpg,No,0.8834,0.7196,1.3292,0.8683,15.5513,1.3178,0.563,1.0611,0.363,75.7833,0.8521
+deepface/tests/dataset/img6.jpg,deepface/tests/dataset/img29.jpg,No,0.7666,0.7464,1.2382,1.0057,17.0345,1.4183,0.3434,0.8287,0.2411,64.6435,0.6943
+deepface/tests/dataset/img19.jpg,deepface/tests/dataset/img26.jpg,No,0.6542,0.7763,1.1439,0.9204,16.7702,1.3568,0.2292,0.677,0.262,73.7273,0.7239
+deepface/tests/dataset/img29.jpg,deepface/tests/dataset/img50.jpg,No,0.6879,0.692,1.1729,1.3134,19.7708,1.6207,0.5038,1.0038,0.2577,54.3931,0.7179
+deepface/tests/dataset/img35.jpg,deepface/tests/dataset/img49.jpg,No,0.8339,0.8186,1.2915,1.2099,17.7753,1.5555,0.5957,1.0915,0.3315,82.3474,0.8142
+deepface/tests/dataset/img22.jpg,deepface/tests/dataset/img28.jpg,No,0.6313,0.7037,1.1236,0.8177,15.5314,1.2789,0.2031,0.6373,0.2271,55.2529,0.6739
+deepface/tests/dataset/img21.jpg,deepface/tests/dataset/img16.jpg,No,0.5678,0.6114,1.0657,0.6376,13.417,1.1293,0.4173,0.9136,0.2696,65.0241,0.7343
+deepface/tests/dataset/img21.jpg,deepface/tests/dataset/img9.jpg,No,0.7653,0.7211,1.2372,1.0502,17.1485,1.4493,0.5726,1.0701,0.3059,68.2225,0.7822
+deepface/tests/dataset/img2.jpg,deepface/tests/dataset/img22.jpg,No,0.6866,0.7895,1.1718,1.0005,16.6324,1.4145,0.1955,0.6253,0.3061,69.9331,0.7824
+deepface/tests/dataset/img12.jpg,deepface/tests/dataset/img29.jpg,No,0.78,0.8337,1.249,1.1016,18.4797,1.4843,0.3404,0.8251,0.3293,67.3331,0.8115
+deepface/tests/dataset/img6.jpg,deepface/tests/dataset/img37.jpg,No,0.7532,0.7788,1.2273,1.0976,17.7567,1.4816,0.2647,0.7275,0.331,74.5559,0.8137
+deepface/tests/dataset/img6.jpg,deepface/tests/dataset/img16.jpg,No,0.7516,0.7581,1.226,1.0332,16.9971,1.4375,0.3815,0.8735,0.2859,72.0572,0.7561
+deepface/tests/dataset/img38.jpg,deepface/tests/dataset/img33.jpg,No,0.4588,0.5085,0.958,1.2465,19.0695,1.5789,0.657,1.1463,0.3722,76.6896,0.8628
+deepface/tests/dataset/img35.jpg,deepface/tests/dataset/img32.jpg,No,0.2651,0.5459,0.7282,0.5427,12.6429,1.0418,0.409,0.9045,0.2546,69.5802,0.7136
+deepface/tests/dataset/img54.jpg,deepface/tests/dataset/img48.jpg,No,0.4528,0.678,0.9516,0.8385,15.166,1.295,0.2238,0.669,0.218,56.5099,0.6603
+deepface/tests/dataset/img1.jpg,deepface/tests/dataset/img23.jpg,No,0.5305,0.5523,1.03,0.7766,14.6983,1.2463,0.1967,0.6272,0.2144,53.347,0.6549
+deepface/tests/dataset/img39.jpg,deepface/tests/dataset/img33.jpg,No,0.5132,0.6067,1.0131,1.1197,17.8246,1.4965,0.2379,0.6898,0.2301,55.7862,0.6783
+deepface/tests/dataset/img3.jpg,deepface/tests/dataset/img48.jpg,No,0.4123,0.5581,0.908,0.7879,14.8183,1.2553,0.2125,0.6519,0.2177,56.6639,0.6598
+deepface/tests/dataset/img43.jpg,deepface/tests/dataset/img25.jpg,No,0.7819,0.7991,1.2505,0.9007,15.601,1.3422,0.4363,0.9341,0.3555,81.219,0.8432
+deepface/tests/dataset/img14.jpg,deepface/tests/dataset/img9.jpg,No,0.7257,0.7829,1.2047,0.8679,15.1696,1.3175,0.5752,1.0725,0.2493,67.0315,0.7061
+deepface/tests/dataset/img6.jpg,deepface/tests/dataset/img47.jpg,No,0.5391,0.6276,1.0383,0.7885,14.6406,1.2558,0.1013,0.4501,0.1756,57.5202,0.5926
+deepface/tests/dataset/img18.jpg,deepface/tests/dataset/img28.jpg,No,0.8293,0.8828,1.2878,1.1151,18.3899,1.4934,0.497,0.997,0.2323,64.8263,0.6816
+deepface/tests/dataset/img7.jpg,deepface/tests/dataset/img57.jpg,No,0.7468,0.815,1.2221,1.1241,17.3821,1.4994,0.6916,1.1761,0.2244,68.912,0.6699
+deepface/tests/dataset/img48.jpg,deepface/tests/dataset/img26.jpg,No,0.5877,0.646,1.0842,0.9734,16.2582,1.3953,0.3102,0.7876,0.2059,60.3497,0.6417
+deepface/tests/dataset/img19.jpg,deepface/tests/dataset/img34.jpg,No,0.2957,0.5193,0.7691,0.5281,12.9854,1.0277,0.5987,1.0943,0.2628,71.5029,0.725
+deepface/tests/dataset/img41.jpg,deepface/tests/dataset/img37.jpg,No,0.4337,0.5351,0.9314,0.8568,16.0356,1.309,0.684,1.1696,0.3654,65.8114,0.8548
+deepface/tests/dataset/img1.jpg,deepface/tests/dataset/img32.jpg,No,0.6985,0.8184,1.182,0.9682,16.9113,1.3915,0.5654,1.0634,0.3173,65.953,0.7967
+deepface/tests/dataset/img12.jpg,deepface/tests/dataset/img57.jpg,No,0.6424,0.8305,1.1335,0.8361,15.6851,1.2931,0.5927,1.0888,0.2943,77.8234,0.7672
+deepface/tests/dataset/img55.jpg,deepface/tests/dataset/img5.jpg,No,0.662,0.6012,1.1507,0.9931,16.5792,1.4093,0.137,0.5234,0.2182,70.8567,0.6606
+deepface/tests/dataset/img47.jpg,deepface/tests/dataset/img61.jpg,No,0.6896,0.603,1.1744,0.98,16.5069,1.4,0.5598,1.0581,0.187,57.8252,0.6115
+deepface/tests/dataset/img33.jpg,deepface/tests/dataset/img49.jpg,No,0.8253,0.7753,1.2848,1.0329,16.5833,1.4373,0.6695,1.1572,0.1992,58.9069,0.6313
+deepface/tests/dataset/img54.jpg,deepface/tests/dataset/img1.jpg,No,0.5922,0.7522,1.0883,0.9398,16.3902,1.371,0.2515,0.7092,0.2836,62.9648,0.7532
+deepface/tests/dataset/img29.jpg,deepface/tests/dataset/img25.jpg,No,0.5458,0.5846,1.0448,0.9074,16.167,1.3472,0.622,1.1153,0.2743,68.4542,0.7407
+deepface/tests/dataset/img55.jpg,deepface/tests/dataset/img67.jpg,No,0.6649,0.7541,1.1531,1.1444,18.95,1.5129,0.3094,0.7866,0.2195,63.9684,0.6625
+deepface/tests/dataset/img53.jpg,deepface/tests/dataset/img30.jpg,No,0.9492,0.7325,1.3778,0.9241,16.5521,1.3595,0.5533,1.052,0.2955,62.208,0.7687
+deepface/tests/dataset/img6.jpg,deepface/tests/dataset/img25.jpg,No,0.8285,0.8131,1.2872,0.8051,14.8877,1.2689,0.4267,0.9238,0.3226,79.803,0.8032
+deepface/tests/dataset/img4.jpg,deepface/tests/dataset/img43.jpg,No,0.6285,0.7443,1.1211,0.838,15.1848,1.2946,0.212,0.6511,0.2685,71.4046,0.7329
+deepface/tests/dataset/img39.jpg,deepface/tests/dataset/img27.jpg,No,0.7176,0.8685,1.198,0.8199,14.9449,1.2805,0.8286,1.2873,0.285,71.6832,0.755
+deepface/tests/dataset/img36.jpg,deepface/tests/dataset/img23.jpg,No,0.6223,0.5866,1.1156,1.0693,17.5747,1.4624,0.4266,0.9237,0.32,58.9248,0.7999
+deepface/tests/dataset/img4.jpg,deepface/tests/dataset/img45.jpg,No,0.6021,0.7106,1.0973,0.9407,16.2744,1.3716,0.2162,0.6576,0.2166,64.3341,0.6582
+deepface/tests/dataset/img38.jpg,deepface/tests/dataset/img19.jpg,No,0.356,0.5607,0.8437,0.9843,17.485,1.403,0.1858,0.6097,0.2867,75.4126,0.7572
+deepface/tests/dataset/img55.jpg,deepface/tests/dataset/img17.jpg,No,0.7135,0.6076,1.1946,0.944,16.691,1.374,0.7449,1.2205,0.2951,70.5113,0.7682
+deepface/tests/dataset/img9.jpg,deepface/tests/dataset/img59.jpg,No,0.8449,0.8766,1.2999,1.1333,18.3376,1.5055,0.8844,1.33,0.3088,67.5783,0.7859
+deepface/tests/dataset/img58.jpg,deepface/tests/dataset/img49.jpg,No,0.5999,0.8901,1.0953,0.9147,15.3098,1.3526,0.4925,0.9925,0.2266,63.0835,0.6733
+deepface/tests/dataset/img56.jpg,deepface/tests/dataset/img59.jpg,No,0.7694,0.9166,1.2405,1.0062,17.304,1.4186,0.8703,1.3193,0.2966,70.5446,0.7702
+deepface/tests/dataset/img4.jpg,deepface/tests/dataset/img8.jpg,No,0.5753,0.6478,1.0727,0.842,15.2912,1.2977,0.3808,0.8727,0.1878,59.2,0.6129
+deepface/tests/dataset/img16.jpg,deepface/tests/dataset/img25.jpg,No,0.5927,0.6271,1.0887,0.9862,16.5907,1.4044,0.286,0.7563,0.1702,56.0079,0.5835
+deepface/tests/dataset/img50.jpg,deepface/tests/dataset/img45.jpg,No,0.5692,0.6912,1.067,0.8581,15.6737,1.3101,0.3278,0.8097,0.2383,60.6426,0.6903
+deepface/tests/dataset/img38.jpg,deepface/tests/dataset/img31.jpg,No,0.4739,0.4751,0.9736,1.1148,18.1862,1.4932,0.6661,1.1542,0.331,70.516,0.8136
+deepface/tests/dataset/img13.jpg,deepface/tests/dataset/img51.jpg,No,0.5639,0.7621,1.062,0.8047,14.7361,1.2686,0.4,0.8945,0.2308,60.6072,0.6795
+deepface/tests/dataset/img1.jpg,deepface/tests/dataset/img33.jpg,No,0.7127,0.6418,1.1939,0.9433,16.1933,1.3736,0.6509,1.1409,0.2684,62.7672,0.7326
+deepface/tests/dataset/img53.jpg,deepface/tests/dataset/img16.jpg,No,0.8344,0.7073,1.2918,0.9023,16.3918,1.3433,0.4153,0.9114,0.3045,65.6394,0.7803
+deepface/tests/dataset/img53.jpg,deepface/tests/dataset/img23.jpg,No,0.4644,0.5199,0.9637,0.7267,14.6939,1.2056,0.1784,0.5973,0.2774,55.6833,0.7448
\ No newline at end of file
diff --git a/modules/deepface-master/tests/dataset/img1.jpg b/modules/deepface-master/tests/dataset/img1.jpg
new file mode 100644
index 000000000..7ceab4fcc
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img1.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img10.jpg b/modules/deepface-master/tests/dataset/img10.jpg
new file mode 100644
index 000000000..267d40116
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img10.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img11.jpg b/modules/deepface-master/tests/dataset/img11.jpg
new file mode 100644
index 000000000..0ebe70841
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img11.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img12.jpg b/modules/deepface-master/tests/dataset/img12.jpg
new file mode 100644
index 000000000..e85fac0d4
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img12.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img13.jpg b/modules/deepface-master/tests/dataset/img13.jpg
new file mode 100644
index 000000000..74ed70a1e
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img13.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img14.jpg b/modules/deepface-master/tests/dataset/img14.jpg
new file mode 100644
index 000000000..1f527fb5f
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img14.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img15.jpg b/modules/deepface-master/tests/dataset/img15.jpg
new file mode 100644
index 000000000..c3e85a3bc
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img15.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img16.jpg b/modules/deepface-master/tests/dataset/img16.jpg
new file mode 100644
index 000000000..07748879d
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img16.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img17.jpg b/modules/deepface-master/tests/dataset/img17.jpg
new file mode 100644
index 000000000..7d37ff55f
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img17.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img18.jpg b/modules/deepface-master/tests/dataset/img18.jpg
new file mode 100644
index 000000000..614140776
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img18.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img19.jpg b/modules/deepface-master/tests/dataset/img19.jpg
new file mode 100644
index 000000000..45433dceb
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img19.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img2.jpg b/modules/deepface-master/tests/dataset/img2.jpg
new file mode 100644
index 000000000..05683ea39
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img2.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img20.jpg b/modules/deepface-master/tests/dataset/img20.jpg
new file mode 100644
index 000000000..6e851759f
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img20.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img21.jpg b/modules/deepface-master/tests/dataset/img21.jpg
new file mode 100644
index 000000000..1f90aa46c
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img21.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img22.jpg b/modules/deepface-master/tests/dataset/img22.jpg
new file mode 100644
index 000000000..0d18c94ee
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img22.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img23.jpg b/modules/deepface-master/tests/dataset/img23.jpg
new file mode 100644
index 000000000..c96eb0498
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img23.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img24.jpg b/modules/deepface-master/tests/dataset/img24.jpg
new file mode 100644
index 000000000..d134ed56c
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img24.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img25.jpg b/modules/deepface-master/tests/dataset/img25.jpg
new file mode 100644
index 000000000..d2d867c56
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img25.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img26.jpg b/modules/deepface-master/tests/dataset/img26.jpg
new file mode 100644
index 000000000..cad2093cc
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img26.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img27.jpg b/modules/deepface-master/tests/dataset/img27.jpg
new file mode 100644
index 000000000..b0bc802db
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img27.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img28.jpg b/modules/deepface-master/tests/dataset/img28.jpg
new file mode 100644
index 000000000..a643428a8
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img28.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img29.jpg b/modules/deepface-master/tests/dataset/img29.jpg
new file mode 100644
index 000000000..83839241f
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img29.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img3.jpg b/modules/deepface-master/tests/dataset/img3.jpg
new file mode 100644
index 000000000..08e8dcc66
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img3.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img30.jpg b/modules/deepface-master/tests/dataset/img30.jpg
new file mode 100644
index 000000000..f271132a2
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img30.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img31.jpg b/modules/deepface-master/tests/dataset/img31.jpg
new file mode 100644
index 000000000..342d6fd6b
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img31.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img32.jpg b/modules/deepface-master/tests/dataset/img32.jpg
new file mode 100644
index 000000000..8df9dd735
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img32.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img33.jpg b/modules/deepface-master/tests/dataset/img33.jpg
new file mode 100644
index 000000000..c6412be87
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img33.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img34.jpg b/modules/deepface-master/tests/dataset/img34.jpg
new file mode 100644
index 000000000..47ea3820f
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img34.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img35.jpg b/modules/deepface-master/tests/dataset/img35.jpg
new file mode 100644
index 000000000..b20c97d58
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img35.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img36.jpg b/modules/deepface-master/tests/dataset/img36.jpg
new file mode 100644
index 000000000..0d4ea95bc
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img36.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img37.jpg b/modules/deepface-master/tests/dataset/img37.jpg
new file mode 100644
index 000000000..9026e8c02
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img37.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img38.jpg b/modules/deepface-master/tests/dataset/img38.jpg
new file mode 100644
index 000000000..b9bb7f161
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img38.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img39.jpg b/modules/deepface-master/tests/dataset/img39.jpg
new file mode 100644
index 000000000..751b664b9
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img39.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img4.jpg b/modules/deepface-master/tests/dataset/img4.jpg
new file mode 100644
index 000000000..b767bd09d
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img4.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img40.jpg b/modules/deepface-master/tests/dataset/img40.jpg
new file mode 100644
index 000000000..71ebe3bac
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img40.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img41.jpg b/modules/deepface-master/tests/dataset/img41.jpg
new file mode 100644
index 000000000..cad0827a0
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img41.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img42.jpg b/modules/deepface-master/tests/dataset/img42.jpg
new file mode 100644
index 000000000..1d42636cd
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img42.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img43.jpg b/modules/deepface-master/tests/dataset/img43.jpg
new file mode 100644
index 000000000..5aaedfe32
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img43.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img44.jpg b/modules/deepface-master/tests/dataset/img44.jpg
new file mode 100644
index 000000000..4cc86d5b3
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img44.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img45.jpg b/modules/deepface-master/tests/dataset/img45.jpg
new file mode 100644
index 000000000..2c9da247f
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img45.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img46.jpg b/modules/deepface-master/tests/dataset/img46.jpg
new file mode 100644
index 000000000..5d49cb3ad
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img46.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img47.jpg b/modules/deepface-master/tests/dataset/img47.jpg
new file mode 100644
index 000000000..0cc3179f2
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img47.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img48.jpg b/modules/deepface-master/tests/dataset/img48.jpg
new file mode 100644
index 000000000..d3ae4814e
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img48.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img49.jpg b/modules/deepface-master/tests/dataset/img49.jpg
new file mode 100644
index 000000000..5f6d3c92d
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img49.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img5.jpg b/modules/deepface-master/tests/dataset/img5.jpg
new file mode 100644
index 000000000..29b6a2f44
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img5.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img50.jpg b/modules/deepface-master/tests/dataset/img50.jpg
new file mode 100644
index 000000000..3abe0b02b
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img50.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img51.jpg b/modules/deepface-master/tests/dataset/img51.jpg
new file mode 100644
index 000000000..96794995e
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img51.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img53.jpg b/modules/deepface-master/tests/dataset/img53.jpg
new file mode 100644
index 000000000..1487a3208
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img53.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img54.jpg b/modules/deepface-master/tests/dataset/img54.jpg
new file mode 100644
index 000000000..f736571c0
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img54.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img55.jpg b/modules/deepface-master/tests/dataset/img55.jpg
new file mode 100644
index 000000000..9ed461241
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img55.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img56.jpg b/modules/deepface-master/tests/dataset/img56.jpg
new file mode 100644
index 000000000..79ac53f72
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img56.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img57.jpg b/modules/deepface-master/tests/dataset/img57.jpg
new file mode 100644
index 000000000..175fef4e9
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img57.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img58.jpg b/modules/deepface-master/tests/dataset/img58.jpg
new file mode 100644
index 000000000..dcee1b8c8
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img58.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img59.jpg b/modules/deepface-master/tests/dataset/img59.jpg
new file mode 100644
index 000000000..d3948736c
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img59.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img6.jpg b/modules/deepface-master/tests/dataset/img6.jpg
new file mode 100644
index 000000000..03dcd3e26
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img6.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img61.jpg b/modules/deepface-master/tests/dataset/img61.jpg
new file mode 100644
index 000000000..30c4939f8
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img61.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img62.jpg b/modules/deepface-master/tests/dataset/img62.jpg
new file mode 100644
index 000000000..74a7e982b
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img62.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img67.jpg b/modules/deepface-master/tests/dataset/img67.jpg
new file mode 100644
index 000000000..f09699d10
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img67.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img7.jpg b/modules/deepface-master/tests/dataset/img7.jpg
new file mode 100644
index 000000000..7cf10ccf0
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img7.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img8.jpg b/modules/deepface-master/tests/dataset/img8.jpg
new file mode 100644
index 000000000..53a55e988
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img8.jpg differ
diff --git a/modules/deepface-master/tests/dataset/img9.jpg b/modules/deepface-master/tests/dataset/img9.jpg
new file mode 100644
index 000000000..d4ea20fbe
Binary files /dev/null and b/modules/deepface-master/tests/dataset/img9.jpg differ
diff --git a/modules/deepface-master/tests/dataset/master.csv b/modules/deepface-master/tests/dataset/master.csv
new file mode 100644
index 000000000..5b05a5752
--- /dev/null
+++ b/modules/deepface-master/tests/dataset/master.csv
@@ -0,0 +1,301 @@
+file_x,file_y,Decision
+img20.jpg,img21.jpg,Yes
+img16.jpg,img17.jpg,Yes
+img3.jpg,img12.jpg,Yes
+img22.jpg,img23.jpg,Yes
+img24.jpg,img25.jpg,Yes
+img1.jpg,img2.jpg,Yes
+img1.jpg,img4.jpg,Yes
+img1.jpg,img5.jpg,Yes
+img1.jpg,img6.jpg,Yes
+img1.jpg,img7.jpg,Yes
+img1.jpg,img10.jpg,Yes
+img1.jpg,img11.jpg,Yes
+img2.jpg,img4.jpg,Yes
+img2.jpg,img5.jpg,Yes
+img2.jpg,img6.jpg,Yes
+img2.jpg,img7.jpg,Yes
+img2.jpg,img10.jpg,Yes
+img2.jpg,img11.jpg,Yes
+img4.jpg,img5.jpg,Yes
+img4.jpg,img6.jpg,Yes
+img4.jpg,img7.jpg,Yes
+img4.jpg,img10.jpg,Yes
+img4.jpg,img11.jpg,Yes
+img5.jpg,img6.jpg,Yes
+img5.jpg,img7.jpg,Yes
+img5.jpg,img10.jpg,Yes
+img5.jpg,img11.jpg,Yes
+img6.jpg,img7.jpg,Yes
+img6.jpg,img10.jpg,Yes
+img6.jpg,img11.jpg,Yes
+img7.jpg,img10.jpg,Yes
+img7.jpg,img11.jpg,Yes
+img10.jpg,img11.jpg,Yes
+img13.jpg,img14.jpg,Yes
+img13.jpg,img15.jpg,Yes
+img14.jpg,img15.jpg,Yes
+img18.jpg,img19.jpg,Yes
+img8.jpg,img9.jpg,Yes
+img20.jpg,img16.jpg,No
+img20.jpg,img17.jpg,No
+img21.jpg,img16.jpg,No
+img21.jpg,img17.jpg,No
+img20.jpg,img3.jpg,No
+img20.jpg,img12.jpg,No
+img21.jpg,img3.jpg,No
+img21.jpg,img12.jpg,No
+img20.jpg,img22.jpg,No
+img20.jpg,img23.jpg,No
+img21.jpg,img22.jpg,No
+img21.jpg,img23.jpg,No
+img20.jpg,img24.jpg,No
+img20.jpg,img25.jpg,No
+img21.jpg,img24.jpg,No
+img21.jpg,img25.jpg,No
+img20.jpg,img1.jpg,No
+img20.jpg,img2.jpg,No
+img20.jpg,img4.jpg,No
+img20.jpg,img5.jpg,No
+img20.jpg,img6.jpg,No
+img20.jpg,img7.jpg,No
+img20.jpg,img10.jpg,No
+img20.jpg,img11.jpg,No
+img21.jpg,img1.jpg,No
+img21.jpg,img2.jpg,No
+img21.jpg,img4.jpg,No
+img21.jpg,img5.jpg,No
+img21.jpg,img6.jpg,No
+img21.jpg,img7.jpg,No
+img21.jpg,img10.jpg,No
+img21.jpg,img11.jpg,No
+img20.jpg,img13.jpg,No
+img20.jpg,img14.jpg,No
+img20.jpg,img15.jpg,No
+img21.jpg,img13.jpg,No
+img21.jpg,img14.jpg,No
+img21.jpg,img15.jpg,No
+img20.jpg,img18.jpg,No
+img20.jpg,img19.jpg,No
+img21.jpg,img18.jpg,No
+img21.jpg,img19.jpg,No
+img20.jpg,img8.jpg,No
+img20.jpg,img9.jpg,No
+img21.jpg,img8.jpg,No
+img21.jpg,img9.jpg,No
+img16.jpg,img3.jpg,No
+img16.jpg,img12.jpg,No
+img17.jpg,img3.jpg,No
+img17.jpg,img12.jpg,No
+img16.jpg,img22.jpg,No
+img16.jpg,img23.jpg,No
+img17.jpg,img22.jpg,No
+img17.jpg,img23.jpg,No
+img16.jpg,img24.jpg,No
+img16.jpg,img25.jpg,No
+img17.jpg,img24.jpg,No
+img17.jpg,img25.jpg,No
+img16.jpg,img1.jpg,No
+img16.jpg,img2.jpg,No
+img16.jpg,img4.jpg,No
+img16.jpg,img5.jpg,No
+img16.jpg,img6.jpg,No
+img16.jpg,img7.jpg,No
+img16.jpg,img10.jpg,No
+img16.jpg,img11.jpg,No
+img17.jpg,img1.jpg,No
+img17.jpg,img2.jpg,No
+img17.jpg,img4.jpg,No
+img17.jpg,img5.jpg,No
+img17.jpg,img6.jpg,No
+img17.jpg,img7.jpg,No
+img17.jpg,img10.jpg,No
+img17.jpg,img11.jpg,No
+img16.jpg,img13.jpg,No
+img16.jpg,img14.jpg,No
+img16.jpg,img15.jpg,No
+img17.jpg,img13.jpg,No
+img17.jpg,img14.jpg,No
+img17.jpg,img15.jpg,No
+img16.jpg,img18.jpg,No
+img16.jpg,img19.jpg,No
+img17.jpg,img18.jpg,No
+img17.jpg,img19.jpg,No
+img16.jpg,img8.jpg,No
+img16.jpg,img9.jpg,No
+img17.jpg,img8.jpg,No
+img17.jpg,img9.jpg,No
+img3.jpg,img22.jpg,No
+img3.jpg,img23.jpg,No
+img12.jpg,img22.jpg,No
+img12.jpg,img23.jpg,No
+img3.jpg,img24.jpg,No
+img3.jpg,img25.jpg,No
+img12.jpg,img24.jpg,No
+img12.jpg,img25.jpg,No
+img3.jpg,img1.jpg,No
+img3.jpg,img2.jpg,No
+img3.jpg,img4.jpg,No
+img3.jpg,img5.jpg,No
+img3.jpg,img6.jpg,No
+img3.jpg,img7.jpg,No
+img3.jpg,img10.jpg,No
+img3.jpg,img11.jpg,No
+img12.jpg,img1.jpg,No
+img12.jpg,img2.jpg,No
+img12.jpg,img4.jpg,No
+img12.jpg,img5.jpg,No
+img12.jpg,img6.jpg,No
+img12.jpg,img7.jpg,No
+img12.jpg,img10.jpg,No
+img12.jpg,img11.jpg,No
+img3.jpg,img13.jpg,No
+img3.jpg,img14.jpg,No
+img3.jpg,img15.jpg,No
+img12.jpg,img13.jpg,No
+img12.jpg,img14.jpg,No
+img12.jpg,img15.jpg,No
+img3.jpg,img18.jpg,No
+img3.jpg,img19.jpg,No
+img12.jpg,img18.jpg,No
+img12.jpg,img19.jpg,No
+img3.jpg,img8.jpg,No
+img3.jpg,img9.jpg,No
+img12.jpg,img8.jpg,No
+img12.jpg,img9.jpg,No
+img22.jpg,img24.jpg,No
+img22.jpg,img25.jpg,No
+img23.jpg,img24.jpg,No
+img23.jpg,img25.jpg,No
+img22.jpg,img1.jpg,No
+img22.jpg,img2.jpg,No
+img22.jpg,img4.jpg,No
+img22.jpg,img5.jpg,No
+img22.jpg,img6.jpg,No
+img22.jpg,img7.jpg,No
+img22.jpg,img10.jpg,No
+img22.jpg,img11.jpg,No
+img23.jpg,img1.jpg,No
+img23.jpg,img2.jpg,No
+img23.jpg,img4.jpg,No
+img23.jpg,img5.jpg,No
+img23.jpg,img6.jpg,No
+img23.jpg,img7.jpg,No
+img23.jpg,img10.jpg,No
+img23.jpg,img11.jpg,No
+img22.jpg,img13.jpg,No
+img22.jpg,img14.jpg,No
+img22.jpg,img15.jpg,No
+img23.jpg,img13.jpg,No
+img23.jpg,img14.jpg,No
+img23.jpg,img15.jpg,No
+img22.jpg,img18.jpg,No
+img22.jpg,img19.jpg,No
+img23.jpg,img18.jpg,No
+img23.jpg,img19.jpg,No
+img22.jpg,img8.jpg,No
+img22.jpg,img9.jpg,No
+img23.jpg,img8.jpg,No
+img23.jpg,img9.jpg,No
+img24.jpg,img1.jpg,No
+img24.jpg,img2.jpg,No
+img24.jpg,img4.jpg,No
+img24.jpg,img5.jpg,No
+img24.jpg,img6.jpg,No
+img24.jpg,img7.jpg,No
+img24.jpg,img10.jpg,No
+img24.jpg,img11.jpg,No
+img25.jpg,img1.jpg,No
+img25.jpg,img2.jpg,No
+img25.jpg,img4.jpg,No
+img25.jpg,img5.jpg,No
+img25.jpg,img6.jpg,No
+img25.jpg,img7.jpg,No
+img25.jpg,img10.jpg,No
+img25.jpg,img11.jpg,No
+img24.jpg,img13.jpg,No
+img24.jpg,img14.jpg,No
+img24.jpg,img15.jpg,No
+img25.jpg,img13.jpg,No
+img25.jpg,img14.jpg,No
+img25.jpg,img15.jpg,No
+img24.jpg,img18.jpg,No
+img24.jpg,img19.jpg,No
+img25.jpg,img18.jpg,No
+img25.jpg,img19.jpg,No
+img24.jpg,img8.jpg,No
+img24.jpg,img9.jpg,No
+img25.jpg,img8.jpg,No
+img25.jpg,img9.jpg,No
+img1.jpg,img13.jpg,No
+img1.jpg,img14.jpg,No
+img1.jpg,img15.jpg,No
+img2.jpg,img13.jpg,No
+img2.jpg,img14.jpg,No
+img2.jpg,img15.jpg,No
+img4.jpg,img13.jpg,No
+img4.jpg,img14.jpg,No
+img4.jpg,img15.jpg,No
+img5.jpg,img13.jpg,No
+img5.jpg,img14.jpg,No
+img5.jpg,img15.jpg,No
+img6.jpg,img13.jpg,No
+img6.jpg,img14.jpg,No
+img6.jpg,img15.jpg,No
+img7.jpg,img13.jpg,No
+img7.jpg,img14.jpg,No
+img7.jpg,img15.jpg,No
+img10.jpg,img13.jpg,No
+img10.jpg,img14.jpg,No
+img10.jpg,img15.jpg,No
+img11.jpg,img13.jpg,No
+img11.jpg,img14.jpg,No
+img11.jpg,img15.jpg,No
+img1.jpg,img18.jpg,No
+img1.jpg,img19.jpg,No
+img2.jpg,img18.jpg,No
+img2.jpg,img19.jpg,No
+img4.jpg,img18.jpg,No
+img4.jpg,img19.jpg,No
+img5.jpg,img18.jpg,No
+img5.jpg,img19.jpg,No
+img6.jpg,img18.jpg,No
+img6.jpg,img19.jpg,No
+img7.jpg,img18.jpg,No
+img7.jpg,img19.jpg,No
+img10.jpg,img18.jpg,No
+img10.jpg,img19.jpg,No
+img11.jpg,img18.jpg,No
+img11.jpg,img19.jpg,No
+img1.jpg,img8.jpg,No
+img1.jpg,img9.jpg,No
+img2.jpg,img8.jpg,No
+img2.jpg,img9.jpg,No
+img4.jpg,img8.jpg,No
+img4.jpg,img9.jpg,No
+img5.jpg,img8.jpg,No
+img5.jpg,img9.jpg,No
+img6.jpg,img8.jpg,No
+img6.jpg,img9.jpg,No
+img7.jpg,img8.jpg,No
+img7.jpg,img9.jpg,No
+img10.jpg,img8.jpg,No
+img10.jpg,img9.jpg,No
+img11.jpg,img8.jpg,No
+img11.jpg,img9.jpg,No
+img13.jpg,img18.jpg,No
+img13.jpg,img19.jpg,No
+img14.jpg,img18.jpg,No
+img14.jpg,img19.jpg,No
+img15.jpg,img18.jpg,No
+img15.jpg,img19.jpg,No
+img13.jpg,img8.jpg,No
+img13.jpg,img9.jpg,No
+img14.jpg,img8.jpg,No
+img14.jpg,img9.jpg,No
+img15.jpg,img8.jpg,No
+img15.jpg,img9.jpg,No
+img18.jpg,img8.jpg,No
+img18.jpg,img9.jpg,No
+img19.jpg,img8.jpg,No
+img19.jpg,img9.jpg,No
\ No newline at end of file
diff --git a/modules/deepface-master/tests/face-recognition-how.py b/modules/deepface-master/tests/face-recognition-how.py
new file mode 100644
index 000000000..290323706
--- /dev/null
+++ b/modules/deepface-master/tests/face-recognition-how.py
@@ -0,0 +1,87 @@
+import matplotlib.pyplot as plt
+import numpy as np
+from deepface import DeepFace
+from deepface.commons import functions
+from deepface.commons.logger import Logger
+
+logger = Logger()
+
+# ----------------------------------------------
+# build face recognition model
+
+model_name = "VGG-Face"
+
+model = DeepFace.build_model(model_name=model_name)
+
+target_size = functions.find_target_size(model_name)
+
+logger.info(f"target_size: {target_size}")
+
+# ----------------------------------------------
+# load images and find embeddings
+
+img1 = DeepFace.extract_faces(img_path="dataset/img1.jpg", target_size=target_size)[0]["face"]
+img1 = np.expand_dims(img1, axis=0) # to (1, 224, 224, 3)
+img1_representation = model.predict(img1)[0, :]
+
+img2 = DeepFace.extract_faces(img_path="dataset/img3.jpg", target_size=target_size)[0]["face"]
+img2 = np.expand_dims(img2, axis=0)
+img2_representation = model.predict(img2)[0, :]
+
+# ----------------------------------------------
+# distance between two images
+
+distance_vector = np.square(img1_representation - img2_representation)
+logger.debug(distance_vector)
+
+distance = np.sqrt(distance_vector.sum())
+logger.info(f"Euclidean distance: {distance}")
+
+# ----------------------------------------------
+# expand vectors to be shown better in graph
+
+img1_graph = []
+img2_graph = []
+distance_graph = []
+
+for i in range(0, 200):
+ img1_graph.append(img1_representation)
+ img2_graph.append(img2_representation)
+ distance_graph.append(distance_vector)
+
+img1_graph = np.array(img1_graph)
+img2_graph = np.array(img2_graph)
+distance_graph = np.array(distance_graph)
+
+# ----------------------------------------------
+# plotting
+
+fig = plt.figure()
+
+ax1 = fig.add_subplot(3, 2, 1)
+plt.imshow(img1[0])
+plt.axis("off")
+
+ax2 = fig.add_subplot(3, 2, 2)
+im = plt.imshow(img1_graph, interpolation="nearest", cmap=plt.cm.ocean)
+plt.colorbar()
+
+ax3 = fig.add_subplot(3, 2, 3)
+plt.imshow(img2[0])
+plt.axis("off")
+
+ax4 = fig.add_subplot(3, 2, 4)
+im = plt.imshow(img2_graph, interpolation="nearest", cmap=plt.cm.ocean)
+plt.colorbar()
+
+ax5 = fig.add_subplot(3, 2, 5)
+plt.text(0.35, 0, f"Distance: {distance}")
+plt.axis("off")
+
+ax6 = fig.add_subplot(3, 2, 6)
+im = plt.imshow(distance_graph, interpolation="nearest", cmap=plt.cm.ocean)
+plt.colorbar()
+
+plt.show()
+
+# ----------------------------------------------
diff --git a/modules/deepface-master/tests/stream.py b/modules/deepface-master/tests/stream.py
new file mode 100644
index 000000000..6c041bfed
--- /dev/null
+++ b/modules/deepface-master/tests/stream.py
@@ -0,0 +1,8 @@
+from deepface import DeepFace
+
+DeepFace.stream("dataset") #opencv
+#DeepFace.stream("dataset", detector_backend = 'opencv')
+#DeepFace.stream("dataset", detector_backend = 'ssd')
+#DeepFace.stream("dataset", detector_backend = 'mtcnn')
+#DeepFace.stream("dataset", detector_backend = 'dlib')
+#DeepFace.stream("dataset", detector_backend = 'retinaface')
diff --git a/modules/deepface-master/tests/test_analyze.py b/modules/deepface-master/tests/test_analyze.py
new file mode 100644
index 000000000..d98ec0da1
--- /dev/null
+++ b/modules/deepface-master/tests/test_analyze.py
@@ -0,0 +1,133 @@
+import cv2
+from deepface import DeepFace
+from deepface.commons.logger import Logger
+
+logger = Logger("tests/test_analyze.py")
+
+detectors = ["opencv", "mtcnn"]
+
+
+def test_standard_analyze():
+ img = "dataset/img4.jpg"
+ demography_objs = DeepFace.analyze(img, silent=True)
+ for demography in demography_objs:
+ logger.debug(demography)
+ assert demography["age"] > 20 and demography["age"] < 40
+ assert demography["dominant_gender"] == "Woman"
+ logger.info("✅ test standard analyze done")
+
+
+def test_analyze_with_all_actions_as_tuple():
+ img = "dataset/img4.jpg"
+ demography_objs = DeepFace.analyze(
+ img, actions=("age", "gender", "race", "emotion"), silent=True
+ )
+
+ for demography in demography_objs:
+ logger.debug(f"Demography: {demography}")
+ age = demography["age"]
+ gender = demography["dominant_gender"]
+ race = demography["dominant_race"]
+ emotion = demography["dominant_emotion"]
+ logger.debug(f"Age: {age}")
+ logger.debug(f"Gender: {gender}")
+ logger.debug(f"Race: {race}")
+ logger.debug(f"Emotion: {emotion}")
+ assert demography.get("age") is not None
+ assert demography.get("dominant_gender") is not None
+ assert demography.get("dominant_race") is not None
+ assert demography.get("dominant_emotion") is not None
+
+ logger.info("✅ test analyze for all actions as tuple done")
+
+
+def test_analyze_with_all_actions_as_list():
+ img = "dataset/img4.jpg"
+ demography_objs = DeepFace.analyze(
+ img, actions=["age", "gender", "race", "emotion"], silent=True
+ )
+
+ for demography in demography_objs:
+ logger.debug(f"Demography: {demography}")
+ age = demography["age"]
+ gender = demography["dominant_gender"]
+ race = demography["dominant_race"]
+ emotion = demography["dominant_emotion"]
+ logger.debug(f"Age: {age}")
+ logger.debug(f"Gender: {gender}")
+ logger.debug(f"Race: {race}")
+ logger.debug(f"Emotion: {emotion}")
+ assert demography.get("age") is not None
+ assert demography.get("dominant_gender") is not None
+ assert demography.get("dominant_race") is not None
+ assert demography.get("dominant_emotion") is not None
+
+ logger.info("✅ test analyze for all actions as array done")
+
+
+def test_analyze_for_some_actions():
+ img = "dataset/img4.jpg"
+ demography_objs = DeepFace.analyze(img, ["age", "gender"], silent=True)
+
+ for demography in demography_objs:
+ age = demography["age"]
+ gender = demography["dominant_gender"]
+
+ logger.debug(f"Age: { age }")
+ logger.debug(f"Gender: {gender}")
+
+ assert demography.get("age") is not None
+ assert demography.get("dominant_gender") is not None
+
+ # these are not in actions
+ assert demography.get("dominant_race") is None
+ assert demography.get("dominant_emotion") is None
+
+ logger.info("✅ test analyze for some actions done")
+
+
+def test_analyze_for_preloaded_image():
+ img = cv2.imread("dataset/img1.jpg")
+ resp_objs = DeepFace.analyze(img, silent=True)
+ for resp_obj in resp_objs:
+ logger.debug(resp_obj)
+ assert resp_obj["age"] > 20 and resp_obj["age"] < 40
+ assert resp_obj["dominant_gender"] == "Woman"
+
+ logger.info("✅ test analyze for pre-loaded image done")
+
+
+def test_analyze_for_different_detectors():
+ img_paths = [
+ "dataset/img1.jpg",
+ "dataset/img5.jpg",
+ "dataset/img6.jpg",
+ "dataset/img8.jpg",
+ "dataset/img1.jpg",
+ "dataset/img2.jpg",
+ "dataset/img1.jpg",
+ "dataset/img2.jpg",
+ "dataset/img6.jpg",
+ "dataset/img6.jpg",
+ ]
+
+ for img_path in img_paths:
+ for detector in detectors:
+ results = DeepFace.analyze(
+ img_path, actions=("gender",), detector_backend=detector, enforce_detection=False
+ )
+ for result in results:
+ logger.debug(result)
+
+ # validate keys
+ assert "gender" in result.keys()
+ assert "dominant_gender" in result.keys() and result["dominant_gender"] in [
+ "Man",
+ "Woman",
+ ]
+
+ # validate probabilities
+ if result["dominant_gender"] == "Man":
+ assert result["gender"]["Man"] > result["gender"]["Woman"]
+ else:
+ assert result["gender"]["Man"] < result["gender"]["Woman"]
diff --git a/modules/deepface-master/tests/test_enforce_detection.py b/modules/deepface-master/tests/test_enforce_detection.py
new file mode 100644
index 000000000..74c4704be
--- /dev/null
+++ b/modules/deepface-master/tests/test_enforce_detection.py
@@ -0,0 +1,46 @@
+import pytest
+import numpy as np
+from deepface import DeepFace
+from deepface.commons.logger import Logger
+
+logger = Logger("tests/test_enforce_detection.py")
+
+
+def test_enabled_enforce_detection_for_non_facial_input():
+ black_img = np.zeros([224, 224, 3])
+
+ with pytest.raises(ValueError, match="Face could not be detected."):
+ DeepFace.represent(img_path=black_img)
+
+ with pytest.raises(ValueError, match="Face could not be detected."):
+ DeepFace.verify(img1_path=black_img, img2_path=black_img)
+
+ logger.info("✅ enabled enforce detection with non facial input tests done")
+
+
+def test_disabled_enforce_detection_for_non_facial_input_on_represent():
+ black_img = np.zeros([224, 224, 3])
+ objs = DeepFace.represent(img_path=black_img, enforce_detection=False)
+
+ assert isinstance(objs, list)
+ assert len(objs) > 0
+ assert isinstance(objs[0], dict)
+ assert "embedding" in objs[0].keys()
+ assert "facial_area" in objs[0].keys()
+ assert isinstance(objs[0]["facial_area"], dict)
+ assert "x" in objs[0]["facial_area"].keys()
+ assert "y" in objs[0]["facial_area"].keys()
+ assert "w" in objs[0]["facial_area"].keys()
+ assert "h" in objs[0]["facial_area"].keys()
+ assert isinstance(objs[0]["embedding"], list)
+ assert len(objs[0]["embedding"]) == 4096 # embedding of VGG-Face
+
+ logger.info("✅ disabled enforce detection with non facial input test for represent tests done")
+
+
+def test_disabled_enforce_detection_for_non_facial_input_on_verify():
+ black_img = np.zeros([224, 224, 3])
+ obj = DeepFace.verify(img1_path=black_img, img2_path=black_img, enforce_detection=False)
+ assert isinstance(obj, dict)
+
+ logger.info("✅ disabled enforce detection with non facial input test for verify tests done")
diff --git a/modules/deepface-master/tests/test_extract_faces.py b/modules/deepface-master/tests/test_extract_faces.py
new file mode 100644
index 000000000..ecdafecaf
--- /dev/null
+++ b/modules/deepface-master/tests/test_extract_faces.py
@@ -0,0 +1,24 @@
+from deepface import DeepFace
+from deepface.commons.logger import Logger
+
+logger = Logger("tests/test_extract_faces.py")
+
+
+def test_different_detectors():
+ detectors = ["opencv", "mtcnn"]
+
+ for detector in detectors:
+ img_objs = DeepFace.extract_faces(img_path="dataset/img11.jpg", detector_backend=detector)
+ for img_obj in img_objs:
+ assert "face" in img_obj.keys()
+ assert "facial_area" in img_obj.keys()
+ assert isinstance(img_obj["facial_area"], dict)
+ assert "x" in img_obj["facial_area"].keys()
+ assert "y" in img_obj["facial_area"].keys()
+ assert "w" in img_obj["facial_area"].keys()
+ assert "h" in img_obj["facial_area"].keys()
+ assert "confidence" in img_obj.keys()
+
+ img = img_obj["face"]
+ assert img.shape[0] > 0 and img.shape[1] > 0
+ logger.info(f"✅ extract_faces for {detector} backend test is done")
diff --git a/modules/deepface-master/tests/test_find.py b/modules/deepface-master/tests/test_find.py
new file mode 100644
index 000000000..e33b31841
--- /dev/null
+++ b/modules/deepface-master/tests/test_find.py
@@ -0,0 +1,73 @@
+import cv2
+import pandas as pd
+from deepface import DeepFace
+from deepface.commons import distance
+from deepface.commons.logger import Logger
+
+logger = Logger("tests/test_find.py")
+
+
+def test_find_with_exact_path():
+ img_path = "dataset/img1.jpg"
+ dfs = DeepFace.find(img_path=img_path, db_path="dataset", silent=True)
+ assert len(dfs) > 0
+ for df in dfs:
+ assert isinstance(df, pd.DataFrame)
+
+ # one is img1.jpg itself
+ identity_df = df[df["identity"] == img_path]
+ assert identity_df.shape[0] > 0
+
+ # validate reproducability
+ assert identity_df["VGG-Face_cosine"].values[0] == 0
+
+ df = df[df["identity"] != img_path]
+ logger.debug(df.head())
+ assert df.shape[0] > 0
+ logger.info("✅ test find for exact path done")
+
+
+def test_find_with_array_input():
+ img_path = "dataset/img1.jpg"
+ img1 = cv2.imread(img_path)
+ dfs = DeepFace.find(img1, db_path="dataset", silent=True)
+ assert len(dfs) > 0
+ for df in dfs:
+ assert isinstance(df, pd.DataFrame)
+
+ # one is img1.jpg itself
+ identity_df = df[df["identity"] == img_path]
+ assert identity_df.shape[0] > 0
+
+ # validate reproducability
+ assert identity_df["VGG-Face_cosine"].values[0] == 0
+
+ df = df[df["identity"] != img_path]
+ logger.debug(df.head())
+ assert df.shape[0] > 0
+
+ logger.info("✅ test find for array input done")
+
+
+def test_find_with_extracted_faces():
+ img_path = "dataset/img1.jpg"
+ face_objs = DeepFace.extract_faces(img_path)
+ img = face_objs[0]["face"]
+ dfs = DeepFace.find(img, db_path="dataset", detector_backend="skip", silent=True)
+ assert len(dfs) > 0
+ for df in dfs:
+ assert isinstance(df, pd.DataFrame)
+
+ # one is img1.jpg itself
+ identity_df = df[df["identity"] == img_path]
+ assert identity_df.shape[0] > 0
+
+ # validate reproducability
+ assert identity_df["VGG-Face_cosine"].values[0] < (
+ distance.findThreshold(model_name="VGG-Face", distance_metric="cosine")
+ )
+
+ df = df[df["identity"] != img_path]
+ logger.debug(df.head())
+ assert df.shape[0] > 0
+ logger.info("✅ test find for extracted face input done")
diff --git a/modules/deepface-master/tests/test_represent.py b/modules/deepface-master/tests/test_represent.py
new file mode 100644
index 000000000..44412f363
--- /dev/null
+++ b/modules/deepface-master/tests/test_represent.py
@@ -0,0 +1,48 @@
+import cv2
+from deepface import DeepFace
+from deepface.commons.logger import Logger
+
+logger = Logger("tests/test_represent.py")
+
+
+def test_standard_represent():
+ img_path = "dataset/img1.jpg"
+ embedding_objs = DeepFace.represent(img_path)
+ for embedding_obj in embedding_objs:
+ embedding = embedding_obj["embedding"]
+ logger.debug(f"Function returned {len(embedding)} dimensional vector")
+ assert len(embedding) == 4096
+ logger.info("✅ test standard represent function done")
+
+
+def test_represent_for_skipped_detector_backend_with_image_path():
+ face_img = "dataset/img5.jpg"
+ img_objs = DeepFace.represent(img_path=face_img, detector_backend="skip")
+ assert len(img_objs) >= 1
+ img_obj = img_objs[0]
+ assert "embedding" in img_obj.keys()
+ assert "facial_area" in img_obj.keys()
+ assert isinstance(img_obj["facial_area"], dict)
+ assert "x" in img_obj["facial_area"].keys()
+ assert "y" in img_obj["facial_area"].keys()
+ assert "w" in img_obj["facial_area"].keys()
+ assert "h" in img_obj["facial_area"].keys()
+ assert "face_confidence" in img_obj.keys()
+ logger.info("✅ test represent function for skipped detector and image path input backend done")
+
+
+def test_represent_for_skipped_detector_backend_with_preloaded_image():
+ face_img = "dataset/img5.jpg"
+ img = cv2.imread(face_img)
+ img_objs = DeepFace.represent(img_path=img, detector_backend="skip")
+ assert len(img_objs) >= 1
+ img_obj = img_objs[0]
+ assert "embedding" in img_obj.keys()
+ assert "facial_area" in img_obj.keys()
+ assert isinstance(img_obj["facial_area"], dict)
+ assert "x" in img_obj["facial_area"].keys()
+ assert "y" in img_obj["facial_area"].keys()
+ assert "w" in img_obj["facial_area"].keys()
+ assert "h" in img_obj["facial_area"].keys()
+ assert "face_confidence" in img_obj.keys()
+ logger.info("✅ test represent function for skipped detector and preloaded image done")
diff --git a/modules/deepface-master/tests/test_verify.py b/modules/deepface-master/tests/test_verify.py
new file mode 100644
index 000000000..5d135417c
--- /dev/null
+++ b/modules/deepface-master/tests/test_verify.py
@@ -0,0 +1,102 @@
+import cv2
+from deepface import DeepFace
+from deepface.commons.logger import Logger
+
+logger = Logger("tests/test_facial_recognition_models.py")
+
+
+models = ["VGG-Face", "Facenet", "Facenet512", "ArcFace"]
+metrics = ["cosine", "euclidean", "euclidean_l2"]
+detectors = ["opencv", "mtcnn"]
+
+
+def test_different_facial_recognition_models():
+ dataset = [
+ ["dataset/img1.jpg", "dataset/img2.jpg", True],
+ ["dataset/img5.jpg", "dataset/img6.jpg", True],
+ ["dataset/img6.jpg", "dataset/img7.jpg", True],
+ ["dataset/img8.jpg", "dataset/img9.jpg", True],
+ ["dataset/img1.jpg", "dataset/img11.jpg", True],
+ ["dataset/img2.jpg", "dataset/img11.jpg", True],
+ ["dataset/img1.jpg", "dataset/img3.jpg", False],
+ ["dataset/img2.jpg", "dataset/img3.jpg", False],
+ ["dataset/img6.jpg", "dataset/img8.jpg", False],
+ ["dataset/img6.jpg", "dataset/img9.jpg", False],
+ ]
+
+ expected_coverage = 97.53 # human level accuracy on LFW
+ successful_tests = 0
+ unsuccessful_tests = 0
+ for model in models:
+ for metric in metrics:
+ for instance in dataset:
+ img1 = instance[0]
+ img2 = instance[1]
+ result = instance[2]
+
+ resp_obj = DeepFace.verify(img1, img2, model_name=model, distance_metric=metric)
+
+ prediction = resp_obj["verified"]
+ distance = round(resp_obj["distance"], 2)
+ threshold = resp_obj["threshold"]
+
+ if prediction is result:
+ test_result_label = "✅"
+ successful_tests += 1
+ else:
+ test_result_label = "❌"
+ unsuccessful_tests += 1
+
+ if prediction is True:
+ classified_label = "same person"
+ else:
+ classified_label = "different persons"
+
+ img1_alias = img1.split("/", maxsplit=1)[-1]
+ img2_alias = img2.split("/", maxsplit=1)[-1]
+
+ logger.debug(
+ f"{test_result_label} Pair {img1_alias}-{img2_alias}"
+ f" is {classified_label} based on {model}-{metric}"
+ f" (Distance: {distance}, Threshold: {threshold})",
+ )
+
+ coverage_score = (100 * successful_tests) / (successful_tests + unsuccessful_tests)
+ assert (
+ coverage_score > expected_coverage
+ ), f"⛔ facial recognition models test failed with {coverage_score} score"
+
+ logger.info(f"✅ facial recognition models test passed with {coverage_score}")
+
+
+def test_different_face_detectors():
+ for detector in detectors:
+ res = DeepFace.verify("dataset/img1.jpg", "dataset/img2.jpg", detector_backend=detector)
+ assert isinstance(res, dict)
+ assert "verified" in res.keys()
+ assert res["verified"] in [True, False]
+ assert "distance" in res.keys()
+ assert "threshold" in res.keys()
+ assert "model" in res.keys()
+ assert "detector_backend" in res.keys()
+ assert "similarity_metric" in res.keys()
+ assert "facial_areas" in res.keys()
+ assert "img1" in res["facial_areas"].keys()
+ assert "img2" in res["facial_areas"].keys()
+ assert "x" in res["facial_areas"]["img1"].keys()
+ assert "y" in res["facial_areas"]["img1"].keys()
+ assert "w" in res["facial_areas"]["img1"].keys()
+ assert "h" in res["facial_areas"]["img1"].keys()
+ assert "x" in res["facial_areas"]["img2"].keys()
+ assert "y" in res["facial_areas"]["img2"].keys()
+ assert "w" in res["facial_areas"]["img2"].keys()
+ assert "h" in res["facial_areas"]["img2"].keys()
+ logger.info(f"✅ test verify for {detector} backend done")
+
+
+def test_verify_for_preloaded_image():
+ img1 = cv2.imread("dataset/img1.jpg")
+ img2 = cv2.imread("dataset/img2.jpg")
+ res = DeepFace.verify(img1, img2)
+ assert res["verified"] is True
+ logger.info("✅ test verify for pre-loaded image done")
diff --git a/modules/deepface-master/tests/visual-test.py b/modules/deepface-master/tests/visual-test.py
new file mode 100644
index 000000000..f6bb6b62c
--- /dev/null
+++ b/modules/deepface-master/tests/visual-test.py
@@ -0,0 +1,53 @@
+import matplotlib.pyplot as plt
+from deepface import DeepFace
+from deepface.commons.logger import Logger
+
+logger = Logger()
+
+model_names = [
+ "VGG-Face",
+ "Facenet",
+ "Facenet512",
+ "OpenFace",
+ "DeepFace",
+ "DeepID",
+ "Dlib",
+ "ArcFace",
+ "SFace",
+]
+detector_backends = ["opencv", "ssd", "dlib", "mtcnn", "retinaface"]
+
+# verification
+for model_name in model_names:
+ obj = DeepFace.verify(
+ img1_path="dataset/img1.jpg", img2_path="dataset/img2.jpg", model_name=model_name
+ )
+ logger.info(obj)
+ logger.info("---------------------")
+
+# represent
+for model_name in model_names:
+ embedding_objs = DeepFace.represent(img_path="dataset/img1.jpg", model_name=model_name)
+ for embedding_obj in embedding_objs:
+ embedding = embedding_obj["embedding"]
+ logger.info(f"{model_name} produced {len(embedding)}D vector")
+
+# find
+dfs = DeepFace.find(
+ img_path="dataset/img1.jpg", db_path="dataset", model_name="Facenet", detector_backend="mtcnn"
+)
+for df in dfs:
+ logger.info(df)
+
+# extract faces
+for detector_backend in detector_backends:
+ face_objs = DeepFace.extract_faces(
+ img_path="dataset/img1.jpg", detector_backend=detector_backend
+ )
+ for face_obj in face_objs:
+ face = face_obj["face"]
+ logger.info(detector_backend)
+ plt.imshow(face)
+ plt.axis("off")
+ plt.show()
+ logger.info("-----------")